Копируем и воспроизводим голос другого человека: ультимативный гайд по DeepFake Voice
Здравствуйте, уважаемые читатели портала IXBT. live! С вами, как всегда, на связи скучный Павел и в этой небольшой инструкции вы узнаете, как с помощью нейронной сети скопировать и воспроизвести голос любого человека. Мы последовательно, шаг за шагом разберём такие сложные вопросы, как подготовка датасета (сбора данных), создание модели голоса, значение параметров конфигурации нейронной сети, разделение вокала и инструментала, а также приведём наглядные примеры использования технологии DeepFake Voice.

Содержание
Внимание!
Вся инструкция представлена только в ознакомительном виде. Автор не несёт никакой ответственности за её использование.
Системные требования
- ОС: Windows 10/11
- CPU: Intel Pentium G4560/AMD Athlon 3000G
- GPU: Nvidia GTX 960/AMD RX 470 (Частичная поддержка)
- RAM: 16 ГБ/ 8ГБ (с файлом подкачки на SSD)
Инструкция
Благодаря современным технологиям и возросшим мощностям домашних компьютеров копирование и воспроизведение любого голоса даже в режиме реального времени — это весьма не тривиальная задача.
Подготовка данных
Чтобы качественно скопировать голос любого человека, нам необходимо подготовить датасет с 10-30 минутным примером звучания копируемого голоса. Для этого идеально подойдут аудиокниги, подкасты, обзоры и файлы локализации видеоигр. Я же выбрал голос главного редактора портала IXBT. Games Виталия Казунова с его старого видеообзора на YouTube технологии Nvidia RTX Voice.
1. Скачиваем видеоролик и открываем его в любом удобном видеоредакторе. Лично я предпочитаю использовать Shotcut.
П.С. Удобный способ скачивать видео с YouTube.
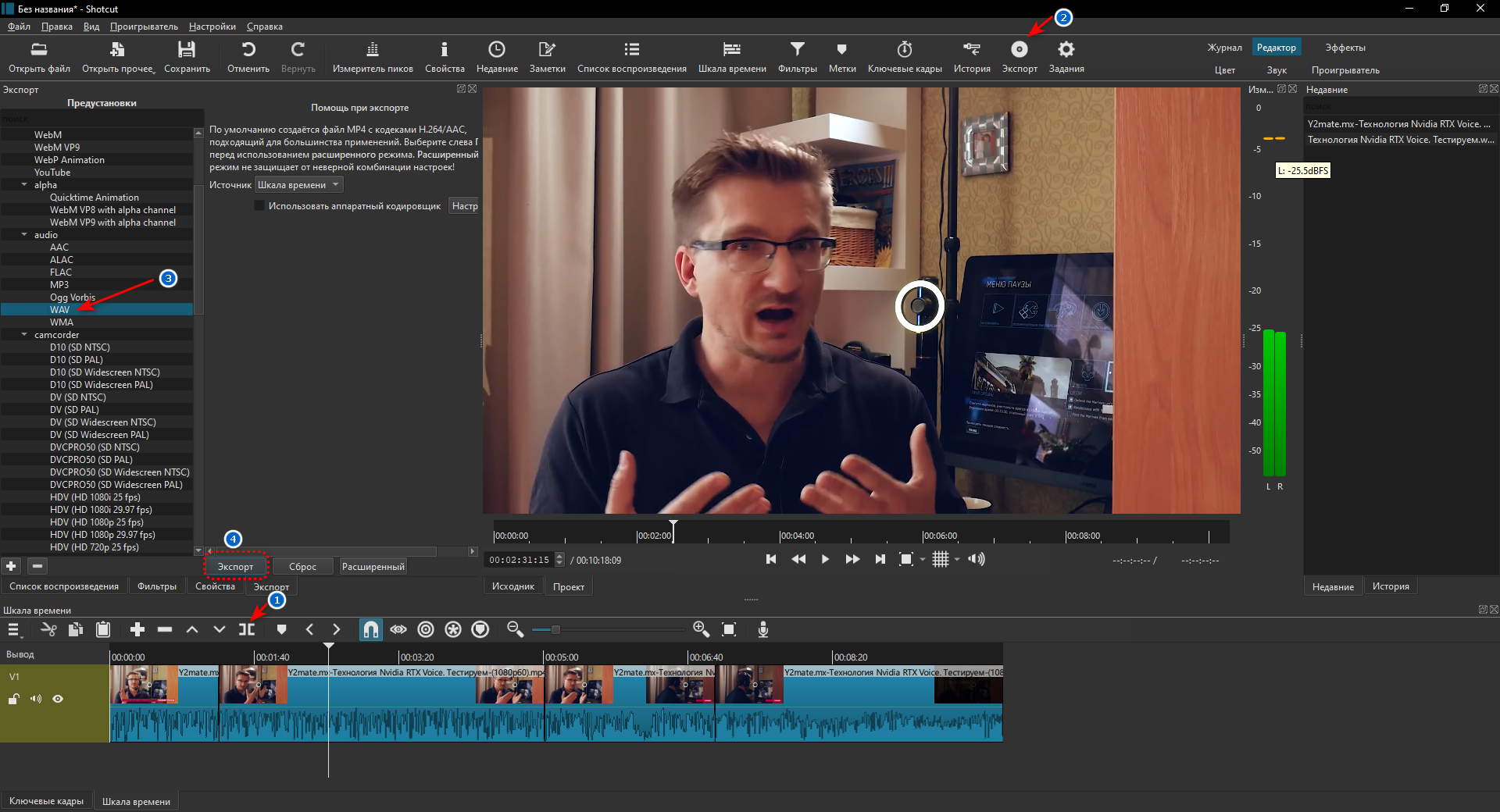
2. Просматриваем ролик, убеждаясь, что видеофайл не содержит посторонних шумов или вкраплений чужого голоса. Если же они есть, то вырезаем участки шума и конвертируем получившуюся дорожку в файл формата wav или mp3.
3. После того как вы подготовили файлы с желаемым голосом, создаём в корне любого диска папку с именем Dataset и переносим в неё нашу запись. В дальнейшим новая папка будет часто использоваться для работы с нейросетью.
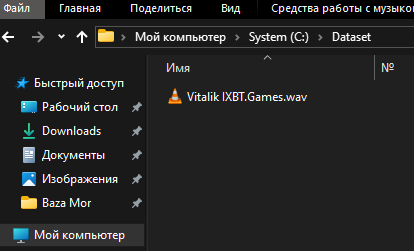
Установка и обучение нейросети
После того как мы подготовили материалы для обучения модели нейронной сети, можно переходить к её установки на ПК.
1. Скачиваем портативный вариант нейросети. Она не требует установки сторонних библиотек, а благодаря энтузиасту, скрывающимся под ником Ba1yya, ещё и полностью переведена на русский язык.
Зеркало установщика нейросети.
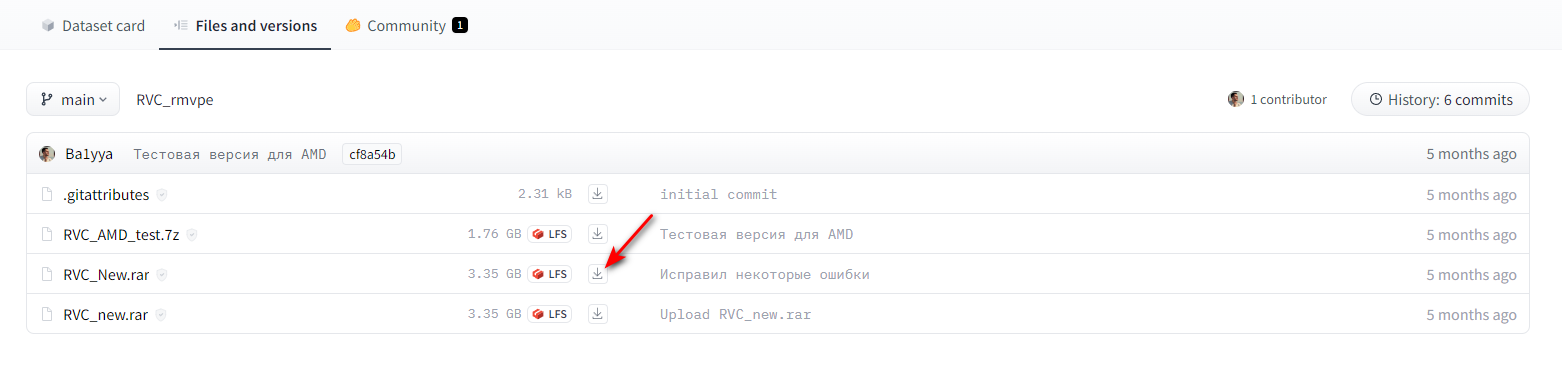
2. Распаковываем файлы архива в любое удобное место и запускаем нейронную сеть через двойной клик по файлу go-web.bat.

Если всё прошло успешно, то вас автоматических перенесёт в вашем веб-браузере на страницу панели управления нейросетью по адресу localhost:7897. На открывшейся странице переходим в раздел «Тренировка» и последовательно следуем шагам, как показано на картинке.
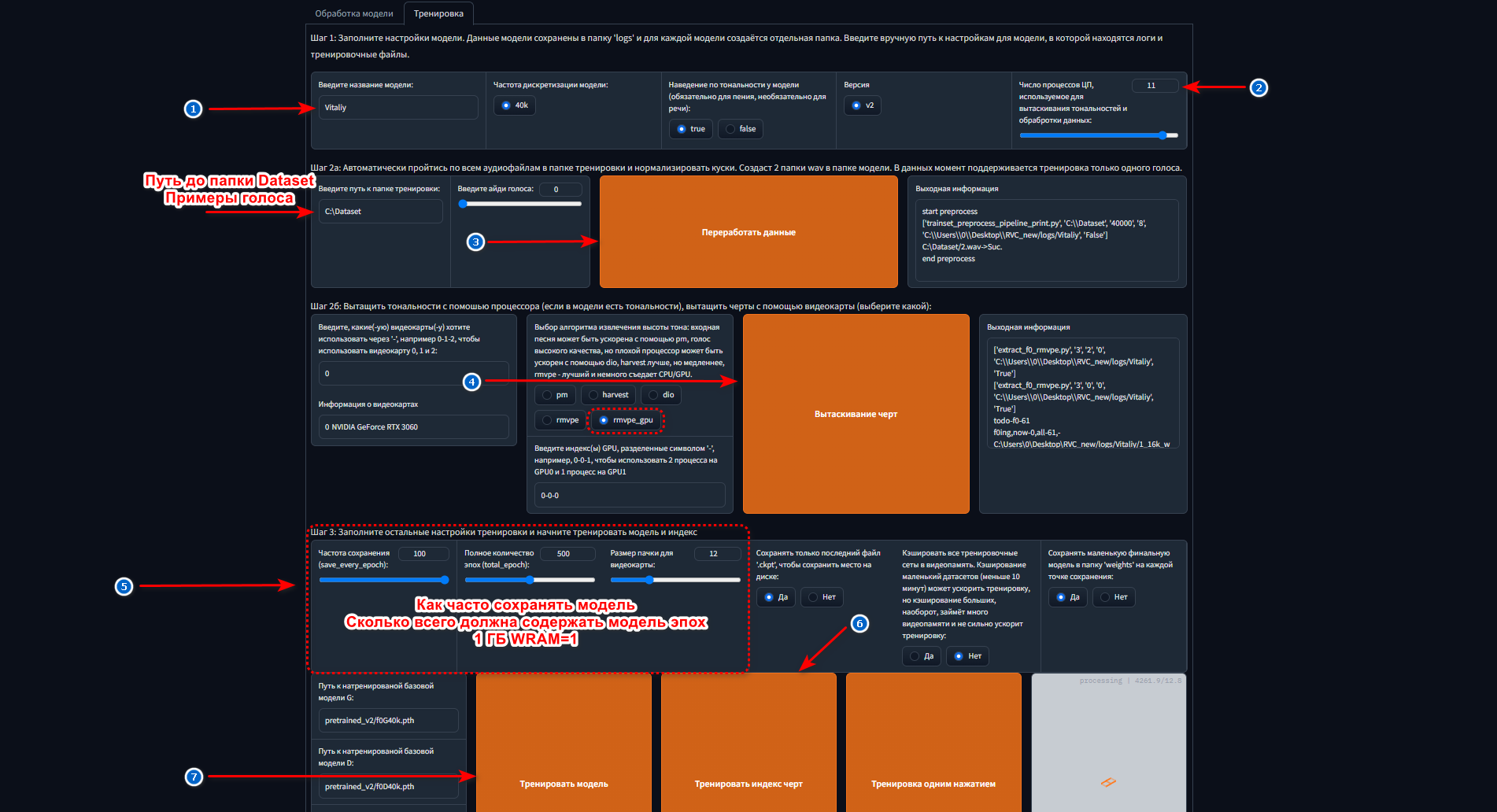
- Задаём название будущей голосовой модели. (Не используйте кириллицу).
- Указываем количество ядер CPU. (Всегда ставьте на 1-2 меньше от макс. доступного числа ядер).
- Запускаем обработку датасета (Записей копируемого голоса).
- Выбираем алгоритм копирования тона. (Советую поставить, как показано на картинке выше).
- Задаём настройки частоты сохранения, максимальное число эпох (качество будущей модели) и нагрузки на GPU.
- Копируем индивидуальные черты голоса человека.
- Запускаем обучение голосовой модели.
Создание качественной голосовой модели может занять продолжительное количество времени. Например, на RTX 3060 Ti и Intel Core 12400F обучение с датасетом длинной 15-20 минут и 500 эпох занимает 3-4 часа реального времени. В консоли сmd вы можете отслеживать текущий прогресс обучения вашей голосовой модели. Перейдём к наглядному использованию.
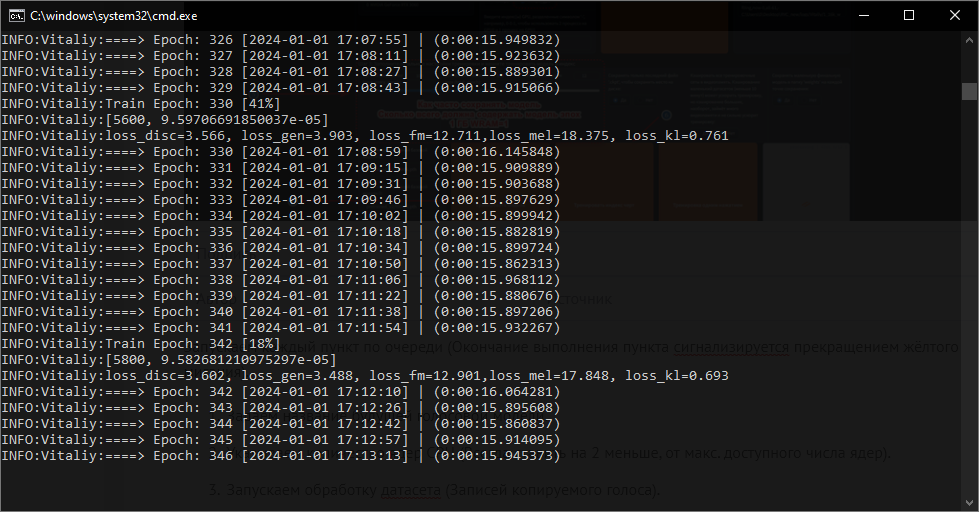
Использование голосовой модели
Есть множество вариантов задействовать чужой голос: от шутливого поздравления с днём рождения голосом именинника до создания полноценной озвучки. Рассмотрим варианты применения технологии DeepFake Voice подробней.
Музыкальное произведение
Самое простое, что можно придумать с чужим голосом, — это заставить его спеть известную музыкальную композицию. Заставим Виталия Казунова спеть популярную песню «Ведьмаку заплатите чеканной монетой».
1. Находим в глобальной паутине выбранную музыкальную композицию в формате mp3/wav или конвертируем её сами. Помещаем её в любую удобную папку, не содержащую в пути или названии кириллицы.
2. Скачиваем бесплатную программу для отделения вокала (голоса) от инструментала (музыкальных инструментов).
Зеркало программы для отделения вокала от инструментала.
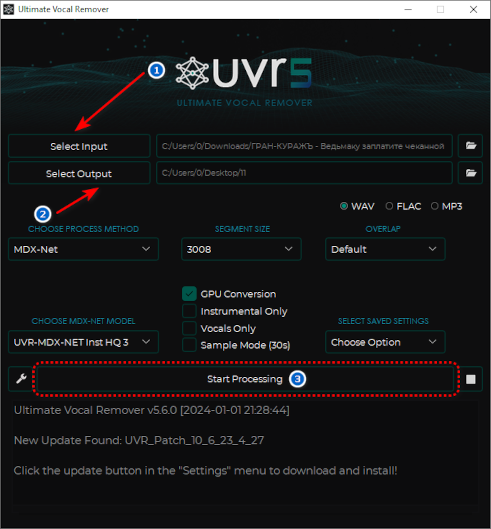
- Выбираем аудиотрек.
- Выбираем папку, куда будут распакованы файлы вокала и инструментала.
- Все настройки выставляем, как на скриншоте выше, и жмём кнопку Start.
В итоге у вас должны получиться два отдельных музыкальных файла. Переносим файл вокала оригинального аудиотрека в новую папку Vokal.
3. В панели нейронной сети переходим в раздел «Обработка модели».
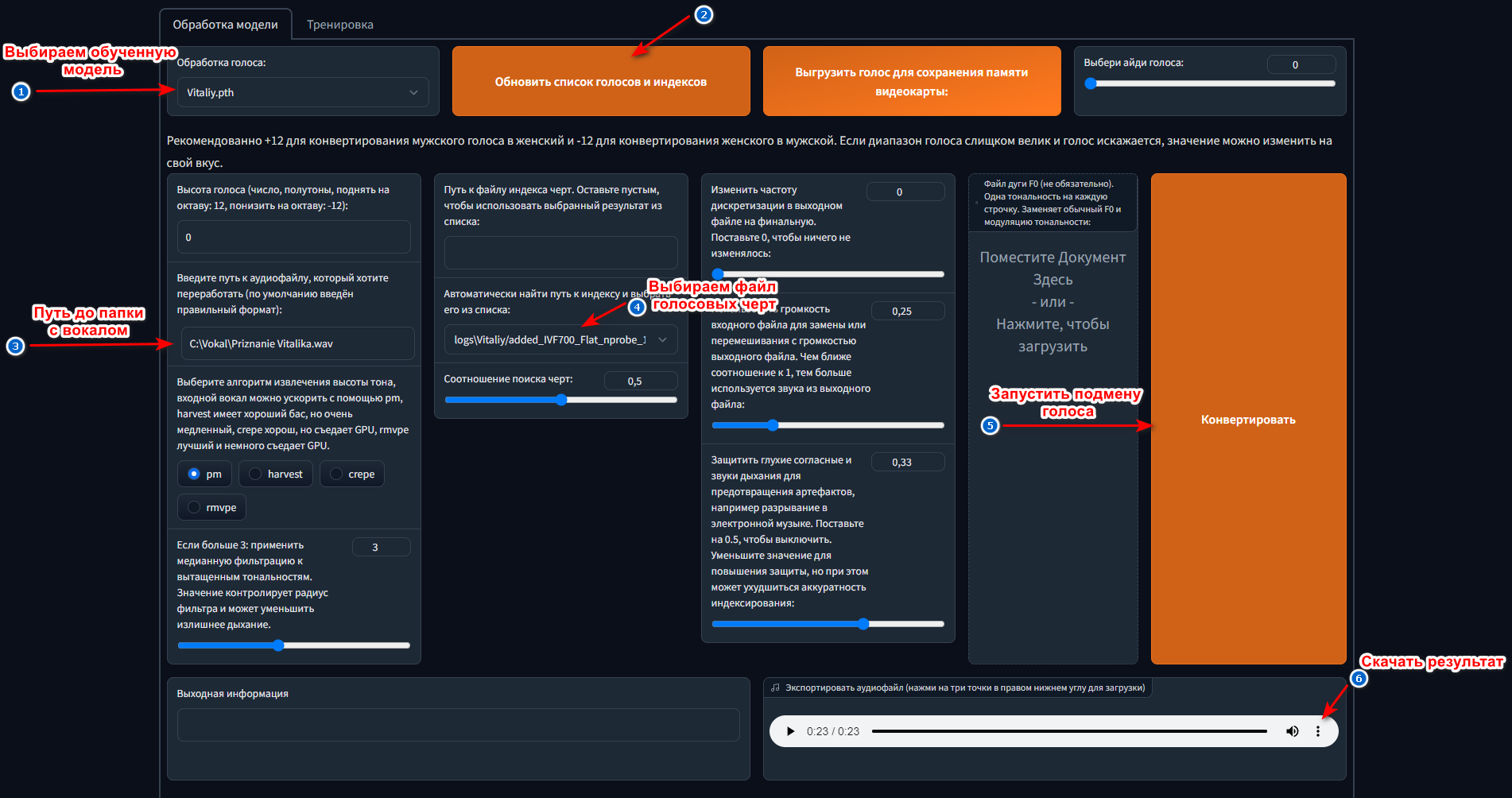
- Выбираем обученную голосовую модель.
- Обновляем список (Если не видно модели).
- Указываем путь до папки Vokal, содержащую файл записанного голоса на замену.
- Выбираем файл модели голосовых черт.
- Запускаем замену голоса.
- Скачиваем обработанный файл.
4. Сводим полученную дорожку изменённого вокала со старым инструменталом с помощью видеоредактора.
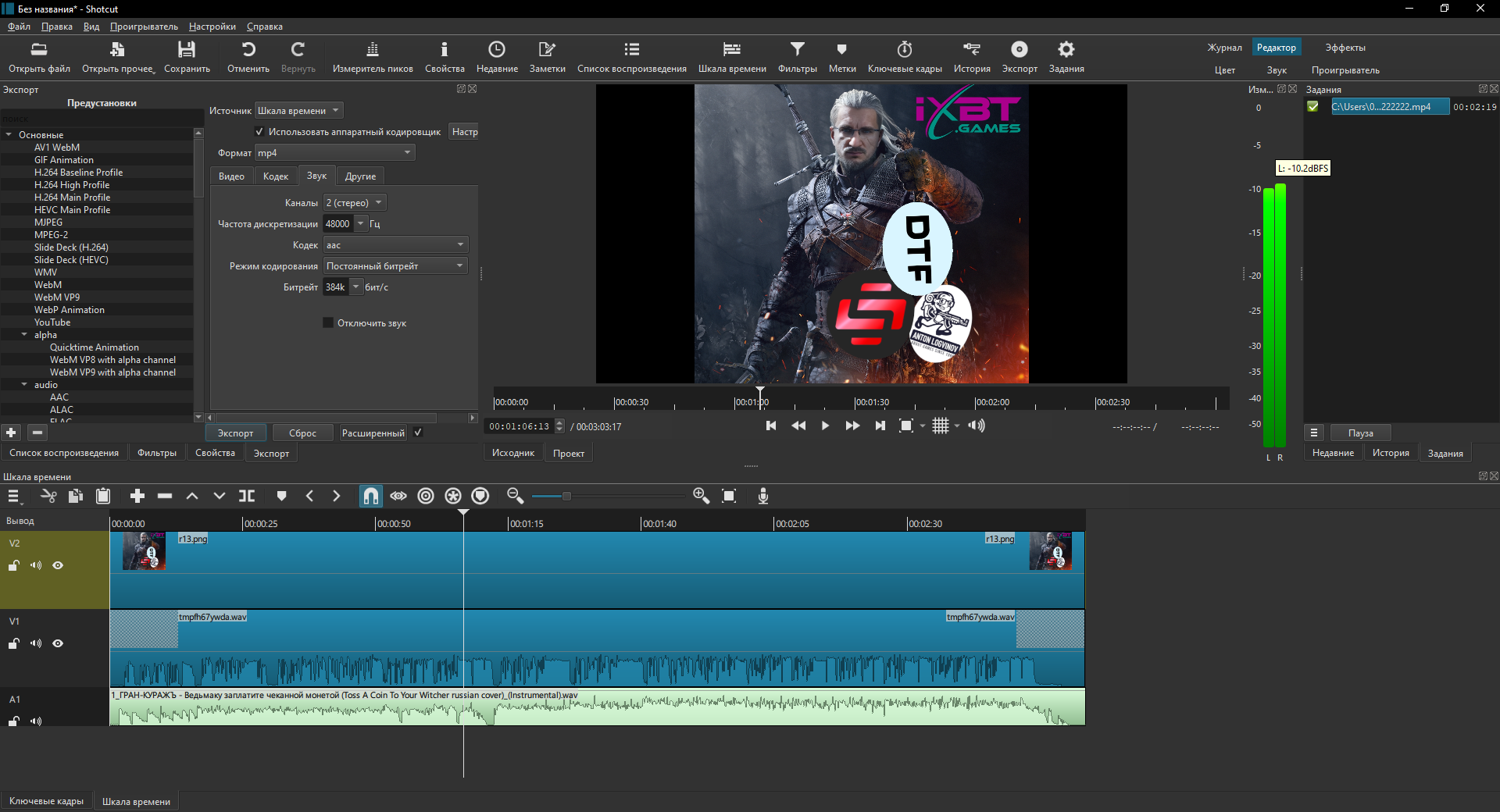
Наслаждаемся результатом.
Конечно, получилось немного с шероховатостями, но мне, если честно, было уже лень обучать модель нейронной сети выше 350 эпох и 8 минут датасета. Однако как пример работы технологии замены голоса вполне сгодится.
Замена голоса в реальном времени
Заменим свой голос, передаваемый напрямую через микрофон в режиме реального времени. Такая шалость идеально подойдёт для онлайн игр и сетевых мессенджеров по типу Discord и Skype.
1. Скачиваем бесплатную утилиту для подмены голоса в режиме реального времени.
Зеркало утилиты для подмены голоса.
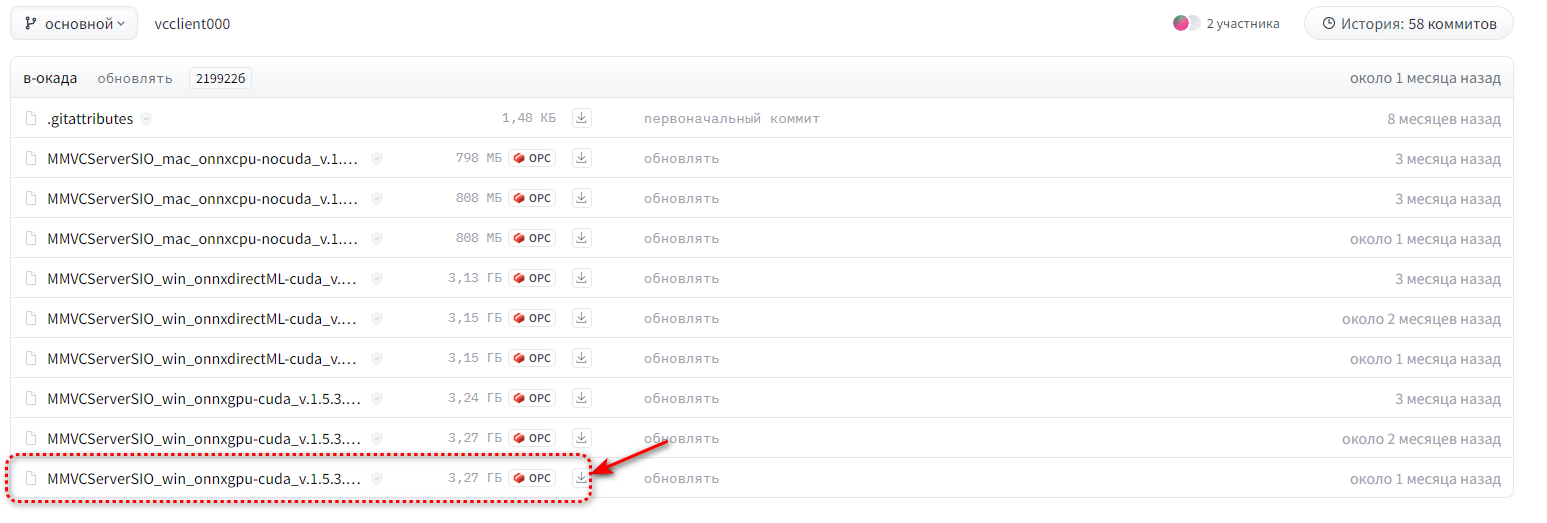
2. Скачиваем и устанавливаем драйвер ретранслятора звука Virtual Audio Cable (VAC) или его аналог Virtual Cable. У некоторых пользователей одна из двух программ может не работать. Лично я использую Virtual Audio Cable 4.67. Если всё в порядке, то после установки ПО и перезагрузки ПК в звуковом микшере Windows появится новое звуковое устройство.
3. Запускаем программу для подмены голоса через двойной клик по start_https.bat (Может не работать). В дальнейшем достаточно будет запускать ПО через MMVCServerSIO.exe.
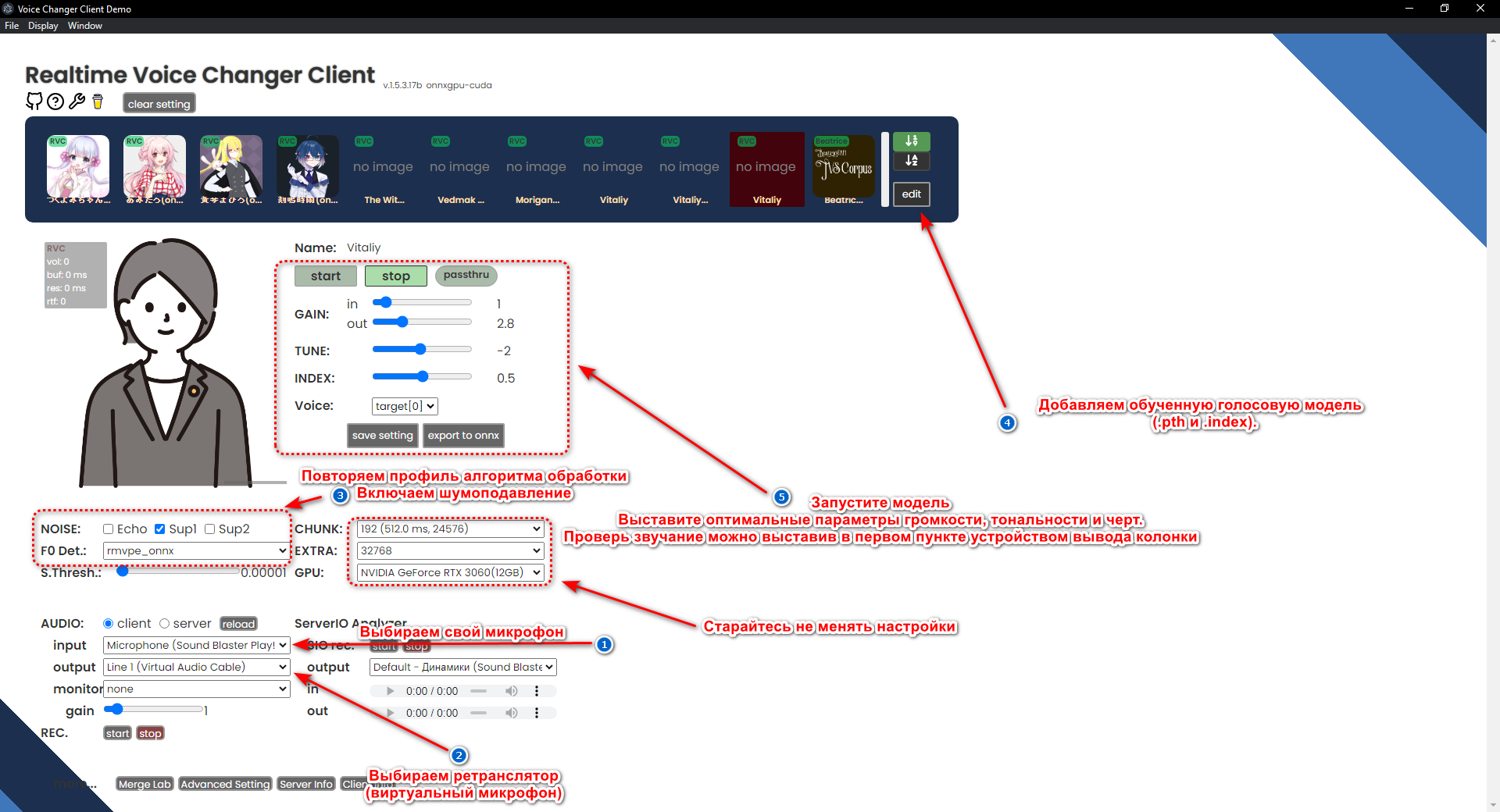
- Выбираем устройство ввода звука (микрофон).
- Выбираем виртуальный микрофон, добавленный Virtual Audio Cable (VAC) или его аналогом Virtual Cable.
- Выставляем оптимальные настройки выбора алгоритма обработки голоса, как на картинке выше.
- Добавляем профиль обученной голосовой модели.
- Настраиваем громкость, тон голоса, повторение тембра. (Услышать свой изменённый голос можно, выставив устройством вывода колонки/наушники).
- Выбираем виртуальный микрофон в игре или ПО и жмём Start.
Наслаждаемся результатом.
Получилось весьма натурально.
Заключение
Вот и настало «тёмное» цифровое будущее, когда знакомый голос по телефону или в мессенджере уже не является 100% гарантией узнаваемости человека на другом конце провода. Однако не стоит волноваться и бежать удалять записи своего голоса из интернета. Ведь нейронные сети — это всего лишь инструмент, использование которого зависит от человека, а человек — существо наказуемое. Уважайте свободу, используйте только проверенное ПО и ни в коем случае не позволяйте компаниям диктовать вам свои условия. С вами был Павел. Ещё увидимся!












104 комментария
Добавить комментарий
могу сказать, что качество из записи Ремейка музяки — потрясное.
Лучше, что я слышал на тему русскоязычных сеток.
И эта штука может позволить нам сделать то, что ранее мы считали невыполнимым на достойном, качественном уровне.
Прекрасная статья, очень ценная в определенных условиях.
Великолепная работа(я про то, что автор нашел и сам обучился и красиво, креативно сделал).
Найти такую ценную штуку для обычных, скромных индивидуалистов-творцов.
Надеюсь Виталий на ближайших стримах покажет это людям в массы.
А текст можно вводить разный.
В будущем в играх можно вообще на лету генерировать голос персонажа из текста, это увеличит нагрузку на систему, но зато уменьшит объем игры и позволить добавлять переводы на любые языки.
Какой-нибудь там Джони Депп и бац, например на хинди вещает. Своим собственным голосом.
Такое было бы круто.
---
Увы, в моем случае этот инструмент не подходит — системные требования не позволяют пользоваться.
Но инструмент интересный, спасибо.
(Железо Intel Xeon E5-2673 V.3 + RTX 3060 12 GB + 16 GB DDR 4)
Process Process-1:
Traceback (most recent call last):
File «multiprocessing\process.py», line 315, in _bootstrap
File «multiprocessing\process.py», line 108, in run
File «C:\VoicE\RVC_New\RVC_new\train_nsf_sim_cache_sid_load_pretrain.py», line 228, in run
train_and_evaluate(
File «C:\VoicE\RVC_New\RVC_new\train_nsf_sim_cache_sid_load_pretrain.py», line 452, in train_and_evaluate
loss_fm = feature_loss(fmap_r, fmap_g)
File «C:\VoicE\RVC_New\RVC_new\lib\train\losses.py», line 10, in feature_loss
loss += torch.mean(torch.abs(rl — gl))
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 12.00 GiB total capacity; 6.67 GiB already allocated; 4.08 GiB free; 6.86 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
А когда попробовал понизить пункт «Размер пачки для видеокарты» до «6», то получил такую ошибку:
RuntimeError: Caught RuntimeError in DataLoader worker process 0.
Original Traceback (most recent call last):
File «C:\VoicE\RVC_New\RVC_new\runtime\lib\site-packages\torch\utils\data\_utils\worker.py», line 308, in _worker_loop
data = fetcher.fetch(index)
File «C:\VoicE\RVC_New\RVC_new\runtime\lib\site-packages\torch\utils\data\_utils\fetch.py», line 54, in fetch
return self.collate_fn(data)
File «C:\VoicE\RVC_New\RVC_new\lib\train\data_utils.py», line 170, in __call__
phone_padded = torch.FloatTensor(
RuntimeError: [enforce fail at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\c10\core\impl\alloc_cpu.cpp:72] data. DefaultCPUAllocator: not enough memory: you tried to allocate 5492736 bytes.
UPD 2: И снова, спустя время и примерно 20-25 эпох — ошибка:
File «C:\VoicE\RVC_New\RVC_new\runtime\lib\site-packages\torch\multiprocessing\reductions.py», line 358, in reduce_storage
metadata = storage._share_filename_cpu_()
RuntimeError: Couldn't open shared file mapping: <000001C791CD00F2>, error code: <1455>
Process Process-1:
Traceback (most recent call last):
File «multiprocessing\process.py», line 315, in _bootstrap
File «multiprocessing\process.py», line 108, in run
File «C:\VoicE\RVC_New\RVC_new\train_nsf_sim_cache_sid_load_pretrain.py», line 228, in run
train_and_evaluate(
File «C:\VoicE\RVC_New\RVC_new\train_nsf_sim_cache_sid_load_pretrain.py», line 358, in train_and_evaluate
for batch_idx, info in data_iterator:
File «C:\VoicE\RVC_New\RVC_new\runtime\lib\site-packages\torch\utils\data\dataloader.py», line 634, in __next__
data = self._next_data()
File «C:\VoicE\RVC_New\RVC_new\runtime\lib\site-packages\torch\utils\data\dataloader.py», line 1346, in _next_data
return self._process_data(data)
File «C:\VoicE\RVC_New\RVC_new\runtime\lib\site-packages\torch\utils\data\dataloader.py», line 1372, in _process_data
data.reraise()
File «C:\VoicE\RVC_New\RVC_new\runtime\lib\site-packages\torch\_utils.py», line 644, in reraise
raise exception
RuntimeError: Caught RuntimeError in DataLoader worker process 0.
Original Traceback (most recent call last):
File «C:\VoicE\RVC_New\RVC_new\runtime\lib\site-packages\torch\utils\data\_utils\worker.py», line 308, in _worker_loop data = fetcher.fetch(index)
File «C:\VoicE\RVC_New\RVC_new\runtime\lib\site-packages\torch\utils\data\_utils\fetch.py», line 54, in fetch
return self.collate_fn(data)
File «C:\VoicE\RVC_New\RVC_new\lib\train\data_utils.py», line 164, in __call__
wave_padded = torch.FloatTensor(len(batch), 1, max_wave_len)
RuntimeError: [enforce fail at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\c10\core\impl\alloc_cpu.cpp:72] data. DefaultCPUAllocator: not enough memory: you tried to allocate 2054400 bytes.
Места на SSD — в достатке, около 100 ГБ свободных, из них пока только 1-2 заняты файлами модели. Не пойму, что не так, за исключением того, что «не хватает памяти»… Эпох ставил 300, частоту сохранения — 10.
Вот например, только закончил делать.
https://www.youtube.com/watch?v=4l3S06r1Mt0
Тренировал голос около 1000 эпох для озвучки аудиокниг голосом автора.
Как результат — не очень. Тембр голоса да, похож. Но, так как для накладки используется претренированный на английском датасете русский голос. При озвучке текста TTS много неправильных ударений в словах, а также интонации в вопросах, соответсвующие английскому языку. И управлять и изменять это невозможно.
То есть это не клонирование, а некоторая похожесть. Для баловства в накладке для песен подойдет, т.к. музыкальный фон может сгладить артефакты.
По сути, амплитудный рельеф оригинала и его фундаментальная частота используются, как опора для синтеза новой сущности, с приложением нового голоса, с его родным тембром, чтобы масиксимально приблизить «нового» исполнителя к «старому».
2024-01-28 17:46:58 | WARNING | xformers | A matching Triton is not available, some optimizations will not be enabled.
Error caught was: No module named 'triton'
2024-01-28 17:46:58 | WARNING | xformers | Triton is not available, some optimizations will not be enabled.
This is just a warning: No module named 'triton'
Found GPU NVIDIA GeForce GTX 1650, force to fp32
Use Language: en_US
Running on local URL: http://0.0.0.0:7897
runtime\python.exe trainset_preprocess_pipeline_print.py «C:\Dataset» 40000 4 «C:\D\Новая папка (2)\RVC_new/logs/mi-test» False
['trainset_preprocess_pipeline_print.py', 'C:\\Dataset', '40000', '4', 'C:\\D\\Новая папка (2)\\RVC_new/logs/mi-test', 'False']
start preprocess
['trainset_preprocess_pipeline_print.py', 'C:\\Dataset', '40000', '4', 'C:\\D\\Новая папка (2)\\RVC_new/logs/mi-test', 'False']
Traceback (most recent call last):
File «C:\D\Новая папка (2)\RVC_new\trainset_preprocess_pipeline_print.py», line 139, in
preprocess_trainset(inp_root, sr, n_p, exp_dir)
File «C:\D\Новая папка (2)\RVC_new\trainset_preprocess_pipeline_print.py», line 133, in preprocess_trainset
println(sys.argv)
File «C:\D\Новая папка (2)\RVC_new\trainset_preprocess_pipeline_print.py», line 26, in println
f.write("%s\n" % strr)
File «encodings\cp1252.py», line 19, in encode
UnicodeEncodeError: 'charmap' codec can't encode characters in position 79-83: character maps to
start preprocess
Triton is not available, some optimizations will not be enabled. This is just a warning: No module named 'triton'
Первый шаблон был на 500 эпох, со средней обработкой в районе 26 сек. Файлом было голосовое сообщение из тг.
Решил сделать второй: в независимости от длины аудио (аудио одно и то же, пытался обработать 5 мин и 10 мин), средняя обработка эпохи в районе 2х минут. Объем файла 5мб. Аудиодорожка из видео в хорошем качестве без посторонних шумов.
i5 12400f + 16gb 3600 + 3070ti (8гб видеопамяти).
Судя по мониторингу, видеопамять заполнена полностью, загрузка 99%, ОЗУ стабильно на 12гб из 16, ЦП загружен на 30-40%.
D:\voice neuro\RVC_new\RVC_new\runtime\lib\site-packages\torch\functional.py:641: UserWarning: stft with return_complex=False is deprecated. In a future pytorch release, stft will return complex tensors for all inputs, and return_complex=False will raise an error.
Note: you can still call torch.view_as_real on the complex output to recover the old return format. (Triggered internally at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\native\SpectralOps.cpp:867.)
return _VF.stft(input, n_fft, hop_length, win_length, window, # type: ignore[attr-defined]
D:\voice neuro\RVC_new\RVC_new\runtime\lib\site-packages\torch\functional.py:641: UserWarning: stft with return_complex=False is deprecated. In a future pytorch release, stft will return complex tensors for all inputs, and return_complex=False will raise an error.
Note: you can still call torch.view_as_real on the complex output to recover the old return format. (Triggered internally at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\native\SpectralOps.cpp:867.)
return _VF.stft(input, n_fft, hop_length, win_length, window, # type: ignore[attr-defined]
что делать?
F:\AI\RVC_New>runtime\python.exe infer-web.py --pycmd runtime\python.exe --port 7897
Python path configuration:
PYTHONHOME = (not set)
PYTHONPATH = (not set)
program name = 'runtime\python.exe'
isolated = 1
environment = 1
user site = 1
import site = 1
sys._base_executable = 'F:\\AI\\RVC_New\\runtime\\python.exe'
sys.base_prefix = 'F:\\AI\\RVC_New\\runtime'
sys.base_exec_prefix = 'F:\\AI\\RVC_New\\runtime'
sys.platlibdir = 'lib'
sys.executable = 'F:\\AI\\RVC_New\\runtime\\python.exe'
sys.prefix = 'F:\\AI\\RVC_New\\runtime'
sys.exec_prefix = 'F:\\AI\\RVC_New\\runtime'
sys.path = [
'F:\\AI\\RVC_New\\runtime\\python39.zip',
'F:\\AI\\RVC_New\\runtime',
]
Fatal Python error: init_fs_encoding: failed to get the Python codec of the filesystem encoding
Python runtime state: core initialized
ModuleNotFoundError: No module named 'encodings'
Current thread 0x00005ebc (most recent call first):
F:\AI\RVC_New>pause
Для продолжения нажмите любую клавишу.. .
Скрин: https://disk.yandex.ru/i/3fJAerzSOQk0oQ
C:\WINDOWS\system32>runtime\python.exe infer-web.py --pycmd runtime\python.exe --port 7897
Системе не удается найти указанный путь.
C:\WINDOWS\system32>pause
Для продолжения нажмите любую клавишу...
Triton is not available, some optimizations will not be enabled. This is just a warning: No module named 'triton'
что за тритон? я уже скачал какой-то файл с гитхаба, но куда его деть…
paramDict {'voiceChangerType': 'RVC', 'slot': 5, 'isSampleMode': False, 'sampleId': None, 'files': [{'name': 'G_2333333.pth', 'kind': 'rvcModel', 'dir': ''}, {'name': 'trained_IVF20_Flat_nprobe_1_lina_v2.index', 'kind': 'rvcIndex', 'dir': ''}], 'params': {}}
RVC:: slotInfo.modelFile G_2333333.pth
[Voice Changer] post_load_model ex: 'config'
Traceback (most recent call last):
File «restapi\MMVC_Rest_Fileuploader.py», line 92, in post_load_model
File «voice_changer\VoiceChangerManager.py», line 170, in loadModel
File «voice_changer\RVC\RVCModelSlotGenerator.py», line 37, in loadModel
File «voice_changer\RVC\RVCModelSlotGenerator.py», line 43, in _setInfoByPytorch
KeyError: 'config'
Уже что только не пробовал.
Нужно загружать модель из папки «weights».
Upd: сделал разгон вместо андерклока (2610 мгц --> 2940 мгц и -300 по памяти --> +1000) и 30 сек сократились до 20-22
Traceback (most recent call last):
File «Y:\RVC_new\lib\audio.py», line 14, in load_audio
ffmpeg.input(file, threads=0)
File «Y:\RVC_new\runtime\lib\site-packages\ffmpeg\_run.py», line 325, in run
raise Error('ffmpeg', out, err)
ffmpeg._run.Error: ffmpeg error (see stderr output for detail)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File «Y:\RVC_new\infer-web.py», line 188, in vc_single
audio = load_audio(input_audio_path, 16000)
File «Y:\RVC_new\lib\audio.py», line 19, in load_audio
raise RuntimeError(f«Failed to load audio: {e}»)
RuntimeError: Failed to load audio: ffmpeg error (see stderr output for detail)
Traceback (most recent call last):
File «Y:\RVC_new\runtime\lib\site-packages\gradio\routes.py», line 321, in run_predict
output = await app.blocks.process_api(
File «Y:\RVC_new\runtime\lib\site-packages\gradio\blocks.py», line 1007, in process_api
data = self.postprocess_data(fn_index, result[«prediction»], state)
File «Y:\RVC_new\runtime\lib\site-packages\gradio\blocks.py», line 953, in postprocess_data
prediction_value = block.postprocess(prediction_value)
File «Y:\RVC_new\runtime\lib\site-packages\gradio\components.py», line 2076, in postprocess
processing_utils.audio_to_file(sample_rate, data, file.name)
File «Y:\RVC_new\runtime\lib\site-packages\gradio\processing_utils.py», line 206, in audio_to_file
data = convert_to_16_bit_wav(data)
File «Y:\RVC_new\runtime\lib\site-packages\gradio\processing_utils.py», line 219, in convert_to_16_bit_wav
if data.dtype in [np.float64, np.float32, np.float16]:
AttributeError: 'NoneType' object has no attribute 'dtype'
но постонно ошибка в переработке данных
Голос длится 30 минут, загрузил в папку С датасет, но ошибка Connektion errored out
WARNING | xformers | Triton is not available, some optimizations will not be enabled.
This is just a warning: No module named 'triton'
Добавить комментарий