Как не попасться на дипфейки: научные методы распознавания голоса
В наше время интернет полон ложной и искаженной информацией, которая может вводить в заблуждение и манипулировать общественным мнением. Особенно опасны так называемые дипфейки — подделки аудио и видео, созданные с помощью искусственного интеллекта (AI). Дипфейки могут имитировать голос и облик любого человека, будь то политик, знаменитость или ваш близкий родственник. Такие подделки могут использоваться для шантажа, мошенничества, дезинформации или просто для развлечения.

Но как отличить реальный голос от клонированного? Есть ли способы, которые помогут нам не попасться на уловки дипфейков? На эти вопросы пытаются ответить исследователи из Школы информации при Калифорнийском университете в Беркли. Сара Баррингтон, Ромит Баруа и Гаутам Курма (все MIMS '23) представили свою работу по обнаружению клонированного голоса на нескольких научных конференциях, включая Нобелевский саммит и конференцию IEEE WIFS (Workshop in Information Forensics and Security) в Нюрнберге, Германия.
Исследователи работали под руководством профессора Хани Фарида, эксперта в области цифровой криминалистики и борьбы с дипфейками. Профессор Фарид признал, что он был удивлен скоростью и качеством развития технологии клонирования голоса, которая стала «потрясающе хорошей» за несколько месяцев. По его словам, команда сделала важный вклад в разработку методов обнаружения новой угрозы дипфейков аудио.
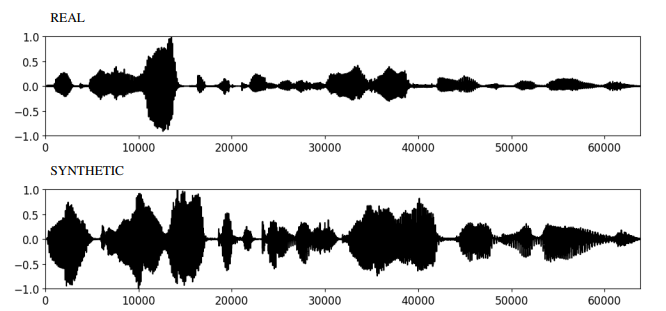
Команда применила три разных подхода для анализа аудиопроб реальных и поддельных голосов. Первый подход заключался в изучении воспринимаемых особенностей или паттернов, которые можно визуально (или на слух) идентифицировать. Например, реальные человеческие голоса часто имеют больше пауз и различаются по громкости на протяжении всего клипа, в то время как клонированные голоса более ровные и однообразные. Этот метод легко понять, но может давать менее точные результаты.
Второй подход заключался в использовании спектрального анализа с помощью специальной программы, которая извлекает более 6 000 характеристик из аудиоволн, таких как среднее, стандартное отклонение, коэффициенты регрессии
Третий подход основан на использовании модели глубокого обучения, которая принимает на вход сырое аудио и обрабатывает его, извлекая многомерные представления, называемые вложениями. Эти вложения используются для различения реального и «синтетического» аудио. Этот метод показал самые высокие показатели точности и даже достигал нулевой ошибки в лабораторных условиях. Однако этот метод сложнее понять и объяснить, так как он основан на сложных математических операциях.
Исследователи считают, что их работа может помочь защитить общественность от злоупотребления технологией клонирования голоса, которая хоть и может быть полезным инструментом для творчества, но в руках злоумышленников способна принести несоизмеримо больший вред. «Клонирование голоса — это один из первых случаев, когда мы сталкиваемся с дипфейками, имеющими реальную угрозу, будь то обход биометрической верификации банка или звонок родственнику с просьбой о деньгах», — сказала Баррингтон. «Теперь под угрозой не только мировые лидеры и знаменитости, но и обычные люди».
Поэтому важно развивать и совершенствовать методы обнаружения дипфейков, которые будут надежными и масштабируемыми для широкой публики. Исследователи надеются, что их работа способствует восстановлению доверия к аудиоконтенту в интернете и снижению рисков, связанных с развитием технологий. Они также планируют продолжать свои исследования в этой области и сотрудничать с другими учеными в поиске лучших решений.











3 комментария
Добавить комментарий
Добавить комментарий