Deepfake голоса и создание новых композиций с помощью нейросети
Благодаря развитию нейронных сетей эффект «Зловещей Долины» с каждым днём всё ближе и ближе к человечеству, ибо то, что когда-то считалось невозможным, в наши дни становится вполне осуществимым. В этой небольшой инструкции вы узнаете, как выполнить Deepfake голоса и на его основе создать совершенно новую композицию, даже если его обладатель давно покинул нас.

RVC-GUI — это удобная оболочка с открытым исходным кодом созданная для упрощения управления параметрами нейронной сети RVC применяемой для синтеза любого голоса/музыкальной композиции. По сравнению с аналогами, не требует установки и настройки сложных библиотек или использования Linux. Для работы программы достаточно Windows 10/11 и относительно современного ПК.
Инструкция
1. Скачиваем с GitHub бесплатное приложение RVC-GUI и распаковываем его в любую удобную папку. Убедитесь, что в название папки или пути до конечного файла запуска нет кириллицы.
2. Запускаем файл RVC-GUI.bat.
Если всё прошло успешно, то перед вашим взором появится интерфейс ПО.
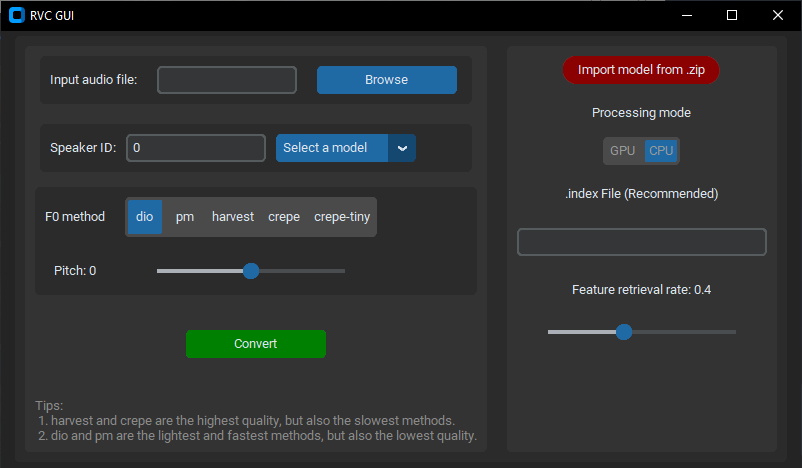
3. Чтобы программа могла воссоздать полноценную музыкальную композицию с интересующем нас голосом, необходимо заранее подготовить голосовую модель и отделить вокал солиста от инструментала в интересующей нас композиции. В общем, чтобы голос стал отдельно от музыки.
Скачиваем заранее обученные модели:
- Модель голоса Михаила Горшенёва (Король и Шут) (Спасибо Baron Unger)
- Модель голоса Юлии Олеговны (t.A.T.u.)
Дополнительные модели формата RVC/RVC2 вы всегда можете найти здесь.
4. Выбираем желаемую композицию, которую мы хотим, чтобы наша модель перепела. Отделяем вокал солиста от инструментала. Благо, сделать это весьма просто.
Переходим на веб-сайт редактора:
- Отделить вокал от музыки
- Отделить вокал от музыки (Зеркало 1)
- Отделить вокал от музыки (Зеркало 2)
Загружаем трек формата .mp3 и дожидаемся пока редактор обработает композицию. Скачиваем результат.
5. После того как мы выбрали желаемую модель и отделили вокал от инструментала, можно вновь возвращаться к интерфейсу программы.
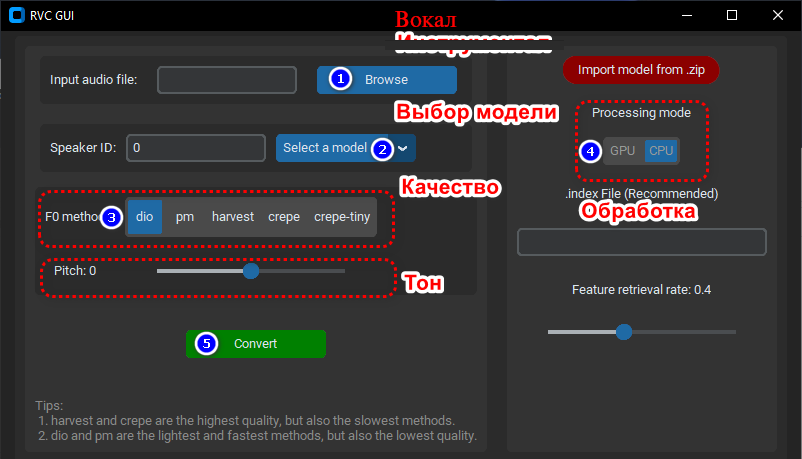
- (1) Выбираем через кнопку Browse наш подготовленный музыкальный трек с голосом солиста.
- (2) Загружаем и выбираем модель через кнопку Select a model. Чтобы загрузить голосовую модель, можно воспользоваться кнопкой Import model from. zip в интерфейсе ПО или распакуйте файлы архива модели напрямую в папку models с установленной программой.
- (3) Выбираем алгоритм конечного качества трека. Советую всегда использовать пресет harvest.
- (4) Выбираем, на чём будет обсчитываться конечный трек. Если у вас мощный ПК с видеокартой Nvidia, то выбирайте GPU, но не забудьте тогда установить вспомогательный пакет CUDA. Обладатели видеокарт AMD/Intel выбирают CPU.
- (5) Нажимаем Convert.
Вот, собственно, и всё! Если всё было сделано правильно, то, через пару десятков минут, вы получите готовый музыкальный трек с любимым исполнителем в папке рядом с оригиналом.
6. Сводим готовы аудиодарожки вокала и инструментала в любом аудио/видео редакторе. Лично я использую для этого бесплатный видеоредактор Shotсut.
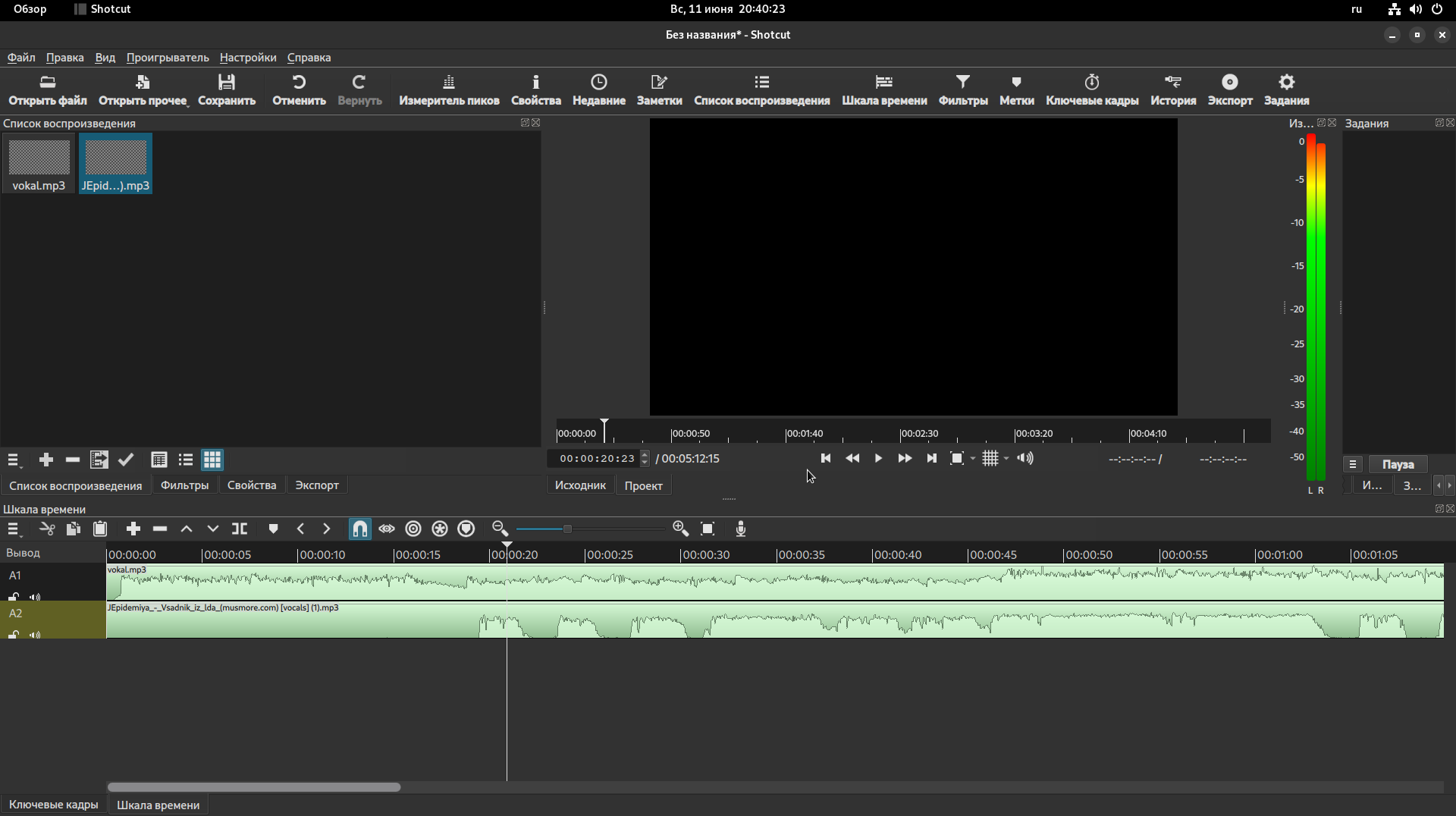
- Правый клик по нижней части программы>> действия с дорожкой>> добавить аудиотрек.
- Левый угол программы «Открыть файл». Переносим треки на добавленные дорожки.
- Правый угол программы «Экспорт». Выбираем в левом углу программы желаемый формат и качество.
7. Наслаждаемся результатом.

Заключение
Скажу откровенно, меня пугает уровень развития современных технологий. Но кроме страха я ощущаю ещё и надежду. Надежду на то, что человечество может и не искоренит свои пороки, но благодаря развитию технологий подарит утешение миллионам людей по всему миру. Уважайте свободу, используйте свободное ПО и ни в коем случае не предавайте себя!











53 комментария
Добавить комментарий
___________
Земенено!
а вообще браво ?
А Отковыривать голос и музыку отдельно в Ultimate Vocal Remover
ЗЫ я хз как комент сюда попал вместо того чтобы пойти вниз… ну да ладно.
По теме отвечу что для телефона есть гугл коллаб он всё за телефон сделает по быстрому)
Но это огромная тема есть на ютубе lunnaholy он инструкции подробные снимал для бедолаг с телефонами
____________________
https://sun9-68.userapi.com/impg/kd6PbLiwqeZXUQUaGrhvfO7RzOsKtzyNKRdvrA/nqmmeGHt7uM.jpg?size=408x799&quality=96&sign=732996bb6c0bcb3d8034bd250d444997&type=album
_____________________
https://sun9-44.userapi.com/impg/xPuiy1N3LeDzaej6LE9FLz5RQ5zA7jnLboEJng/hXQC4cymEEI.jpg?size=1118x211&quality=95&sign=6aa0749ba4a3e0c6e2520597d41d4f62&type=album
Именно на fork это его главное отличие от просто svc
ЗАбираю в арсенал извращений и РВС))
И он модельку радостно всосал и уже вовсю пашет над моим тестовым треком )) О_О
ВОзможно модельки универсальные)
Ога пока писал до меня допёрло почему по ссылке в списке на некоторых там написано RVC в скобках!
Там значиться всё в перемешку лежит)
Нейросеть в недавних версиях наловчилась адекватно переваривать гроул и скрим и петь его внятно чистым голосом))
Например вот так Милен Фармер поёт лютый похоронный дум митол)
https://www.youtube.com/watch?v=TfkuXjirPYU
А вот так русскую алтьтернативу 2007го))
https://www.youtube.com/watch?v=nne3wxyzeZU
Возможны неприятные открытия типа экстрим вокалиста орущего мимо нот но при экстрим вокале это было нормально а на чистом звучит как испанский стыд))
Ещё обнажается хреновое качество записи или недостаточная тренировка модели (не только малое количество эпох но и неудачно собранный датасет для тренировки с однообразным или слишком небольшим по количеству материалом) — слова могут звучать неразборчиво.
Ну и на совсем высоком скриме или шрайке уменьшайте питч иначе чистым голосом будет совсем шептать)
Лучше тестить промежуточные итерации (я сохраняю каждую 1000ю потому говорю за них) скажем 42000 шаг может звучать с откровенный металлическим голосом робота работая хуже чем 16000й а тем временем 41000 был идеален о_о а 40000 тоже мусор.
Металл кстати многое прощает! Как раз плотное музло скрывает многие косяки) Голос понизил в редакторе на децибел и ваще хорошо стало)
А вот с простым музлом типа голоса под гитару засада) косяки как на ладони — их нечем маскировать!
Естественно всё это зависит от того чей голос куда натягивать)
Когото проще когото сложнее.
Это индивидуально даже не для каждого исполнителя а для для каждой песни.
И есть ли еще российские голосовые модели для скачивания, кроме 2-х в статье?
2. Модели есть, но их нужно ещё поискать. В основном все их обучают сами и мало кто делится в итоге. Погуглите модели или гайд по обучению. Я хотел продолжить гайд обучением, но обнаружил, что это мало кому интересно. В общем, решил не тратить силы.
Инструкция по обучению увы токмо на ангельском но с картинками! https://youtu.be/x-jelyl6dyE
Коллаб для тренировки по этой инструкции https://colab.research.google.com/drive/1TU-kkQWVf-PLO_hSa2QCMZS1XF5xVHqs#scrollTo=MErtbNbp4wn0
Коллаб живой и рабочий остальное что находил нерабочий мусор.
Да суперкомпы гугла бесплатно попашут на вас 3 часа в сутки мощей стоимостью в пару миллионов)
Некий неивестный никому поц lunnaholy за месяц поднял на этом и канал в телеге до 3к подпищеков и ютубный...
Хотя тогда эффект новизны был в конце апреля…
File «site.py», line 169, in addpackage
File "", line 1, in
File "<frozen importlib._bootstrap>", line 562, in module_from_spec
AttributeError: 'NoneType' object has no attribute 'loader'
Remainder of file ignored
Error processing line 1 of G:\Archive\Deep Fake\runtime\lib\site-packages\matplotlib-3.6.2-py3.9-nspkg.pth:
Traceback (most recent call last):
File «site.py», line 169, in addpackage
File "", line 1, in
File "<frozen importlib._bootstrap>", line 562, in module_from_spec
AttributeError: 'NoneType' object has no attribute 'loader'
Remainder of file ignored
Error processing line 7 of G:\Archive\Deep Fake\runtime\lib\site-packages\pywin32.pth:
Traceback (most recent call last):
File «site.py», line 169, in addpackage
File "", line 1, in
ModuleNotFoundError: No module named 'pywin32_bootstrap'
Remainder of file ignored
Traceback (most recent call last):
File «G:\Archive\Deep Fake\rvcgui.py», line 3, in
from tkinter import filedialog
ModuleNotFoundError: No module named 'tkinter'
Press any key to continue.. .
((((
Добавить комментарий