

Содержание
- Введение
- Titan X — высокопроизводительное решение на основе топового чипа Maxwell
- DIGITS и DIGITS DevBox — решения для построения и обучения нейросетей
- Свежие данные о Pascal — следующем поколении графической архитектуры Nvidia
- Ключевые выступления Google и Baidu по теме deep learning
- Перспективы применения платформы Drive PX в автомобилях, в том числе автономных
- Анонсы профессиональной графики: Iray 2015, новые модели Quadro и обновление VCA
- Бонус: экскурсия по самым интересным помещениям Nvidia в Санта-Кларе
- Выводы
Введение
Компания Nvidia уже давно старается пробиться на разные рынки, открывая для себя всё новые ниши и не ограничиваясь исключительно традиционным для них рынком игровых графических процессоров, который переживает не самые лучшие времена. Игровые ПК в последние годы в относительном застое, и причин этому множество: как проблемы с освоением новых техпроцессов, не позволяющие сделать качественный скачок в производстве новых GPU, так и засилье мультиплатформенных игровых проектов, не слишком требовательных к мощности графических процессоров.
Nvidia уже предлагает свою продукцию в сфере профессиональных графических решений, на рынках процессоров для высокопроизводительных вычислений, компактных игровых устройств и автомобильных систем. Интерес к вычислительным применениям графических процессоров за последние несколько лет вырос в сотни раз, и уже сейчас GPU производства компании Nvidia успешно применяются во многих сферах.
Ещё несколько лет назад компания организовала собственное крупное мероприятие, посвященное различным аспектам использования графических процессоров в широком наборе задач — GPU Technology Conference. Прошедшая в конце марта очередная ежегодная конференция компании Nvidia стала уже шестой, и она традиционно проходит в городе Сан-Хосе, в штате Калифорния, США. С тех пор конференция стала главным мероприятием года для Nvidia, и именно на нем делаются все самые крупные анонсы компании и раскрываются некоторые планы на будущее.

«Графически-вычислительная» конференция GTC с каждым годом привлекает все большее внимание со стороны исследователей и ученых из различных учебных заведений и компаний, собирая сотни компаний и тысячи участников, так или иначе связанных с темой использования графических процессоров.
В этом году число участников уже превысило 4000 человек (в прошлом году их было 3500), и они приехали в Сан-Хосе со всего мира для того, чтобы принять участие в этом интереснейшем мероприятии: выступить со своими докладами, послушать других участников, познакомиться и пообщаться с единомышленниками и конкурентами. Польза участия в GTC связана не только с ключевыми выступлениями лидеров индустрии, но и с сотнями интереснейших сессий по разной тематике — с кучей полезной информации о том, как графические процессоры Nvidia облегчают выполнение задач разработчиков в разных сферах.
Titan X — высокопроизводительное решение на основе топового чипа Maxwell
Выступления первого дня конференции всегда включают присутствие на сцене лидера компании — Дженсена Хуанга, который рассказывает о последних достижениях Nvidia в деле применения GPU в самых различных задачах, и практически ни один год не обходился без громких анонсов. Поэтому именно первое ключевое выступление главы компании вызывает у публики неподдельный интерес.

Начало GTC всегда связано с подведением итогов года, прошедшего с предыдущей конференции, и для Nvidia он был достаточно успешным. Компания добилась определённых успехов (в том числе и финансовых) для множества своих подразделений: Geforce, Quadro, Tesla и Tegra (по крайней мере, в автомобилях).

Основной темой нынешней конференции стало так называемое глубокое обучение (deep learning) — быстрорастущий в последние годы набор алгоритмов машинного обучения, тесно связанный с реализацией искусственного интеллекта. Nvidia в лице Дженсена считает глубокое обучение тем локомотивом, который способен продвинуть индустрию по многим направлениям, от автономных автомобилей до применения в медицинских исследованиях.

По ходу своего ключевого выступления, перед тысячами участников GTC, Дженсен представил несколько новых программных и аппаратных технологий, которые принесут лёгкость использования и высокую производительность в сферу глубокого машинного обучения. И началось всё с мощнейшего графического процессора Titan X.

Titan X — это мощнейший GPU игровой серии Geforce, который основан на второй версии графической архитектуры Maxwell и отлично подходит для применения в сфере deep learning. Анонс Titan X на GTC получился несколько скомканным, так как решение уже было фактически анонсировано и показано на конференции игровых разработчиков Game Developers Conference в Сан-Франциско несколькими днями ранее. Где также был показан демонстрационный ролик, показывающий возможности игрового движка Unreal Engine 4:

На данный момент, Titan X является самым мощным решением компании Nvidia и он вдвое энергоэффективнее аналогичных GPU из предыдущих поколений. Содержащиеся в новом GPU потоковые процессоры в количестве 3072 штук обеспечивают производительность вычислений с одинарной точностью до 7 терафлопов, а объём локальной видеопамяти у новинки достигает впечатляющих 12 гигабайт.
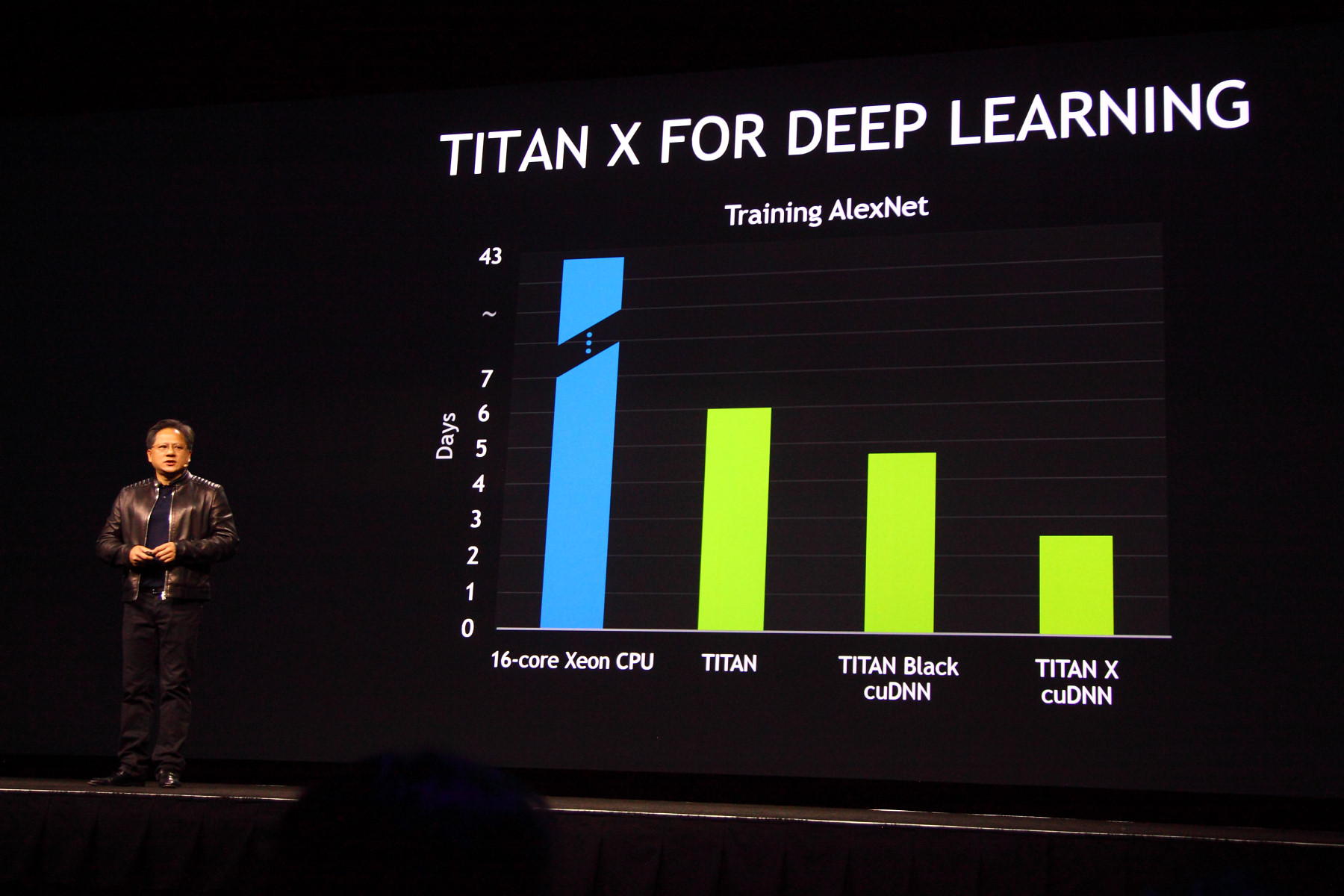
Кроме объёма, память Titan X обладает ещё и высокой пропускной способностью — более 336 ГБ/с, что также очень важно в задачах по тренировке нейросетей при deep learning. Так, при помощи стандартной модели AlexNet, новый Titan X достиг показателя в менее чем три дня для тренировки модели при помощи 1.2 миллионов изображений из набора ImageNet — сравните это с более чем 40 днями для 16-ядерного CPU или шестью днями для первого Titan.

Не очень понятно, зачем Nvidia указала на слайде столь смешную производительность для вычислений с двойной точностью — ведь подобным показателем погордиться вряд ли получится... Впрочем, из песни слов не выкинешь, что есть, то есть. Зато на GTC наконец-то стала известна розничная цена решения для рынка США. Начиная со дня анонса, Geforce GTX Titan X поступил в продажу на североамериканском рынке по цене $999. Кстати, обзор этой видеокарты вы уже можете прочитать на нашем сайте.
DIGITS и DIGITS DevBox — решения для построения и обучения нейросетей
В ходе своего главного выступления, Дженсен анонсировал также и DIGITS и DIGITS DevBox — новые возможности для простого и быстрого построения глубоких нейросетей, которые предлагает Nvidia. Использование нейросетей при тренировке машинных алгоритмов для самостоятельного обучения, классификации и распознавания объектов, является непростой и требующей серьёзной работы задачей. Эта тема сейчас является одной из самых обсуждаемых, и GPU-ускоренный deep learning используется в работе множества компаний:


Представленная на конференции система тренировки глубокого обучения DIGITS, использующая графические процессоры Nvidia, даёт пользователям всё необходимое для того, чтобы построить глубокие нейросети максимально простым и быстрым способом.
Данное программное средство доступно для скачивания с сайта компании Nvidia. Это первая подобная графическая система всё-в-одном для разработки, тренировки и использования глубоких нейросетей, предназначенных для классификации изображений.

Система DIGITS даёт пользователю простые возможности для установки, конфигурации и тренировки нейросетей, максимально облегчая работу исследователей и ускоряя получение результатов. Подготовка и тренировка DIGITS проста и имеет интуитивно-понятный интерфейс и возможности по управлению. Она поддерживает GPU-ускоренную версию Caffe — популярного фреймворка, используемого многими учеными и исследователями при постройке нейросетей.
Более того, чисто программными средствами дело не ограничивается. Глава Nvidia представил на GTC и специальный высокопроизводительный аппаратный комплекс для совместного использования с DIGITS — DIGITS DevBox. Это специализированная платформа для ускорения исследования задач deep learning.

DIGITS DevBox содержит максимально оптимизированное аппаратное обеспечение, дающее высокую производительность и эффективность в задачах глубокого обучения, начиная с четырёх графических процессоров Titan X и заканчивая подсистемами памяти и ввода-вывода данных. Каждый из четырёх GPU Titan X обеспечивает по 7 терафлопс вычислений одинарной точности, имеет пропускную способность в 336.5 ГБ/с для 12 гигабайт памяти.


Система основана на материнской плате Asus X99, имеющей восемь слотов PCI-E и высокопроизводительном процессоре Intel Core i7, может иметь до 64 ГБ памяти типа DDR4, до трёх 3 ТБ дисков в RAID 5 массиве плюс SSD. Установленное на систему программное обеспечение Nvidia DIGITS включает стандартную операционную систему Ubuntu 14.04 с установленным ПО: популярными фреймворками deep learning (Caffe, Torch, Theano), cuDNN 2.0 (ускоренная на GPU библиотека deep learning) и CUDA 7.0. В общем, всё необходимое для работы исследователей и учёных в области deep learning установлено в системе и готово к работе.
Мощность системы питания обеспечивается до 1500 Вт, то есть эту систему можно считать обычным настольным решением, которое присоединяется к типичной розетке, не требуя специальных линий питания. Решение тихое, прохладное, энергоэффективное, да ещё и выглядит неплохо. Стоимость готового решения Nvidia для deep learning составляет $15000.

Уже первые оценки от применения DIGITS DevBox показывают почти четырёхкратное увеличение производительности по сравнению с одиночным графическим адаптером Titan X в ключевых тестах deep learning. Так, тренировка AlexNet может быть закончена всего лишь за 13 часов при помощи DIGITS DevBox, по сравнению с более чем двумя днями на лучшем из GPU, не говоря уже о полутора месяцах расчётов при CPU-системе.
Свежие данные о Pascal — следующем поколении графической архитектуры Nvidia
Глава Nvidia традиционно рассказал немного нового и о следующем поколении графической архитектуры — Pascal. Ничего особенно интересного о ней мы не услышали, а о самом существовании проекта было давно известно. Pascal — это следующая архитектура GPU компании, которая ожидается к выходу в 2016 году. Кроме всего прочего, от новинки ожидают до 10-кратного увеличения производительности в задачах deep learning по сравнению с текущими чипами Maxwell.

По ходу своего выступления Дженсен раскрыл некоторые детали Pascal и показал обновленный план по выпуску графических решений в ближайшие годы, выразив надежду, что новая архитектура после более чем трёхлетней разработки проявит себя с положительной стороны. Так как основной темой нынешней GTC является deep learning (использование самообучающихся нейросетей), то рассказали о том, как это сказалось на дизайне Pascal, анонсированном на прошлой конференции.
Графические решения архитектуры Pascal будут иметь три основных достоинства, связанных с подобным применением, что вызовет более точное и быстрое обучение сложных и глубоких нейросетей. Вместе с максимальным объёмом памяти в 32 гигабайта (что почти втрое больше, чем у анонсированного только что Titan X), выделяется ещё одна модификация — Pascal поддерживает вычисления смешанной точности. Также в GPU следующей архитектуры будет применяться 3D-память (stacked DRAM), которая в 5 раз быстрее в приложениях deep learning. Также необходимо помнить и о поддержке высокоскоростных межчиповых соединений NVLink, объединяющих два или более GPU. Всё вместе это в результате должно дать 10-кратный прирост в указанных задачах.

Вычисления смешанной точности в Pascal используются для двойного ускорения расчётов, которым достаточно 16-битной «половинной» точности вычислений — они вдвое быстрее, чем привычные FP32 (одинарная точность). Увеличенная производительность таких вычислений даст прирост скорости классификации и свёртки (convolution) — двух важных шагах deep learning, при сохранении достаточной точности вычислений.
Применение многоэтажной (stacked) 3D-памяти позволит увеличить скорость доступа к данным и одновременно с этим улучшить энергоэффективность. Это очень важно, так как именно ограничения ПСП зачастую определяют и конечную скорость сложных параллельных расчётов, и внедрение 3D-памяти обеспечит трёхкратный рост ПСП при таком же увеличении объёма буфера кадра (объема видеопамяти) — это позволит исследователям строить нейросети большего размера и ускорить некоторые из частей тренировки машинного алгоритма при глубоком обучении.
Как уже было известно, графические процессоры архитектуры Pascal будут иметь микросхемы памяти поставленные друг на друга и на GPU, вместо того, чтобы быть размещёнными на печатной плате. Снижение длины дорожек от чипов памяти к GPU вызовет ускорение вычислений и повышение энергоэффективности.
Добавление поддержки скоростного соединения NVLink к Pascal ускорит перемещение данных между GPU и CPU в 5-12 раз, по сравнению с передачей данных по ныне используемой PCI Express, что также серьёзно ускорит приложения deep learning, требующие быстрого сообщения между графическими процессорами. Это особенно важно для глубокого обучения, так как одно только появление NVLink позволит вдвое увеличить количество GPU в системе, одновременно работающих над одной и той же задачей deep learning.
Полную презентацию Дженсена Хуанга с GTC этого года вы можете посмотреть по ссылке.
Ключевые выступления Google и Baidu по теме deep learning
Так как главной темой конференции было глубокое обучение (deep learning) — современная реинкарнация того, что в 80-90-е годы называлось нейросетями, то и ключевые выступления других двух основных дней работы GTC 2015 были посвящены именно этому. Так, в разные дни перед тысячами посетителей выступили представители Google и Baidu (глобальный и китайский поисковики, соответственно). Их выступления во многом пересекались, что было вполне логично, так как работают они примерно над одинаковыми проблемами.

Самое главное в выступлениях от Google и Baidu было то, что для глубокого обучения нейросетей очень нужны значительные вычислительные ресурсы, которые есть у графических процессоров. Более того, многим из этих задач вполне достаточно половинной точности вычислений с плавающей запятой (FP16), что сделает будущие GPU ещё более подходящими для deep learning.

Из основных примеров применения этого метода, который уже используется Google и Baidu, можно привести распознавание изображений и речи. Так, несколько раз в выступлениях на GTC была затронута тема того, что машинное распознавание изображений уже обогнало возможности человека — точность распознавания у хорошо обученной нейросети оказалась выше, чем у среднего представителя человечества.

Надо отдельно отметить, что между точностью распознавания (изображений, речи, да чего угодно) в 95% и 99% есть огромная разница. Так, 99%-ная точность приближает возможности машинных алгоритмов к человеческим, и это может изменить не только индустрию поиска информации, а и многое окружающее нас.

Важно понимать, что deep learning позволяет не писать специфические алгоритмы для каждого конкретного случая, а обходиться общими возможностями анализа, которые самообучаются при «скармливании» нейросети большого количества информации для обучения. Гипотетических применений методу очень много, вот лишь некоторые из них:

А из уже используемых применений GPU-ускоренного обучения можно привести 47 продуктов Google за последние пару лет, вот только часть из них: поиск по изображениям, распознавание речи в Android, размещение контекстной рекламы, просмотр улиц в Google Maps и др. В итоге, компьютерный анализ изображений позволяет добиться весьма точного описания того, что изображено на них, хотя и не без ошибок:


Чтобы уменьшить количество ошибок, надо лишь увеличить количество входных данных для обучения машинного алгоритма. Представитель Baidu привёл интересную аналогию, представив deep learning как ракетный двигатель, а данные для обучения нейросети — как топливо для него. Чем больше топлива для двигателя, тем большую точность и тем более богатые возможности можно получить:

Подводя итог этой пары ключевых выступлений, отметим, что в Google и Baidu видят за deep learning большое будущее умных систем с наличием признаков искусственного интеллекта. Хорошо обученные нейросети помогут в большом количестве разнообразных задач в областях распознавания речи и изображений, моделировании, предсказании, переводе с разных языков, и многих других.

И в этом исследователям со всего мира может очень помочь применение GPU и массивов из графических процессоров. Ведь именно применение GPU позволяет в десятки и сотни раз увеличить возможности глубокого обучения, позволяя получить гораздо лучше обученные нейросети — особенно с учётом отличного масштабирования алгоритмов deep learning и применения будущих GPU с 16-битной точностью вычислений, которая ещё вдвое поднимет производительность.

Будем надеяться, что графические процессоры вскоре ещё больше облегчат нашу с вами жизнь и станут тем самым локомотивом прогресса, который продвинет машинное обучение ещё дальше вперёд, сделав искусственный интеллект чем-то похожим на человеческий. И его возможности не будут ограничены просто очень продвинутым поиском по картинкам и безошибочным распознаванием голоса, хотя и это было бы неплохо.
Перспективы применения платформы Drive PX в автомобилях, в том числе автономных
Ещё одной важнейшей темой на конференции GPU Technology Conference стало применение чипов семейства Tegra в автомобилях, а в будущем даже полностью автономное управление автомобилями с их помощью. Компания Nvidia уже давно проявляет живой интерес к этой теме, и он только усиливается со временем.

Так, ещё на выставке Consumer Electronics Show в январе была представлена мощная платформа Drive PX, предназначенная для разработки автономных автомобилей, предлагающая возможности использования обучаемых нейросетей в будущих проектах. Система Drive PX основана на паре компактных чипов Nvidia Tegra X1, обеспечивающих 2.3 терафлопов производительности при одинарной точности вычислений с плавающей запятой, вполне достаточной для планируемых для этого решения задач.

Этой мощи вполне достаточно для того, чтобы получать и анализировать визуальные данные с 12 камер, что позволяет одновременно использовать широкий набор вспомогательных систем, предназначенных для облегчения работы водителей: просмотр всего пространства вокруг автомобиля, предотвращение столкновений, определение пешеходов и избежание наездов на них, управление без применения зеркал внешнего вида, мониторинг автомобильного трафика вокруг автомобиля и многое другое. На стенде Nvidia стояло несколько рабочих макетов, показывающих Drive PX в работе:


Но все эти уже существующие на данный момент времени системы помощи водителям и так умеют обнаруживать знаки, разметку, пешеходов и автомобили. Они могут предпринимать лишь ограниченный ряд действий, умеют только предупреждать водителя об опасности и тормозить, не поворачивая и не разгоняясь.

А вот будущие системы в автомобилях планируется делать гораздо более продвинутыми, они уже будут определять границы безопасной области дорожного полотна, точно измеряя дистанцию до всех объектов на дороге. И смогут не только предупреждать водителя или тормозить при опасности, но также и ускоряться и даже уметь поворачивать руль при необходимости.

Платформа Drive PX вполне подойдёт для создания куда более продвинутой системы автономного управления, основанной на deep learning. Нынешние системы просто распознают объекты на дороге, классифицируя их и действуют только по жёстким алгоритмам. Это неплохо работает в ограниченном смысле, но этого недостаточно для будущего. Мощные системы вроде платформы для разработки Drive PX смогут работать с глубоко обучаемыми нейросетями при помощи анонсированного пакета DIGITS, дополненного библиотеками для захвата и обработки видеоданных.

Развивая тему глубокого обучения, показали её применимость и для полностью автономного управления движущимся транспортом. Пока что это был не полноразмерный автомобиль, но небольшой самодвижущийся агрегат из проекта Dave:

Отличие Dave от других проектов автономно движущихся аппаратов состоит в том, что в нём нет заранее закодированных вариантов последовательности действий, в зависимости от изображения, считываемого с камер(ы). Этот проект использует глубокое обучение — хорошо обученную нейросеть на основе тренировочных данных, полученных от водителя в лице обычного человека. Иными словами, Dave анализирует полученное с камеры изображение и действует на основании обученной нейросети примерно так, как это делал человек в аналогичной ситуации в примерах, на которых нейросеть обучалась.

Чем лучше обучена нейросеть, тем более правильные решения принимает эта машина. В проекте Dave используется нейросеть с 3.1 миллионами соединений при 12 кадрах в секунду, получаемых с камеры, а внедрение аналогичной системы на базе нейросети AlexNet и применении аппаратного обеспечения Drive PX от Nvidia, можно поднять количество кадров в секунду до 184 FPS, а число соединений до 630 млн. Итоговую разницу в производительности Nvidia оценивает в 3000 раз. Если даже с меньшими возможностями робот неплохо ездит по довольно сложной пересечённой местности, то уж с Drive PX его можно обучить ездить на порядки лучше.

По сути, из Drive PX может получиться неплохой автомобильный компьютер для полностью автономного управления на базе обучаемой нейросети, который сможет действовать аналогично человеку, поворачивая руль, тормозя и ускоряясь тогда, когда это необходимо. Будем надеяться на интерес со стороны автопроизводителей, тем более, что в рамках конференции GTC 2015 была объявлена цена и сроки доступности Drive PX на рынке:

Эту продвинутую автомобильную систему на базе двух чипов Tegra X1 от Nvidia, предназначенную для разработчиков, можно будет заказать за $10000, а доступна она станет в мае текущего года. И разработчики автомобильных систем во всём мире смогут использовать deep learning в своих разработках, которые самосовершенствуются и самообучаются.
Самые известные авторазработчики уже получают подобные системы в своё пользование, и есть большая вероятность, что мы скоро увидим такие самоуправляемые автомобили на дорогах — если не у нас в стране, то в других краях. Так, один из партнёров компании Nvidia анонсировал планы по запуску автономных автомобилей по дорогам США, а компания Audi в январе уже испытала свой концепт A7 на обычных дорогах, который проехал от Кремниевой долины до Лас-Вегаса.

Пока что в прототипе Audi применяется довольно крупная физически аппаратная система для автономного управления автомобилем, но использование такой платформы, как Drive PX, позволит уменьшить её до привычных размеров и освободит багажник легкового автомобиля, когда дело приблизится к серийному производству.
В рамках своего главного выступления на GTC, глава Nvidia Дженсен Хуанг прямо на сцене обсудил тему автономных автомобилей на дорогах с Илоном Маском (Elon Musk) — известным бизнесменом, основателем компаний PayPal, SpaceX и Tesla Motors. Последняя хорошо известна во всём мире, как автомобильная компания из Кремниевой долины, производящая одноимённые электромобили.

Разговор был сравнительно долгим и особых откровений в нём не было, но услышать мнение одного из лидеров индустрии по поводу автономных автомобилей было в любом случае интересно. Илон рассказал о том, что он не видит никаких проблем в скором появлении самоуправляемых автомобилей на дорогах (США), и что он ожидает их распространения уже через несколько лет. Привёл знаменитый бизнесмен и одну интересную аналогию, сравнив автомобили с... лифтами. Действительно, ведь если раньше ими управляли только специально обученные люди (лифтеры), то теперь с нажатием кнопок прекрасно справляются и обычные люди. С автомобилями будет примерно то же самое, считает Илон Маск.
Для Nvidia же крайне полезным стало признание Илона в том, что он считает мощные чипы этой компании важным фактором для развития автономных автомобилей. Маск сказал прямо: то, что делает Nvidia с компактными чипами Tegra, действительно интересно и очень важно в том числе и для автономных автомобилей будущего. Подобное признание дорогого стоит, будем надеяться на появление автономных «Тесл» под управлением «Тегр» в ближайшем будущем!
Анонсы профессиональной графики: Iray 2015, новые модели Quadro и обновление VCA
Компания Nvidia не была бы собой, если бы не сделала на GTC несколько анонсов, связанных с профессиональной 3D-графикой. В целом, стремление компании улучшить профессиональные графические возможности для партнёров в этот раз можно описать привнесением быстрого и качественного рендеринга, основанного на физических принципах (Physically-Based Rendering), в массы.
Компания Nvidia давно занимается качественным 3D-рендерингом, зачастую опрашивая своих читателей в соцсетях на тему того, было ли отрендерено изображение или же это фотография? В основном, продвинутому читателю не составляет труда отделить реальность от его виртуального отображения, но эта задача становится всё сложнее.
И это не просто баловство, для многих клиентов компании создание физически корректно просчитанных изображений виртуального пространства жизненно необходимо. К примеру, чтобы посмотреть, как будет выглядеть автомобиль с теми или иными вариантами отделки без необходимости постройки полноразмерного макета, можно просто отрисовать его модель, но обязательно с максимально реалистичными материалами и освещением. Именно поэтому Physically-Based Rendering настолько важен.

Чтобы визуализация была фотореалистичной, требуются качественно проработанные материалы и реалистичный физический расчёт того, как они взаимодействуют с источниками света. Например, для того же автомобиля это означает, что при определённом угле падения лучей света на панель приборов, яркие блики на одних материалах появятся, а на других — нет, хотя разница между этими материалами на первый взгляд невелика.
Чтобы рендеринг максимально точно повторял физические основы, используются специальные методы physically-based rendering, требующие очень значительных вычислительных мощностей — в частности, самых быстрых графических процессоров. Именно с PBR-рендерингом получается аккуратный и предсказуемый результат, достаточный для самых требовательных клиентов Nvidia.
В рамках конференции GTC компания анонсировала сразу несколько продуктов, связанных с темой профессиональной визуализации высокого качества, которые предназначены для тысяч дизайнеров. Анонс можно условно разделить на три части: новая версия рендерера, основанного на физических принципах Iray 2015, выход новой профессиональной модели Quadro и обновление комплекта Quadro Visual Computing Appliance, предназначенного для профессионалов 3D-графики.
Первым по значимости анонсом можно считать пакет Iray 2015 — последнюю версию GPU-ускоренного рендерера, основанного на физике взаимодействия света и материалов, теперь с новыми возможностями по обмену материалами между несколькими различными 3D-приложениями, улучшенной масштабируемостью и производительностью рендеринга.
Основанный на законах физики Iray 2015 рассчитывает, как материалы сцены взаимодействуют со светом, он работает на решениях Nvidia Quadro и Quadro VCA, масштабируясь от ноутбуков до серверов. Поддерживаются все самые распространённые 3D-пакеты вроде Autodesk Revit, 3dsmax, Maya, Bunkspeed, Catia, Rhinoceros, Maxon, и других.


Из новых возможностей особенно отметим внедрение языка описания материалов (Material Definition Language — MDL), который сделает возможность использования одних и тех же физически корректных материалов в различных приложениях. Пока что этот язык описания материалов не поддерживается в другом ПО, но это — вопрос будущего.
Не менее важным можно считать анонс новейшей профессиональной видеокарты из линейки Quadro. Модель Quadro M6000 является последним дополнением профессиональной серии Nvidia, она основана на полноценном чипе GM200 архитектуры Maxwell — ровно как и вышедшая недавно видеокарта Geforce GTX Titan X, обзор которой можно прочитать на нашем сайте.

Новинка для 3D-профессионалов также имеет 3072 потоковых CUDA-ядер и 12 гигабайт памяти, что очень полезно для рендеринга самых сложных сцен. Хотя Quadro M6000 основана на том же чипе GM200, его частоты несколько снижены для лучшей стабильности работы. Так, частота GPU составляет меньше 1 ГГц, а пропускная способность видеопамяти равна 317 ГБ/с. Из-за этого удалось немного снизить типичную величину потребляемой энергии — до 250 Вт.

Несмотря на это, производительность новинки не снизилась ниже 7 терафлопов при вычислениях одиночной точности. Более того, новая Quadro M6000 является первой профессиональной моделью, которая поддерживает известную по игровым видеокартам технологию увеличения тактовой частоты GPU Boost — до 10 значений повышенной частоты, на которых будет работать GPU в определённых 3D-приложениях.
В итоге, новинка обеспечивает более чем 2,4-кратный прирост скорости рендеринга в Iray 2015, по сравнению с лучшей моделью Quadro на базе чипа архитектуры Kepler, работающей под управлением Iray 2014 (какая часть прироста относится к программной, а какая к аппаратной части — остаётся пока что загадкой). Клиенты компании Nvidia, небезызвестные LucasFilm, в своём собственном ПО для трассировки лучей на модели Quadro M6000 отмечают прирост до 55%.
Это не единственная модель Quadro, представленная сегодня. Также компанией была анонсирована модель Quadro K1200 — самая мощная видеокарта, предназначенная для рабочих станций малого форм-фактора (small form factor — SFF), которые получают всё большее распространение.

Такие системы сейчас достаточно востребованы, и для них требуется специально сертифицированная продукция для применения в профессиональных приложениях. Модель Quadro K1200 как раз способна заметно ускорить основанный на физических законах рендеринг — в этой задаче она до четырёх раз быстрее, чем восьмиядерный серверный CPU модели Intel Xeon E5 2687W.

Ну и последним анонсом на GTC, связанным с профессиональной 3D-графикой, стало обновление Quadro Visual Computing Appliance (VCA) — теперь эта система может включать до восьми видеокарт, аналогичных свежеанонсированной Quadro M6000, что даёт потрясающий прирост скорости в задачах 3D-рендеринга, в том числе и в упомянутом Iray 2015.

Все представленные на конференции в Сан-Хосе новые продукты Nvidia должны дать дизайнерам и конструкторам новые возможности, ускорив производительность их систем в 1,5-2 раза. Так, обновленная система VCA в принципе является самым быстрым серверным узлом для рендеринга на GPU, хотя на российском рынке она и не продаётся (вероятно, по причине отсутствия спроса).
Бонус: экскурсия по самым интересным помещениям Nvidia в Санта-Кларе
В качестве бонуса предлагаем вашему вниманию небольшой фотоотчёт. Ваш покорный слуга получил шанс посетить одни из самых интересных помещений в зданиях компании Nvidia, расположенных неподалеку от места проведения GTC — в Санта-Кларе, и мы предлагаем вам посмотреть фотоотчёт об этой экскурсии. Хотя компания уже давно строит для себя новые здания большей площади, пока что сотрудники Nvidia располагаются в привычных четырёх основных и нескольких вспомогательных, о которых мы уже писали в прошлые годы.

Офисные здания и растительность вокруг них ухожены и выглядят весной очень красиво — по всей территории цветут вишнёвые деревья, а зелень всё ещё молода и свежа. Путь посетителя в основном здании Nvidia начинается со списка достижений, среди которых представлены как самые важные патенты компании (не все, естественно — так как всего их несколько тысяч), так и кубки и другие экспонаты, полученные за всё время работы:

Самым забавным трофеем среди выложенных можно посчитать гитару с логотипом AMD Opteron, которая вызывает всеобщий интерес. Всё очень просто — в своё время, ещё до приобретения ATI компанией AMD, компании были партнёрами и тесно взаимодействовали друг с другом, и ничего особенного в этом нет.

Первой комнатой, которую посетили журналисты, стала тестовая лаборатория Nvidia с говорящим названием Failure Analysis Lab, где различные чипы компании подвергаются тщательному анализу на предмет каких-либо физических проблем — вроде токов утечек (leakage) и т.п. Именно тут определяют проблемные участки первых ревизий GPU и других микросхем Nvidia.


Для тщательного анализа работоспособности микросхем в этой лаборатории применяется масса дорогостоящего оборудования, включая дорогие микроскопы, работающие в разных диапазонах и прочие установки, стоящие немало миллионов долларов. Эти деньги вернутся сторицей, так как сокращение брака на единицы и даже доли процента, приводит к снижению расходов при выпуске миллионов GPU.



В этой лаборатории работает не очень много сотрудников, но их работа весьма важна, так как позволяет определить проблемы на поздних стадиях разработки. Они исследуют кристаллы, как стачивая их послойно (современные чипы имеют несколько кремниевых слоёв) вдоль, так и распиливая их перпендикулярно.



Говорят, что мы уже увидели тесты чипов компании, произведённых с применением 20, 16 и даже 14 нм техпроцессов (интересно, 14 нм чипы были произведены на фабриках Samsung или GlobalFoundries?). Жаль, что на экранах хоть и была куча информации, но ничего из неё просто непонятно для непосвящённых.
Так как речь идёт о лаборатории анализа неудачных чипов, то неудивительно, что вокруг полно бракованных GPU уже известных нам серий — например, вот большая коробка с нерабочими чипами GK210, которые использовались исключительно в профессиональных системах для вычислений Tesla:

Пожалуй, даже ещё более интересной является лаборатория Emulation Lab, которая позволяет эмулировать любые микросхемы компании при помощи специализированного программного и аппаратного обеспечения ещё до их выпуска — это нужно для того, чтобы найти и устранить проблемы в новых чипах до их физического воплощения.

Именно в этой комнате исследуются сверхсекретные разработки, которые ещё весьма далеки от готовых решений в кремнии. Конечно же, нам их и не показывали. В работе тут используются программно-аппаратные средства от компании Cadence, которые и по размеру большие, и требуют очень много энергии и мощного водяного охлаждения, так как каждая из машин потребляет 10 кВт и более.

При помощи специальной платы расширения такой эмулятор виден для обычного ПК как обычная видеокарта. Да, она работает намного медленнее аппаратной версии, но функционально ничем ей не уступает, что позволяет проверить работу GPU во всех подробностях задолго до выхода решений на рынок.

Отдельное внимание обратите на толщину и количество кабелей, присоединённых ко всем системам — становится понятно, насколько тут всё серьёзно:

Интересно, что имеющиеся в комнате эмуляторы названы по именам известных во всём мире рек (возможно, так получилось из-за применения водяного охлаждения — ведь охлаждающая жидкость течёт по трубам практически рекой), здесь есть Амазонка, Темза и... даже наша родная Волга!


Обязательно нужно добавить, что именно эту комнату можно назвать самой дорогой в Nvidia — собранное здесь оборудование стоит не один десяток миллионов долларов, да и потребляют они немалую долю энергии от всего потребления офисных зданий. Но без эмуляции современная разработка микросхем попросту невозможна, и с этим приходится мириться.
Ещё одной комнатой, которую мы посетили и фотографиями из которой можем поделиться, была комната eSPORTS — как вы знаете, под эгидой Nvidia проводятся разнообразные соревнования по сетевым играм, в том числе и World of Tanks, кстати. А комната представляет собой неплохо оснащённый всем необходимым центр для проведения подобных турниров.

К сожалению, мы не можем показать вам фотографии из тестовой лаборатории технического маркетинга, которую мы также имели честь посетить — по какой-то причине это было запрещено уже после того, как мы отсняли материал и поговорили с представителями этого отдела. Так что остаётся лишь её краткое текстовое описание — это довольно тёмная комната с кучей готовых к тестированию систем, а также комплектующих и кабелей, удобно отсортированных и уложенных в специальных шкафах.
На многочисленных рабочих столах в комнате стоит несколько систем с различной конфигурацией и видеокартами, на которых специалисты Nvidia делают примерно то же самое, что и журналисты при работе над обзорами, используя абсолютно те же методы, что и мы. Интересно, что вокруг рабочих мест много разных постеров, наклеек и аксессуаров из известных игровых проектов — ничто человеческое сотрудникам Nvidia не чуждо.
Пожалуй, самой любопытной в тестовой лаборатории технического маркетинга была доска с указанными на ней преимуществами и недостатками пары свежих аналогичных технологий от Nvidia и AMD, которые сейчас на слуху. Но о написанном на ней нам говорить строжайше запретили, поэтому мы можем лишь принять написанное к сведению при подготовке собственных материалов по данной тематике, раз уж эту доску не успели от нас спрятать.
Выводы
Главная конференция Nvidia по GPU-технологиям постоянно увеличивает масштабы, давно являясь главным событием года для экосистемы графических процессоров, и не только этой компании. Новые продукты и технологии Nvidia вот уже который год помогают развитию всей индустрии визуальных и прочих вычислений, и конференция в шестой раз собрала ещё больше людей, связанных с применением GPU в различных сферах — в этом году участников насчитали более четырёх тысяч.
Вычислительные возможности процессоров компании Nvidia используются в различных задачах, и именно мощные GPU обеспечивают скачки в производительности и даже новые возможности во многих сферах за счет огромного прироста их вычислительных мощностей и функциональности. В этом году основной темой GTC стало так называемое глубокое обучение (deep learning) — новое название самообучаемых нейросетей. Это — лишь один из методов машинного обучения, но именно на него сейчас направлено внимание компании.
Это и понятно, ведь глубокое обучение весьма эффективно работает на графических процессорах и оно может открыть важные возможности для человечества — чем глубже будут обучены соответствующие нейросети, тем «умнее» станут машины. А уж применений этому методу масса, начиная с простого поиска визуальной информации и распознавания голоса, заканчивая автономными автомобилями и прочими элементами искусственного интеллекта — этому были посвящены все ключевые выступления: и президента Дженсена Хуанга, и представителей Google и Baidu.
Но не deep learning'ом единым... Все остальные применения GPU также требуют огромных вычислительных мощностей, и всё большее количество компаний представляют на GTC свои разработки, использующие решения Nvidia. Пожалуй, из самых интересных анонсов на GTC 2015 мы особенно выделим даже не выпуск мощнейшего решения Titan X, хотя и это решение было ожидаемым публикой, и даже не свежие данные о следующем поколении графической архитектуры — Pascal, но объявления цены и доступности для Drive PX, весьма важной для будущего автомобилей, а также анонсы DIGITS и DIGITS DevBox — новых программного и программно-аппаратного продуктов, предназначенных для упрощения быстрого построения глубоких нейросетей. Эти продукты вполне могут открыть новые рынки для Nvidia, а также стать важными для всей индустрии вычислений.
Что касается более традиционной сферы для компании, которая связана с графическим применением в профессиональной сфере, то и тут компания отличилась, выпустив новую версию Iray 2015, которая приносит на рынок отлично оптимизированный качественный 3D-рендеринг, основанный на физических принципах. В дополнение к этому Nvidia выпустила аналог Titan X для профессиональной графики в виде Quadro M6000, а также обновила свою Quadro Visual Computing Appliance (VCA) — теперь эта система включает до восьми видеокарт самой мощной модели Quadro M6000. Всё вместе это весьма серьёзно ускоряет задачи 3D-рендеринга.
Как вы можете видеть, ежегодная конференция компании Nvidia по применению графических процессоров постоянно растёт в масштабах, так что можно быть уверенными, что и в следующем году ее участников порадуют как интересные выступления, так и важные анонсы в ещё большем объеме. В который уже раз, по просьбам участников конференции, следующую GTC, которая пройдет всё в том же самом Сан-Хосе, решили передвинуть ещё чуть позже — на начало апреля 2016 года, когда в районе Кремниевой долины будет ещё теплее. И мы постараемся держать вас в курсе всех самых интересных событий и в следующем году.

Если у вас остались какие-то вопросы по темам конференции, или вы хотите ознакомиться с другими материалами, которые были представлены на конференции Nvidia по GPU-технологиям, то все записи ключевых выступлений и других сессий доступны для всех интересующихся на сайте конференции GTC.

