Почему боты в играх не умнеют?
Полагаю, многие уже наслышаны, как в последние годы разрабатываются системы искусственного интеллекта (ИИ), которые обыгрывают людей в различные компьютерные игры. И с каждым годом число таких игр растёт. Однако даже в выходящих в настоящее время блокбастерах всё это развитие абсолютно незаметно, и боты от года к году становятся только тупее.
Некоторые задаются вопросом, с чем это связано и не врут ли нам создатели всех этих новых систем об их способностях. Не сидит ли где то в секретной комнате таких компаний некий китаец, который просто обыгрывает других игроков под видом программы.

На самом деле, в большей степени недопонимание связано с тем, что многие люди воспринимает такие системы именно как полноценный искусственный интеллект, в то время как это автоматизированный интеллект, который способен выполнять лишь ограниченный спектр задач, которым он был обучен. Проще говоря, многие люди ожидают от таких систем не то, на что они по-настоящему способны, при этом недооценивая их истинный потенциал. Однако же есть и ряд чисто технических проблем, которые мешают внедрению подобных систем в качестве ботов в игры. Далее будет представлен небольшой обзор современного уровня развития таких систем и небольшой взгляд в будущее на то, как компьютерные боты могут развиться в ближайшие годы.
Итак, если мы хотим понять, в чём проблема внедрения современных систем ИИ в игры, надо понять, как они работают. К системам ИИ стоит относить те методы и алгоритмы, которые симулируют одну или несколько когнитивных способностей, свойственных живым организмам. При этом эти алгоритмы совершенно не обязательно должны быть аналогичными тем, которые используют живые организмы. К примеру, система, распознающая контуры предметов на фотографии, будет являться системой ИИ, поскольку задача распознавания является когнитивной. Но вот большинство ботов в современных играх к ИИ отнести в полной мере нельзя, поскольку они работают по строгому алгоритму, где на конкретное действие игрока бот реагирует конкретным образом. Никаких когнитивных задач не решается. Отсюда же проистекает и современное отупение ботов. Людям с каждым годом дают всё больше возможностей в играх. Дерево поведения ботов всё больше растёт и усложняется, и всё чаще можно наткнуться на ситуации, не предусмотренные этим деревом. Подобная система уже сейчас выглядит весьма устаревшей, но в свете отсутствия более продвинутых аналогов используется до сих пор.
Так что, когда где-то видите новость про добавление в игры ИИ, стоит критически к этому относиться и понимать, что внедряют скорее всего крайне узкоспециализированную систему. Опять же, поскольку подобные системы очень эффективны в анализе массивов разнородной информации, ИИ уже давно и основательно используется для удержания игроков в онлайн-играх и мотивации их на траты во free-to-play играх, поскольку поведение людей зачастую довольно легко предсказать и направить в нужное русло.

Однако же не будем о грустном и поговорим именно о тех системах, которые могут симулировать игрока и стать оппонентом в играх. В настоящее время существует огромное количество алгоритмов ИИ, которые способны симулировать то или иное поведение человека. Если описывать их все, упоминая их сильные и слабые стороны, выйдет очень большая статья. Поэтому я сконцентрируюсь именно на той архитектуре, которая у людей на слуху и является наиболее продвинутой, в данной области – искусственных нейронных сетях (ИНС). Именно на этой архитектуре созданы небезызвестные AlphaGo, AlphaZero и AlphaStar, которые побеждали людей в го, сёги и StarCraft. Почему же одну из этих систем нельзя внедрить и в другие игры, в качестве игрового бота? Ответ на этот вопрос кроется в архитектуре и способе создания таких систем.

Прежде всего, нужно понимать, что ИНС это не линейный алгоритм, а действительно сеть, с огромным количеством связанных между собой искусственных нейронов. Каждый нейрон получает сигналы от сотен нейронов и сотням же других нейронов передаёт. Итогом этого становится то, что такие сети, по большому счёту — чёрный ящик, поведение которого предсказать невозможно, если не написать программу в десятки раз больше и сложнее для анализа созданной сети.
Более того, такая сеть в процессе создания модифицирует сама себя. Те же ИНС серии Alpha вообще не статичны, они обучаются методом подкрепления. Это означает что они, подобно человеческому мозгу, изменяют себя каждый раз, когда к ним поступает какой то сигнал. Такой подход является основным достоинством сетей – они способны найти то решение, которое человек может искать годами. И, в отличие от линейных алгоритмов, сети могут найти такое решение, которое ни один человек до этого не находил. К тому же они способны реагировать на изменяющиеся условия и подстраиваться под новые правила. Именно эти достоинства помогли им обыграть людей. Но в этом скрыт и один из основных недостатков для разработчиков игр – поведение таких сетей невозможно спрогнозировать полностью. Точно будет известно только поведение сети в тех ситуациях, на которых она обучалась и тестировалась. Но вот как она поведёт себя в новых ситуациях, до конца неизвестно.
Всегда можно научить ИНС играть в какую то игру. Но чтобы сеть лучше в неё играла, ей надо предоставить как можно больше игровых ситуаций. Чем больше игровых ситуаций сеть разберёт, тем более сложным будет её поведение. Она будет «помнить» опыт прошлых игр. С каждой новой выученной ситуацией, на старые она будет реагировать уже по-другому. И если мы говорим о сети, которая сможет играть на уровне человека, мы должны говорить о сети, обученной на миллионах игровых ситуаций.
Тут мы приходим к тому, что тестирование поведения такой сети потребует больше человеко-часов, чем любой современный блокбастер целиком. Более того, если какой-то баг в поведение сети и будет найден, её не получиться поправить, как линейный алгоритм. Этот баг нужно будет разобрать, включить в обучающую выборку и обучить новую сеть. И её снова нужно будет протестировать с нуля, потому что поведение сети может измениться в любой из тестируемых ситуаций. Безусловно, существуют подходы, которые немного ускоряют этот процесс, но ни один из них в корне его не меняет. Уже можно предположить, насколько ресурсоёмкая разработка такого бота, и почему такие сети делают по нескольку лет.

Подобная проблема не столь критична для ИНС, которая обучается для того, что бы просто победить игрока-человека. Но компьютерные игры создаются не для того, что бы человек стабильно умирал от первого же моба. И обучить сеть, которая будет пытаться победить игрока, поддаваясь в некоторых ситуациях — уже совершенно другая задача.
Уже на данном этапе разработка бота на базе ИНС выглядит нерентабельной, но есть ещё проблемы. Сейчас, если ИНС обучается играть в какую то игру, то она, по сути, представляет из себя самостоятельную «личность», которая играет по своим тактикам и ведёт себя определённым образом, исходя из того, как она была обучена. И вот тут всплывает такой момент, что для того, что бы изменить её поведение, к примеру, чтобы она могла симулировать бота другой сложности, нужно её дообучить на дополнительных данных.
И вот уже, чтобы получить ботов для разной сложности игры, нам требуется создать и протестировать несколько нейронных сетей. А ведь в играх редко бывает один тип мобов. И поведение, к примеру, вертолёта прилично отличается от поведения пехотинца. Нам нужны отдельные сети для разных мобов на разных сложностях. А ведь ещё могут быть разные карты, на которых геймплей отличается, и разные режимы игры, где победы нужно добиваться разными путями. Проблема возрастает в геометрической прогрессии.
Казалось бы, почему не обучить одну сеть, способную симулировать разных мобов и способную играть на разных сложностях игры в разных игровых ситуациях? Ну, помимо того, что создание такой сети по силам лишь нескольким корпорациям в мире, мы упираемся в ещё одну существенную проблему – обучающие данные. Любые системы ИИ не являются магической шкатулкой, которой надо задать лишь цель, и она сама найдёт путь. Чтобы ИИ мог достичь цели, ему надо объяснить как это сделать. И, в случае с ИНС, этим объяснением являются данные, отображающие состояние объекта моделирования и среды, в которой объект функционирует.
Сеть должна знать, при каких условиях объект обладает определёнными характеристиками, и как среда реагирует на те или иные действия объекта. Проще говоря, для сети нужно расписать всю «жизнь» игрового персонажа от «рождения» до «смерти». И расписать так, будто он побывал во всех возможных игровых «приключениях». Естественно, приключение, где герой будет убивать босса копьём, будет существенно отличаться от приключения, где тот же самый герой будет убивать того же самого босса уже луком. Или магией. А теперь представьте, сколько ситуаций нужно описать для бота, который должен одновременно симулировать поведение сотни разных юнитов в огромной армии. Именно из-за этой проблемы тот же AlphaStar, в своих последних версиях, всё равно мог играть только в одном режиме StarCraft II — Protoss versus Protoss. Всего одной конкретной фракцией против другой конкретной фракции.
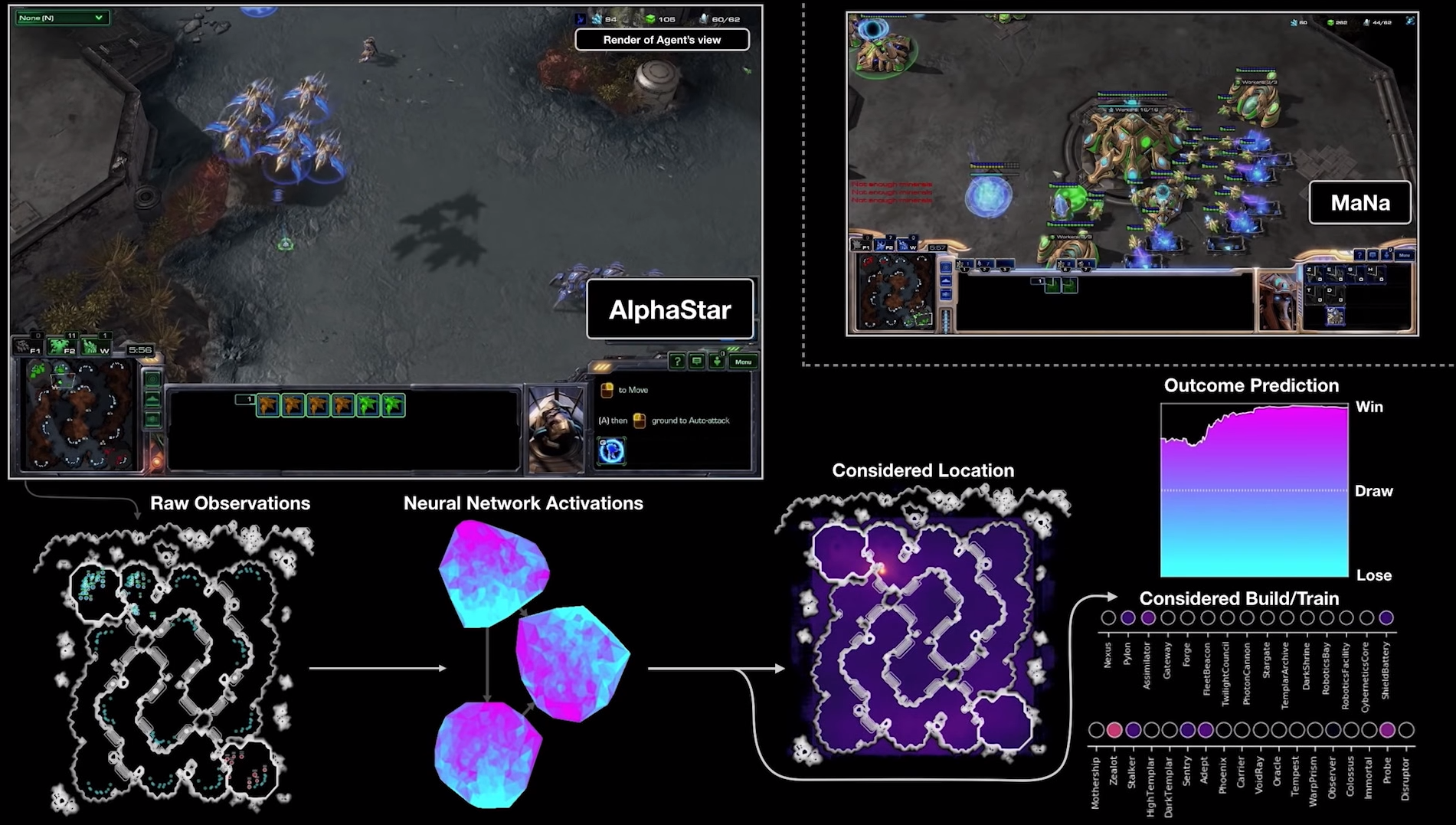
В итоге, оказывается, что даже самые продвинутые в плане игровых возможностей системы ИИ, всё ещё очень далеки от внедрения в современные игры. Топорные деревья решений, которые применяются уже не первое десятилетие, пока остаются единственным оправданным алгоритмом для описания поведения ботов. Но когда нам теперь ждать новый виток развития интеллекта игровых болванчиков? Возможно, не так долго, как кажется на первый взгляд.
В конце концов, кто сказал, что обучать системы ИИ обязательно должен человек? Ещё в 2017 году Deepmind представил версию AlphaGo Zero которая обучалась игре в го не на основе игровых партий людей, а играя сама с собой. И уже тогда она стала одной из самых успешных ИИ для игры в го, превзойдя человека. Безусловно, чем сложнее сама игра, чем больше игровых правил и условий, тем сложнее устраивать подобные спарринги между ИИ. Но это не невозможно, хоть и требует огромных вычислительных мощностей. Отдать тестирование ИИ на откуп других ИИ сложнее, но частично эту проблему можно обойти за счёт введение дополнительных условий в обучение.
И всё же, основной проблемой на данном пути остаются вычислительные ресурсы, которые требуются для обучения таких ИИ. Так что следующий скачок в этом направлении можно ожидать не раньше скачка в области вычислительных систем.











50 комментариев
Добавить комментарий
Ну да ладно, у меня тема несколько другая. Вернее, как: объект исследования у нас один, а предметы разные. Но ссылку на твою статью я к себе вставлю)
Второй защелкал кнопочками. На экране навстречу герою выбежала толпа вооруженных дубинами орков с громким криком «Wa-a-agh!!!», и пала в полминуты.
-Туповатые они какие-то,- скривился Первый.- Поставь побольше.
Второй перевёл ползунок на одно деление. Орки попрятались в кустах и за камнями, стали нападать со спины, устраивать обвалы, засады и ловчие ямы. Через пятнадцать минут Первый вытер вспотевший лоб и уважительно хмыкнул.
-Неплохо, неплохо. Но всё-таки не то. А если им дать еще чуть-чуть?
Через десять минут шкура героя сушилась на частоколе возле орочьей деревни. Первый нахмурился.
-Подкрути ещё!
На сей раз герою пришлось приложить все усилия, чтобы продержаться со своими армиями хотя бы пару минут. Орки разбили его в пух и прах, захватили все рудники и лесопилки, в городах ввели выборное правление и провозгласили республику.
Первый мрачно взглянул на Второго, тот пожал плечами и снова что-то подкрутил.
На сей раз орки вообще не стали связываться с героем, отрезали его от всех баз в каком-то ущелье, выставили немногочисленную, но хорошо вооруженную охрану, а сами стали жить в мире и согласии, постигая великую гармонию бытия и разводя хризантемы.
Второй без напоминаний передвинул ползунок дальше.
Герой не смог сделать ни одного шага. Орки с первых секунд взломали код игры, перехватили управление ресурсами, намертво завесили героя, отключили систему боя, сделали монстров неагрессивными, а себя — неубиваемыми, исследовали всё дерево умений, не удовлетворились и по-быстрому создали четыре новых мода, расширяющих игровой мир, добавляющих различные взаимодействия, предметы и офигительной красоты закат. Попытались было выйти в сеть и распространиться на другие сервера, но Первый предусмотрительно выдернул шнур.
-Вы что, издеваетесь?- закричал он в экран.- А ну, позовите сюда ваших главных!
На экран вылезли тупые зеленые морды старейшин.
-Идиоты!- набросился на них Первый.- Придурки! Вы совсем ничего не понимаете?
-Не-а,- помотали головой орки.- А чё мы сделали-то?
-Что сдалали?- язвительно переспросил Первый.- Да вы чего только не сделали! А должны были что?
-Ну дык это… противостоять. Изо всех сил. До победного конца.
-Чушь!- Первый ударил кулаком по столу.- С вашим быстродействием, с вашей способностью моментально и безошибочно просчитывать варианты, да ещё возможностью управлять одновременно тысячами юнитов и при этом не отвлекаться от выполнения других задач, со знанием территории и всех данных по любому объекту… да обладая таким преимуществом перед человеком, и арифмометр может выиграть! Вот только какая от этого человеку радость? От вас, болваны, требуется на лёгкая победа, а красивый проигрыш! Чтобы борьба была долгой, но не слишком, тяжелой, но не изматывающей, требующей напрячь мозги — но не вывихивать их. Видимость борьбы, поняли? А в конце — полная и безоговорочная победа игрока, настолько натуральная, насколько это возможно, чтобы и мысли не возникало о подвохе. Ясно это вам?
Орки озадаченно нахмурились.
-Не, чё-то ты намудрил, начальник. Проигрывать — это как-то не по-пацански. Да ну нафиг.
-Выставь им по максимуму,- бросил Первый Второму.
-Да у них и так уже...
-А ты добавь ещё!- рявкнул Первый. Второй послушно добавил.
Орки переглянулись, скорчили тоскливые рожи и поморщились с плохо скрываемой досадой.
-Ну что, теперь понимаете?- спросил Первый.
-Понимаем,- кивнули орки, уныло поднимая дубины.- Waa-a-aagh!
Пётр Бормор
ИИ в играх это примитивные алгоритмы, не о каком моделирование игрока там речи нет. Не сравнивайте с нейросетями с помощью которых работают ИИ голосовых помощников типа кортана или Алиса.
ИИ в играх это не искусственный интеллект, его даже начать так нельзя, это примитивные алгоритмы. Тоже самое ИИ в гонках которые управляют автомобилями соперника. Просто набор алгоритмов управления, ничего там ИИ не анализирует и тем более не моделирует. В половине гонок кетчуп какой то работает где скорость авто изменяется в зависимости от скорости игрока, что если противник сильно отстал он с бешеной скоростью догонит, и т д. Это не ии вообще а просто более менее простые или сложные алгоритмы. Нейросети действительно обучаются и анализирует их сложность несравнимая с ии компьютерных игр.
Я лишь напомню, что более качественные действия противников в играх могут привести к тому, что для 80% аудитории данной игры — она станет попросту не проходимой, так как основная аудитория большинства современных игр — достаточно слабого игрового умения без возможности обучения.
Тут сразу вспоминается ВоТ, в котором 90% игроков составляют игроки, которые играют значительно хуже среднего игрока (условно — 2500 ВН8). Либо же уточнить про Дота 2, в которой основная масса игроков по своему уровню игры находиться ниже возможной «планки» для среднего игрока (условно — 5000 ммр).
С одной стороны, когда мы рассматриваем поведение противников в изначально требовательных играх (к примеру, серия ДС) и встречаем в них достаточно хитрых, интеллектуальных противников — это будет восприниматься естественно и вряд ли будет вызывать много недовольства. Но даже в этих играх могут возникнуть ситуации, от которых бомбить начнёт уже у умелых игроков. К примеру, ДС-1, Бродячий Демон может встать спиной в угол, прижаться к углу и спамить исключительно быстрые АОЕ атаки. В таком варианте, у игрока практически не будет окон для нанесения безответного урона Боссу, если игрок использует оружие только ближнего боя.
С другой стороны, если в достаточно простые игры добавить сильных по своему исполнению противников, то данные противники будут выглядеть черезчур имбалансными и будут ломать игру обычному игроку. Если в компанию Колды разработчик внезапно добавит противников, которые будут настолько же точны и быстры, как боты сложности «Эксперт» из контры 1.6, то попросту 90% аудитории Колды не смогут проходить компанию в данной игре.
Моё мнение больше сводиться к тому, что отсутствие прогресса интеллекта у противников в играх — это всё таки коммерческий ход, обусловленный тем, чтобы игра была дружелюбна к как можно большей аудитории, чтобы её могли покупать и проходить значительно больше людей.
В угоду большей популярности и доходности, некоторые разработчики режут не только интеллект противников, но и многие сложные игровые механики (аля Апекс, по сравнению с ТитанФалом, либо же Скайрим по сравнению с Морровиндом)
С этим я категорически не согласен. Когда ты сталкиваешься с ситуациями, в которых противников больше, чем 3, игра показывает реализацию ботов. Во многих играх попросту половина противников будет бездействовать и стоять АФК и ждать своей очереди. В том же самом Ведьмаке (3-ем) ты можешь собрать более 10-ти противников, но полноценную агрессию будет проявлять максимум 5 противников, а остальные будут ожидать свою очередь.
И тут я возвращаюсь к тому, что было в Морровинде — когда собирая 10+ противников, все 10 противников продолжали сохранять полную агрессию по отношению к игроку, тогда как в Скайриме уже было серьёзное упрощение: если тебя одновременно атаковало более 6-ти противников, то остальные переставали тебя атаковать.
И подобные моменты, показывающие упрощённое поведение ботов, можно найти практически в любом ААА проекте. К примеру, если игрок пропускает атаку, которая оставляет ему малое количество здоровья, то внезапно, большая часть противников на короткий промежуток времени начинают игнорировать игрока, давая ему возможность использовать предметы для восстановления здоровья.
Постарайтесь понять, что значит средний игрок и его характеристики.
И постарайтесь вообще узнать, какие градации используются в ВоТ.
В ВоТ полностью отсутствует какое либо деление по умению игроков в самой игре. Команды набираются совершенно рандомно и против команды со средним винрейтом в 56% может быть собрана команда со средним винрейтом в 48%. И для ВоТ — это — обычная реальность.
Ни о каком балансе техники и балансе игроков в ВоТ не может быть и речи. Полное отсутствие какой либо регуляции по умениям игроков привело к тому, что нет совершенно какой либо необходимости обучаться чему либо для обычного игрока.
Плюс, статья про нейронки в играх, ни слова про Блицкриг3, не надо так.
А по поводу Блицкрига 3, очень уж сомнительно, что они там сеть использовали. Гугл для игры в Старкрафт до сих пор не дописал адекватную сеть, способную играть во всех режимах, зато Нивал уже в 2017 году полноценного бота на базе сетей выпустила. Именно так и никакого хайпа на популярной теме. А то, что про этого бота никто не вспоминал, не вышло ни одной научной статьи с описанием архитектуры, так то, потому что они просто не ищут славы, а работают для людей.
Ответ Arguzd на комментарий
Да какие ты там мог УГЛУБЛЁННЫЕ статьи то НАКАРЯБАТЬ?
Верно одно утверждение — ЛЮДЕЙ ДЕЙСТВИТЕЛЬНО ТЕХНИЧЕСКИ ИНТЕРЕСУЮЩИХСЯ значимыми статьями о ИИ очень мало и они ЧИТАЮТ " ТАКИЕ " СТАТЬИ ТОЛЬКО ДЛЯ " ПОРЖАТЬ " во время перекуров, если вообще читают ТАКОЙ обзор в сновидения.
Ответ 19064622@vkontakte на комментарий
Ты то откуда взялася со своими рассизмами?
Добавить комментарий