ATI RADEON 9000
Часть 1: RADEON 9000 Pro 64MB
Установка и драйверы
Рассмотрим конфигурацию тестового стенда, на котором проводились испытания карт:
- Компьютер на базе Athlon XP:
- процессор AMD Athlon XP 2000+;
- системная плата Soltek 75DRV5 (VIA KT333);
- оперативная память 512 MB DDR SDRAM PC2700;
- жесткий диск Fujitsu 20GB;
- операционная система Windows XP.
На стенде использовались мониторы
При тестировании применялись драйверы от ATI Catalyst версии 6.118. VSync отключен.
Для сравнительного анализа приведены результаты уже знакомых читателям видеокарт:
- Leadtek WinFast A170T (GeForce4 MX 440, 270/200 (400) МГц, 64 МБ);
- ATI RADEON 7500 (290/230 (460) МГц, 64 МБ);
- ATI RADEON 8500LE (250/250 (500) МГц, 64 МБ);.
Настройки драйверов
Как уже известно, настройки драйвера Catalyst существенно отличаются от ранее привычных читателям панелей:


При тестировании наша цель — показ работы карты при максимально возможном качестве (без активизации дополнительных функций, таких, как анизотропия), поэтому все настройки выставляются соответствующим образом. Замечу, что в Direct3D условие максимальной детализации текстур идет по умолчанию.
Результаты тестов
2D-графика
Я сразу скажу, что мы тестировали опытный образец, поэтому оценка качества 2D будет очень и очень условной. В целом замечу, что нарекания в высоких разрешениях были, в частности, в 1280х1024 при 100Гц замыливание уже очевидно.
Однако добавлю, что оценка 2D-качества есть вещь субъективная. Подобные платы будут выпускать много фирм, поэтому качество будет зависеть от конкретного экземпляра, а также от связки карта-монитор, которые могут по-прежнему играть огромную роль, прежде всего, качество монитора и кабеля.
3D-графика, MS DirectX 8.1 SDK — предельные тесты
Для тестирования различных предельных характеристик чипов мы использовали модифицированные (для большего удобства и контроля) примеры из последней версии DirectX SDK (8.1, релиз). Без лишних преамбул перейдем к уже хорошо знакомым нашим постоянным читателям тестам:
Optimized Mesh
Этот тест призван выяснить практический предел пропускной способности
ускорителя по треугольникам. Для этого используется несколько одновременно
выводимых в небольшом окне моделей, каждая из которых состоит из 50
тысяч треугольников. Текстурирование отсутствует. Размеры моделей минимальны
— каждый треугольник не превышает одного пиксела. Хочется сразу отметить,
что результат этого теста, разумеется, останется недостижим для реальных
приложений, где размеры треугольников значительны, присутствуют текстуры
и освещение. Приведем результаты этого теста для трех методов отрисовки
— оптимизированной для оптимальной скорости вывода (в том числе, с учетом
размера внутреннего кэша вершин на чипе) модели — Optimized, неоптимизированной
исходной модели — Unoptimized и той же неоптимизированной модели, выводимой
в виде одного Triangle Strip — Strip:

В случае полностью оптимизированной модели, когда влияние подсистемы памяти минимально, мы видим, что у RADEON 9000 более слабый Hardware T&L блок, и это сказывается на результатах данного теста не лучшим образом. Когда используется 1 Strip, то в этом типе представления моделей (который достаточно популярен в играх) RADEON 9000 практически идет вровень с 8500, отсюда вывод, что геометрические кэши очереди RV250 сделаны столь же добротно, а вот кеш с произвольным доступом слабее (меньше), чем у RADEON 8500. Что ж, не забываем, что это бюджетная версия чипа, и, в первую очередь, имеет смысл экономить транзисторы кэша, которых в любом чипе очень много.
Производительность блока вершинного шейдера
Этот тест позволяет определить предельную производительность блока вершинных шейдеров. Выполняется достаточно сложный шейдер, вычисляющий как видовые преобразования, так и геометрические функции. Тест проводится в минимальном разрешении, дабы минимизировать влияние закраски:
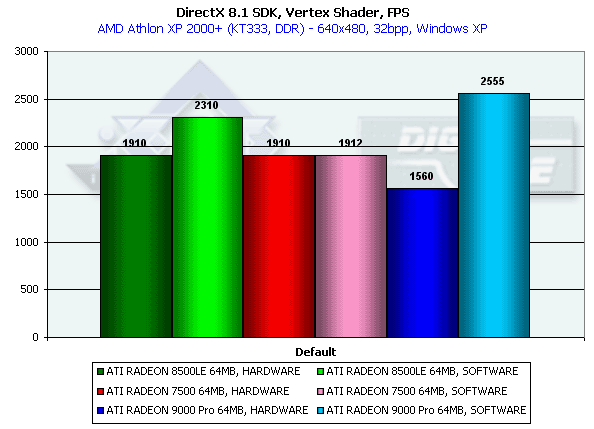
Как мы видим, при работе по вершинным шейдерам (в отличие от предыдущего теста) производительность эквивалентна RADEON 8500. Это уже радует. Кроме того, давайте обратим внимание на высокий результат в режиме программной эмуляции. Он говорит только об одном — механизм передачи геометрических данных от процессора к ускорителю (традиционно более слабое место у ATI по сравнению с NVIDIA) был существенно улучшен. Видимо, наконец-то должным образом поддержана технология FastWrites или близкая ей по смыслу.
Вершинный матричный блендинг
Эта возможность T&L используется для правдоподобной анимации и скиннинга моделей. Мы протестировали блендинг с использованием двух матриц как в жестком "аппаратном" варианте, так и с использованием вершинного шейдера, выполняющего ту же функцию. Кроме того, мы, как обычно, "подстраховались" результатами, полученными в режиме программной эмуляции T&L:

На сей раз сохраняется печальная тенденция, связанная со всеми вопросами работы HW T&L. Вновь результат заметно ниже предшественников.
EMBM рельеф
В этом тесте мы измеряем производительность, а точнее, ее падение, возникающее
при использовании наложения карт отражения (Environment) и рельефа на
основе карт отражения (EMBM — Environment Bump). Для тестирования использовалось
разрешение 1280*1024 — т.к. именно в нем различия между картами и разными
режимами текстурирования выражены наиболее резко:

Мы видим, что объект исследования EMBM исполняет даже чуть лучше, чем это делает RADEON 8500, с остальным ситуация практически равновесная.
Производительность пиксельных шейдеров
Мы вновь использовали модифицированный пример MFCPixelShader, измерив производительность карт в высоком разрешении при выполнении 5 различных по сложности шейдеров, для билинейно фильтрованных текстур:

Налицо заметное преимущество пиксельных конвейеров нового чипа при исполнении пиксельных шейдеров, причем оно несколько выше разницы частот — пиксельный конвейер явно был оптимизирован. При этом, преимущество растет с ростом сложности шейдера — видимо, число исполняющих блоков для стадий было все же увеличено.
Итак, подведем первый промежуточный итог. Несмотря на урезанное вдвое число текстурных блоков и почти вдвое менее производительный на задачах старого фиксированного T&L геометрический блок, бюджетный чип показывает прекрасные результаты именно в новых, использующих шейдеры, приложениях. Вкупе с невысокой ценой это может стать существенным преимуществом для выбирающего покупателя, видимо, ATI достаточно верно подошла к вопросу "на чем следует экономить, а на чем не следует", отдав предпочтение современным и будущим приложениям.
3D-графика, 3DMark2001 SE — синтетические тесты
Подчеркну, что все замеры по всем 3D-тестам проводились в 32-битной глубине цвета.
Скорость закраски

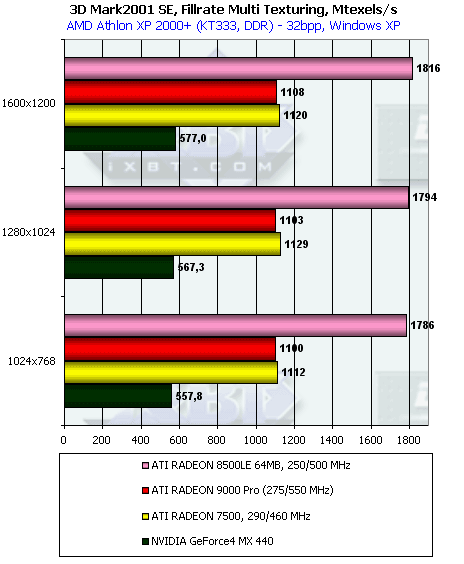
Как видим, при использовании одной текстуры (Single Texturing) сказываются одноканальный контроллер памяти и меньшие кэши. А вот при мультитекстурировании очевидно наличие только одного текстурного блока на конвейер. Падение производительности относительно RADEON 8500 не вдвое, а почти вдвое вызвано сохраненным умением накапливать по 6 текстур за проход. Однако теперь уже жертвовать придется 5-ю тактами, а не двумя, как в RADEON 8500.
Сцена с большим количеством полигонов
На этом тесте особое внимание следует уделить минимальному разрешению — именно там зависимость от закраски практически нивелируется:


И снова перед нами явно более слабый блок HW T&L у RADEON 9000. Мы видим, что он ослаблен почти в 2 раза по сравнению с RADEON 8500. Впрочем, мы уже выше пришли к выводу, что это вполне логично из-за компромисса между поддержкой старого блока T&L и нового — на шейдерах. Но даже в этом случае производительность подблока освещенности выше, чем у RADEON 7500.
Рельефное текстурирование
Посмотрим на результаты синтетической EMBM сцены:
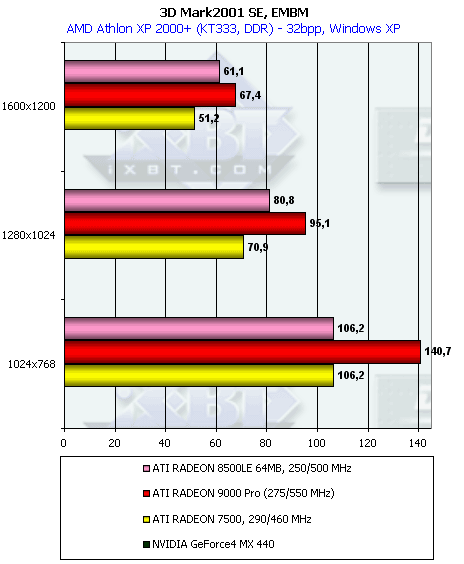
Преимущество у RADEON 9000 вызвано не только более высокой тактовой частотой, но и оптимизацией работы с EMBM у нового процессора. А теперь DP3 рельеф:

Ну а тут все как и ожидалось — при схожей конфигурации конвейерной структуры результаты почти идентичны.
Вершинные шейдеры

Мы видим, что вершинные шейдеры исполняются медленнее, чем у RADEON 8500, но не настолько, чтобы говорить о двукратном падении. По всей видимости, конструкторы сознательно сэкономили на эмуляции T&L, которая и на RADEON 8500 выполнялась с привлечением некоторых специфических средств, а теперь просто переложена на плечи обычного вершинного шейдера. Как мы увидим дальше, производительность исполнения типичных шейдеров приложений (извне) пострадала не так сильно.
Пиксельный шейдер
А тут RADEON 9000 обогнал соперника в лице RADEON 8500, правда, в
пределах разницы в частотах ядер. А вообще, тут все неплохо: уменьшенное
число текстурников компенсируется в сложной задаче пиксельных шейдеров
увеличенной частотой чипа. К тому же, тут RV250 напрочь убивает GeForce4
MX, ведь последняя не умеет вообще работать с пиксельными шейдерами.
Картина очень похожая, а отставание RADEON 9000 уже связано с более сложной сценой и мультитекстурированием, расплата за которое у него более высокая.
Спрайты

Этот тест зависит в первую очередь от геометрической производительности, а во вторую — от умения закрашивать спрайты оптимизированным методом. Второе — в наличии, а вот первое хромает и здорово — отставание почти двукратное (как мы уже выяснили из теста на геометрию). В итоге полуторакратное падение по сравнению с RADEON 8500. Однако посмотрите на результаты RADEON 7500, эмулирующего спрайты двумя треугольниками, и вы согласитесь, что прогресс не так уж и плох.
Итак, подведем еще один промежуточный итог. Который, впрочем, почти
не отличается от вывода, который мы сделали, рассмотрев предельные тесты
из SDK. Мы видим более слабый классический блок HW T&L, но зато
сильно продвинутый новый блок шейдеров, прежде всего, пиксельных. По
мере выхода игр, все более активно использующих эти техники, преимущество
у RADEON 9000 будет расти. Правда, чип имеет не 8, а всего лишь 4 текстурных
блока, что сказывается на общей производительности, но, согласитесь,
что для карты ценой около $100, это простительно.
| 18 июля 2002 г. |

|
| Дополнительно |
|





