5 полезных и интересных нейросетей на Hugging Face
Искусственный интеллект продолжает активно развиваться, предлагая всё более мощные и разнообразные инструменты для решения различных задач. Платформа Hugging Face предоставляет бесплатный доступ к множеству нейросетей, которые могут значительно упростить и улучшить работу в различных областях. В этой статье я рассмотрю пять полезных и интересных нейросетей, доступных на Hugging Face. Каждая из этих моделей имеет свои уникальные возможности и области применения, от обработки аудио и генерации звуков до редактирования изображений и создания анимаций. Я подробно рассмотрю, как использовать эти модели и в каких сценариях они могут быть наиболее полезны.

Что такое Hugging Face?
Hugging Face — это онлайн-сообщество, где разработчики и исследователи делятся своими моделями машинного обучения, делая их доступными для всех. Это позволяет любому человеку использовать передовые технологии для своих проектов, будь то обработка текста, аудио или изображений.
OmniAudio
Модель OmniAudio-2.6B от NexaAIDev — это аудио-языковая модель, предназначенная для обработки аудио и текста на устройствах с ограниченными ресурсами. Она объединяет функции распознавания речи и языковых моделей, обеспечивая высокую скорость и качество обработки.
Переходим в пространство OmniAudio, выбираем способ загрузки аудиофайла: запись с микрофона или готовый файл. Затем можно выбрать максимальное количество слов для ответа (от 50 до 200). Для запуска нажимаем на кнопку «Submit».
В зависимости от длины аудиофайла обработка займет около 10-40 секунд. На выходе получаем ответ на текст в аудио.
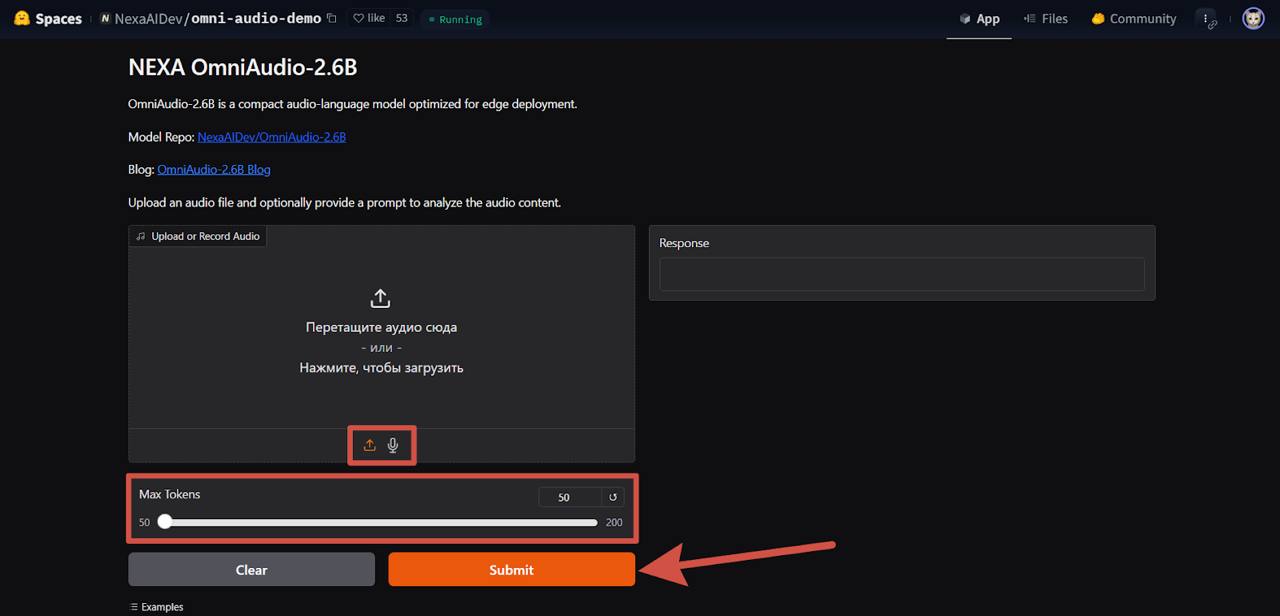
Модель позволяет решать большое количество задач. К примеру, это может быть ответ на голосовые сообщения пользователей. Также есть возможность анализировать записанные аудиофайлы и использовать ответ для дальнейшей обработки.
TangoFlux
Модель TangoFlux от Declare-lab — это модель для генерации аудио из текста, которая может создавать аудиофайлы длительностью до 30 секунд. Она использует текстовые промты для генерации высококачественного аудио.
В пространстве TangoFlux слева можно ввести и изменить следующие параметры:
• текстовый промт (краткое или подробное описание желаемого результата на английском языке);
• количество шагов для генерации;
• соответствие заданному промту;
• длина аудиозаписи.
Справа отображается процесс обработки информации, примерное время для генерации, а затем уже и результат, который можно скачать.
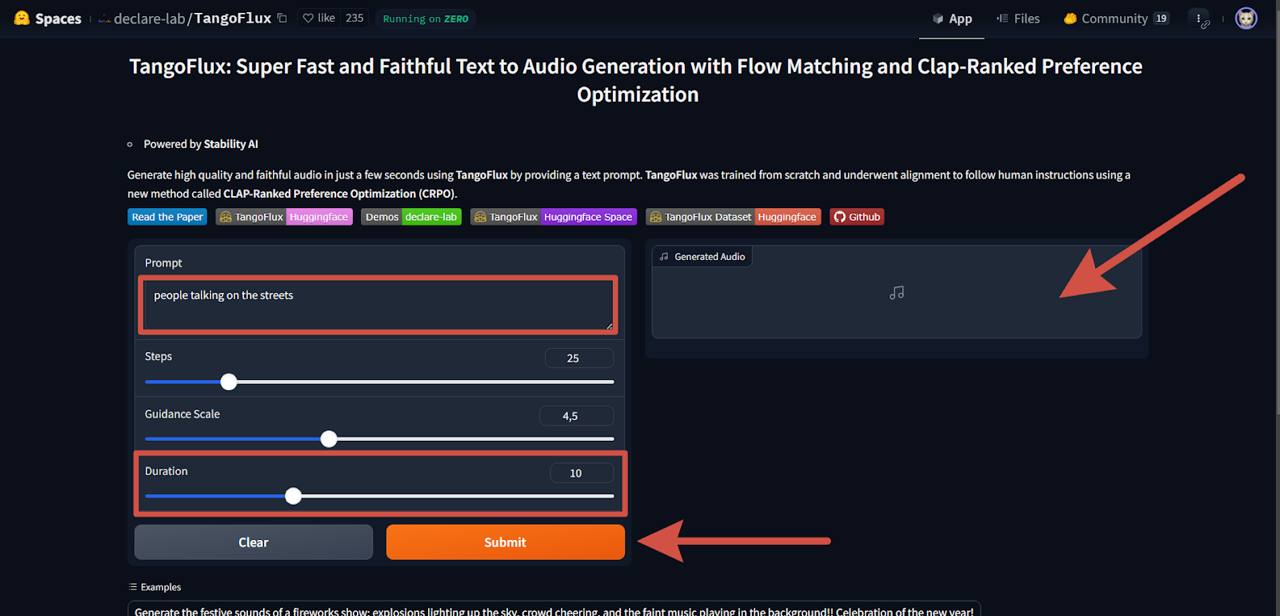
Модель можно использовать для генерации фоновых звуков в совершенно разных сферах: рекламные ролики, игры и приложения, аудиокниги, подкасты и другие. Также видеоконтент в любой из областей может нуждаться в сопровождении фоновых звуков.
Whisper Jax
Модель Whisper-JAX от Sanchit Gandhi — это улучшенная версия модели Whisper от OpenAI, работающая на JAX. Она предназначена для быстрой и точной транскрипции аудио в текст.
Переходим на в пространство Whisper Jax и сверху выбираем, откуда будет поступать аудио: запись с микрофона, файл или ссылка на YouTube видео.
В зависимости от выбранного способа подгружаем исходный файл, затем нажимаем на кнопку «Submit». Справа будет отображаться расшифровка текста и время, затраченное на расшифровку. Учтите, что в моменты большой нагрузки ожидание может занять больше, чем обычно, так как файл находится в очереди на обработку.
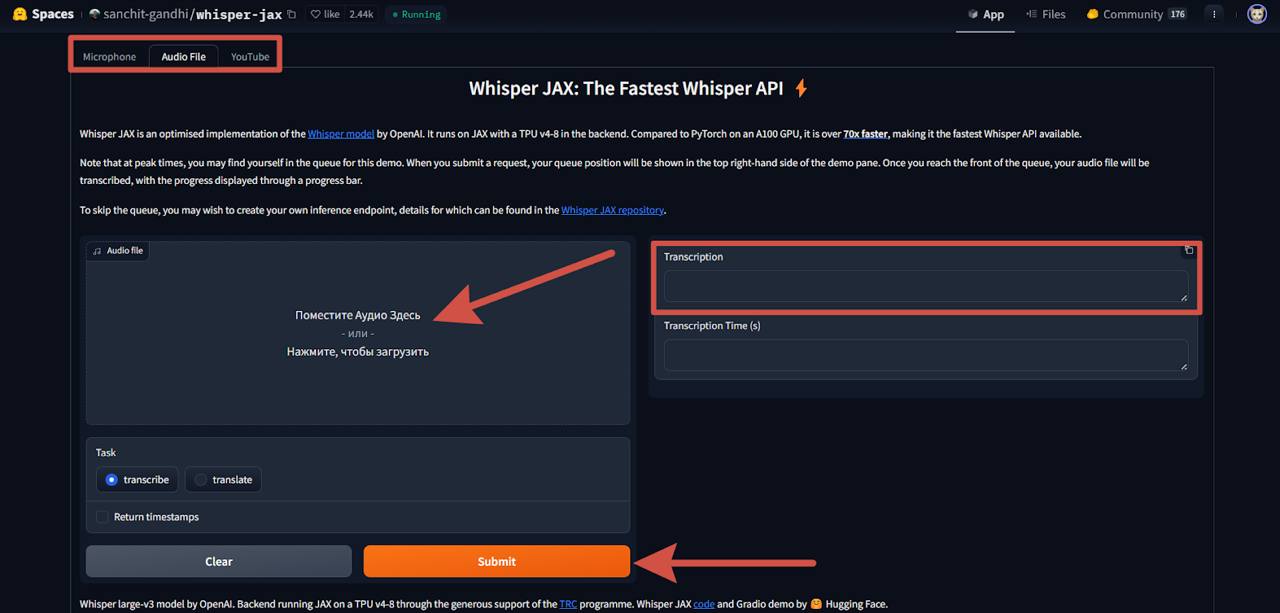
Расшифровка текста из аудио уже имеет применение во многих областях: создание субтитров, транскрипция интервью, лекций и любых аудиозаписей с дальнейшей обработкой текста.
Magic Quill
Модель MagicQuill от AI4Editing — это интеллектуальная интерактивная система для редактирования изображений, которая позволяет пользователям легко и точно вносить изменения в изображения. Система использует интуитивно понятные кисти для добавления, удаления и изменения цвета элементов, а также мультимодальную языковую модель для предсказания намерений пользователя в реальном времени. Это делает процесс редактирования более удобным и эффективным для пользователей всех уровней навыков.
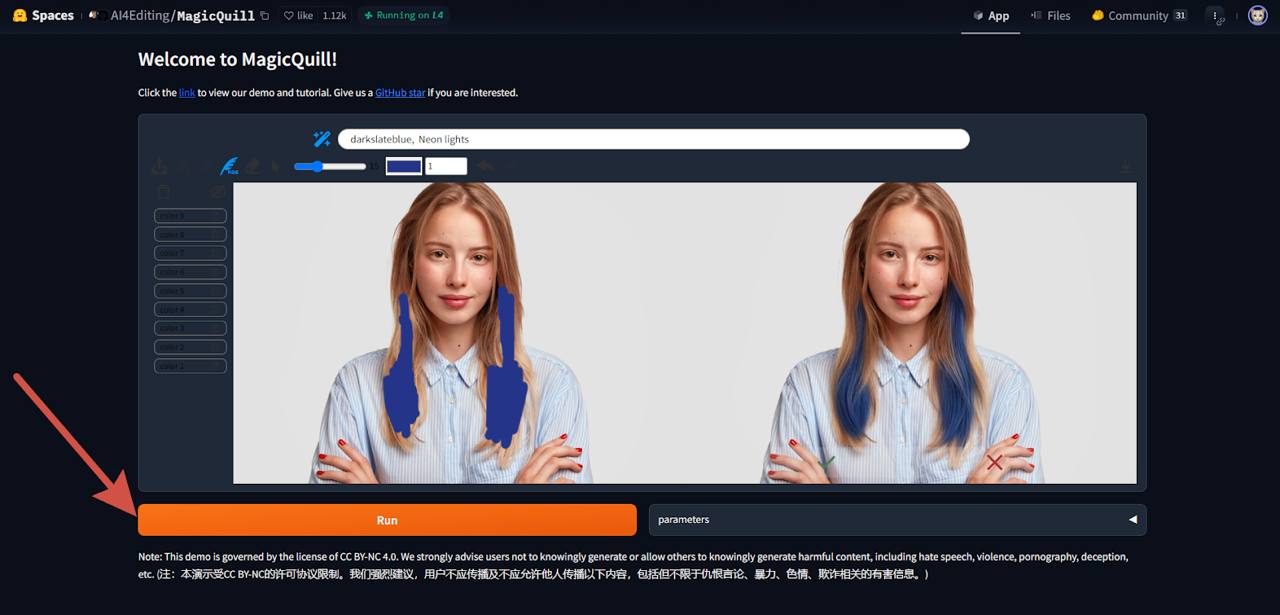
Переходим в MagicQuill и загружаем фотографию. Затем выбираем нужную кисть, например, с цветом. Раскрашиваем то, что хотим изменить на фото, а после нажимаем на кнопку «Run».
В зависимости от нагрузки на сервера обработка займет от нескольких секунд до пары минут. Результат очень реалистичен и картинка выглядит естественно.
Также есть возможность добавить что-либо на фото. Выбираем нужную кисть и рисуем то, что хотим видеть на фото. Сверху есть текстовое описание, которое появляется с помощью ИИ. Если оно не совпадает с тем, что вы нарисовали, текст можно поменять вручную.
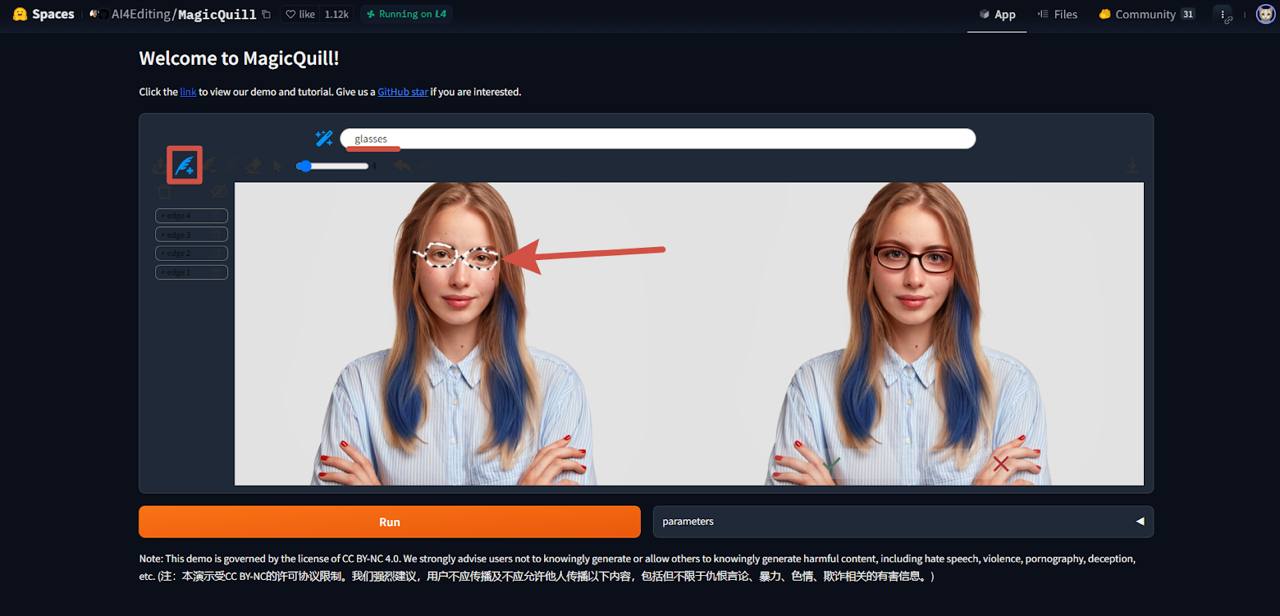
Модель значительно расширяет возможности в сфере редактирования фотографий, создании графики, обработки изображений, дизайнерских и обучающих целей.
Manimator
Модель Manimator от HyperCluster — это инструмент на базе искусственного интеллекта, предназначенный для создания анимаций. Он преобразует научные статьи и математические концепции в наглядные и доступные видео, что делает сложные темы понятными для широкой аудитории.
В пространстве Manimator вводим текстовый промт, а затем нажимаем на кнопку «Generate Animation from Text».
Сама генерация занимает от пары до десяти минут в зависимости от тематики и написанного вами промта. В условиях простоты использования и получаемого результата ожидание того стоит.
Протестировав разные текстовые описания, я могу сделать несколько выводов.
• Тематика должна иметь способы визуального представления: диаграммы, формулы, текст, графические объекты.
• Широкие запросы по теме дают более короткие и общие результаты.
• Структурированные запросы с кратким описанием необходимых подтем дают более ожидаемые результаты.
Использование модели ограничивается более узким спектром применения, но очень полезна в обучении: наглядное объяснение всегда отлично дополняет устное разъяснение. Поэтому если вы связаны с популяризацией науки или у вас есть проекты, связанные с созданием видеоконтента, модель определенно для вас.
Для тех, кто находится в поиске подходящего телевизора, советую посмотреть подборки:
Источник: mistral.ai











0 комментариев
Добавить комментарий
Добавить комментарий