

5 января 2006 г. компания Intel представила новые двухъядерные процессоры Pentium D 900-й серии, а несколькими днями позже (16 января) — процессор Pentium Extreme Edition 955. Эти процессоры основаны на новом ядре Presler, представляющем собой первое процессорное ядро, выполненное по нормам нового 65-нм технологического процесса. История повторяется — как и в случае перехода со 130-нм на 90-нм техпроцесс, первыми готовыми решениями становятся именно десктопные процессоры с микроархитектурой NetBurst, и лишь спустя некоторое время анонсируются мобильные платформы, основанные на процессорах, выполненных по нормам нового технологического процесса. В то же время, между выходом первых 90-нм Prescott и Dothan прошел существенно больший промежуток времени, нежели между выходом 65-нм ядер Presler и Yonah (которое мы уже успешно исследовали) — вполне возможно, что освоение нового 65-нм техпроцесса идет более успешно. Но не будем вдаваться в подробности, а сфокусируемся на основной задаче данной статьи — низкоуровневом исследовании нового 65-нм ядра Presler в сопоставлении с его наиболее близкими аналогами — «экстремальными» вариантами процессоров, основанных на 90-нм ядрах Smithfield и последней ревизией ядра Prescott N0, которые мы исследовали ранее.
Конфигурация тестового стенда
- Процессор: Intel Pentium Extreme Edition 955 (3,46 ГГц, ядро Presler, Socket 775, FSB 266 МГц)
- Материнская плата: Gigabyte GA-G1975X, чипсет Intel 975X, версия BIOS F1 от 2005/11/21
- Память: 2x512 МБ Corsair XMS2-5400UL в режиме DDR2-533 (тайминги 3-3-3-9)
Характеристики CPUID
Начнем исследование нового процессорного ядра Presler с анализа основных характеристик, выдаваемых инструкцией процессора CPUID с различными входными параметрами.
Таблица 1. Pentium EE 840 (Smithfield A0) CPUID
| Функция CPUID | Значение | Комментарий |
|---|---|---|
| Сигнатура процессора | 0F44h | Семейство 15, модель 4, степпинг 4 |
| Brand ID | 00h | Не поддерживается |
| Дескрипторы кэшей/TLB | 50h 5Bh 60h 40h 70h 7Ch | I-TLB: полноассоциативный, 64 записи D-TLB: полноассоциативный, 64 записи L1-кэш: 16 КБ, 8-ассоц., 64-байтн. строка L3 кэш отсутствует Trace Cache: 12Kuops, 8-ассоциативный L2-кэш: 1 МБ, 8-ассоц., 64-байтн. строка |
| Количество логических процессоров | 04h | 4 логических процессора |
| Количество ядер | 01h | 2 ядра |
| Basic Features, ECX | 641Dh | Bit 0, 3: Поддержка SSE3, MONITOR/MWAIT Bit 2: Неизвестно Bit 4: Поддержка расширений Debug Store (DS-CPL) Bit 10: Поддержка L1 Cache Context ID Bit 13: Поддержка инструкции CMPXCHG16B Bit 14: Поддержка Task Priority Messages |
| Extended Features, EDX | 20000000h | Bit 29: Поддержка Intel (R) EM64T |
Таблица 2. Pentium EE 955 (Presler B1) CPUID
| Функция CPUID | Значение | Комментарий |
|---|---|---|
| Сигнатура процессора | 0F62h | Семейство 15, модель 6, степпинг 2 |
| Brand ID | 00h | Не поддерживается |
| Дескрипторы кэшей/TLB | 50h 5Bh 60h 40h 70h 7Dh | I-TLB: полноассоциативный, 64 записи D-TLB: полноассоциативный, 64 записи L1-кэш: 16 КБ, 8-ассоц., 64-байтн. строка L3 кэш отсутствует Trace Cache: 12Kuops, 8-ассоциативный L2-кэш: 2 МБ, 8-ассоц., 64-байтн. строка |
| Количество логических процессоров | 04h | 4 логических процессора |
| Количество ядер | 01h | 2 ядра |
| Basic Features, ECX | E43Dh | Bit 0, 3: Поддержка SSE3, MONITOR/MWAIT Bit 2: Неизвестно Bit 4: Поддержка расширений Debug Store (DS-CPL) Bit 5: Неизвестно Bit 10: Поддержка L1 Cache Context ID Bit 13: Поддержка инструкции CMPXCHG16B Bit 14: Поддержка Task Priority Messages Bit 15: Неизвестно |
| Extended Features, EDX | 20100000h | Bit 20: Поддержка XD bit Bit 29: Поддержка Intel (R) EM64T |
Сопоставим характеристики CPUID процессора Pentium EE 955 (табл. 2) с характеристиками его наиболее близкого аналога — предыдущего «экстремального» процессора Pentium EE 840 (табл. 1). Изменения затронули, прежде всего, сигнатуру процессора — новый Pentium EE 955 с ядром Presler получил номер модели 6 и степпинг ядра 2 при сохранении номера семейства процессора 15. Официальное название степпинга ядра, соответствующего сигнатуре 0F62h — «B1». Заметим, что предыдущие «двухядерные ядра» процессоров Pentium D 800-х серий и Pentium Extreme Edition имели степпинги «A0» (который фигурирует в нашем сегодняшнем рассмотрении) и «B0». Таким образом, можно предположить, что новое 65-нм ядро Presler, первый степпинг которого получил наименование «B1», в видении производителя представляется как бы продолжением, следующим этапом развития 90-нм линейки «двухъядерных ядер» Smithfield.
Отличий в дескрипторах кэшей/TLB процессоров не наблюдается, за исключением дескриптора, соответствующего L2-кэшу — его объем в Presler составляет 2 МБ (в пересчете на одно ядро, т.е. 4 МБ в общей сложности), т.е. Presler можно считать 65-нм двухъядерным вариантом ядра «Prescott-2M» (тогда как Smithfield представляет собой просто двухъядерный вариант ядра Prescott). Нет отличий и по количеству физических ядер (2) и логических процессоров (4), содержащихся в данном процессоре. Напомним, что «количество логических процессоров» с появлением двухъядерных процессоров стало несколько условным понятием — правильнее его следовало бы назвать «общим числом «системных» процессоров, содержащихся в данном кристалле». Именно такое количество «процессоров» увидит операционная система (при условии, что она поддерживает многопроцессорность и Hyper-Threading), будучи установленной и запущенной на данном реальном процессоре. Так, все двухъядерные процессоры имеют число «логических» процессоров, равное двум — как и все одноядерные процессоры, поддерживающие Hyper-Threading, но первые отличаются от вторых по количеству физических ядер (2 и 1, соответственно). Если же процессор является двухъядерным и вдобавок поддерживает Hyper-Threading, число «логических» процессоров увеличивается до четырех, что и наблюдается на процессорах Pentium Extreme Edition (840 и 955).
Наиболее значимые изменения наблюдаются в поддерживаемых процессорами расширениях (Basic Features, ECX и Extended Features, EDX). Новый Presler отличается от Smithfield наличием двух новых «неизвестных» расширений (технологий), отмеченных битами 5 и 15 в регистре ECX Basic Features. Заметим, что те же самые биты появились и в CPUID недавно исследованного нами первого 65-нм мобильного двухъядерного процессора Intel Core Duo (Yonah). В связи с этим, как и при исследовании ядра Yonah, мы можем предположить, что один из этих битов соответствует технологии виртуализации VT, официально реализованной как в процессорах Core Solo/Duo, так и в процессорах Pentium D/Extreme Edition с новым ядром Presler. Отметим также, что некогда считавшийся «неизвестным» бит 13 Basic Features, ECX, который мы встречали, начиная с последних ревизий процессорного ядра Prescott, ныне официально известен и соответствует поддержке инструкции CMPXCHG16B. Среди прочих отличий Presler от Smithfield можно отметить реализацию в первом технологии Execute Disable, обозначаемую битом 20 EDX-регистра Extended Features.
Реальная пропускная способность кэша данных/памяти
Общая картина реальной пропускной способности L1/L2 кэша данных и оперативной памяти (рис. 1) выглядит привычно для процессоров-последователей ядра Prescott. Объем L1-кэша — 16 КБ, объем L2 — 2 МБ, иерархия кэшей — инклюзивная. В области 256 КБ наступает некоторое снижение пропускной способности L2-кэша (т.к. указанная область приходится именно на L2-кэш), связанное с исчерпанием ресурса буфера транслированных виртуальных адресов в физические адреса памяти D-TLB. Как и прежде, L1-кэш характеризуется «сквозным» режимом работы на запись (Write-Through), что проявляется в виде равенства пропускной способности L1- и L2-кэшей на запись (иными словами, отсутствия перегиба в области размера L1-кэша, т.е. 16 КБ).

Рис. 1. Реальная пропускная способность кэша данных и оперативной памяти
Таблица 3
| Уровень | Средняя пропускная способность, байт/такт (МБ/с) | ||
|---|---|---|---|
| Pentium 4 EE (Prescott N0) | Pentium EE 840 (Smithfield A0) | Pentium EE 955 (Presler B1) | |
| L1, чтение, MMX L1, чтение, SSE2 L1, запись, MMX L1, запись, SSE2 | 7.98 15.93 2.91 3.56 | 7.98 15.93 2.91 3.56 | 7.98 15.93 2.91 3.56 |
| L2, чтение, MMX L2, чтение, SSE2 L2, запись, MMX L2, запись, SSE2 | 4.57 8.20 2.91 3.56 | 4.57 8.21 2.91 3.56 | 4.56 8.13 2.91 3.56 |
| RAM, чтение, MMX RAM, чтение, SSE2 RAM, запись, MMX RAM, запись, SSE2 | 6003 МБ/с 6540 МБ/с 2217 МБ/с 2218 МБ/с | 5361 МБ/с 5650 МБ/с 2409 МБ/с 2431 МБ/с | 6100 МБ/с 6604 МБ/с 2145 МБ/с 2157 МБ/с |
По количественным характеристикам пропускной способности (табл. 3) можно заметить, что L1- и L2-кэши Presler практически идентичны по всем показателям кэшам ядер Prescott N0 и Smithfield. Реальная пропускная способность оперативной памяти на чтение на платформе с процессором Presler заметно выше по сравнению с таковой на Smithfield, в связи с 266-МГц системной шиной (теоретическая ПС которой — 8.53 ГБ/с), однако ее скоростные показатели на запись далеко не столь велики, и даже несколько уступают тем, что были получены на платформе с Pentium 4 Extreme Edition (Prescott N0, также с 266-МГц системной шиной).
Предельная реальная пропускная способность памяти
Как обычно (для процессоров класса Pentium 4), метод Software Prefetch позволяет достичь наибольших значений ПСП, в то время как остальные методы не обладают столь же высокой эффективностью.

Рис. 2. Максимальная реальная ПСП, Software Prefetch и Non-Temporal Store
Кривые зависимости реальной ПСП на чтение и копирование от дистанции программной предвыборки на (рис. 2) выглядят типично для ядер класса Prescott (внешне они совпадают с кривыми, полученными на процессоре Pentium 4 Extreme Edition 3.73 ГГц).
Таблица 4
| Режим доступа | Предельная реальная ПСП на чтение, МБ/с* | ||
|---|---|---|---|
| Pentium 4 EE (Prescott N0) | Pentium EE 840 (Smithfield A0) | Pentium EE 955 (Presler B1) | |
| Чтение, MMX Чтение, SSE2 Чтение, MMX, SW Prefetch Чтение, SSE2, SW Prefetch Чтение, MMX, Block Prefetch 1 Чтение, SSE2, Block Prefetch 1 Чтение, MMX, Block Prefetch 2 Чтение, SSE2, Block Prefetch 2 Чтение строк кэша, прямое Чтение строк кэша, обратное | 6003 (70.3%) 6540 (76.6%) 8315 (97.4%) 8509 (99.7%) 5490 (64.3%) 6069 (71.1%) 5936 (69.6%) 6557 (76.8%) 7623 (89.3%) 7613 (89.2%) | 5361 (83.8%) 5650 (88.3%) 6405 (100.1%) 6438 (100.6%) 4730 (73.9%) 5245 (82.0%) 5351 (83.6%) 5681 (88.8%) 6213 (97.1%) 6208 (97.0%) | 6100 (71.5%) 6604 (77.4%) 8422 (98.7%) 8569 (100.4%) 5455 (63.9%) 6084 (71.3%) 5992 (70.2%) 6576 (77.1%) 7466 (87.5%) 7488 (87.8%) |
*в скобках указаны значения относительно теоретического предела ПСП
(6.4 ГБ/с для 200-МГц FSB, 8.53 ГБ/с для 266-МГц FSB)
Из представленных количественных оценок максимальной реальной ПСП на чтение (табл. 4) видно, что значения ПСП, достигаемые теми или иными методами оптимизации на Presler очень близки к значениям, полученным на «экстремальном» варианте процессора Pentium 4 Extreme Edition с ядром Prescott степпинга N0. Следовательно, можно предположить, что реализация программной предвыборки в Presler по сравнению с Prescott N0 не изменилась.
Таблица 5
| Режим доступа | Предельная реальная ПСП на запись, МБ/с* | ||
|---|---|---|---|
| Pentium 4 EE (Prescott N0) | Pentium EE 840 (Smithfield A0) | Pentium EE 955 (Presler B1) | |
| Запись, MMX Запись, SSE2 Запись, MMX, Non-Temporal Запись, SSE2, Non-Temporal Запись строк кэша, прямая Запись строк кэша, обратная | 2217 (26.0%) 2218 (26.0%) 5705 (66.9%) 5707 (66.9%) 2760 (32.3%) 2703 (31.7%) | 2409 (37.6%) 2431 (38.0%) 4266 (66.6%) 4266 (66.6%) 3114 (48.7%) 3113 (48.6%) | 2145 (25.1%) 2157 (25.3%) 5662 (66.4%) 5670 (66.4%) 2805 (32.9%) 2770 (32.5%) |
*в скобках указаны значения относительно теоретического предела ПСП
(6.4 ГБ/с для 200-МГц FSB, 8.53 ГБ/с для 266-МГц FSB)
Аналогично, значения предельной реальной ПСП на запись (табл. 5) полученные на Prescott N0 и Presler, близки во всех случаях. Как обычно, наилучший результат наблюдается при использовании метода прямого сохранения данных, позволяющего достичь величину ПСП, составляющую 2/3 от теоретической пропускной способности системной шины процессора.
Латентность кэша данных/памяти
Общая картина латентности L1/L2-кэша данных и памяти (рис. 3) выглядит привычно — из особенностей, следует отметить весьма малые задержки при доступе в память при прямом и обратном обходе цепочки с шагом, равным длине строки L1-кэша (64 байта — что, строго говоря, не совсем корректно, ибо выборка данных из памяти в L2 кэш осуществляется по целым строкам L2-кэша, «эффективная» длина которой составляет 128 байт в связи с обязательной выборкой смежной 64-байтной строки), а также плавное возрастание латентности псевдослучайного доступа при размере блока данных 256 КБ и выше, что связано с исчерпанием размера буфера D-TLB.

Рис. 3. Латентность кэша данных/памяти
По количественным оценкам (табл. 6) средней латентности L1/L2-кэша данных и памяти (для последней приведены значения, полученные при «правильном» обходе цепочки, с шагом в 128 байт) нельзя сказать о значительных отличиях между рассматриваемыми процессорами — во всех случаях, средняя латентность L1-кэша составляет 4 такта, L2 — примерно 28.5 тактов. Средняя латентность оперативной памяти зависит от режима доступа (вследствие функционирования аппаратной предвыборки) и составляет примерно 30-35 нс при последовательном обходе, 50 нс — при псевдослучайном, и 90-100 нс — при истинно случайном обходе. Несколько меньшие средние латентности на Presler не позволяют увидеть существенных отличий в алгоритме аппаратной предвыборки (которые мы увидим ниже), поскольку с гораздо большей вероятностью могут быть связаны с собственно подсистемой памятью (модулями Corsair XMS2-5400UL и более новым чипсетом Intel 975X).
Таблица 6
| Уровень, доступ | Средняя латентность, тактов (нс) | ||
|---|---|---|---|
| Pentium 4 EE (Prescott N0) | Pentium EE 840 (Smithfield A0) | Pentium EE 955 (Presler B1) | |
| L1 (все случаи) | 4 | 4 | 4 |
| L2 (все случаи) | ~28.5 | ~28.5 | ~28.5 |
| RAM*, прямой RAM, обратный RAM, случайный** RAM, псевдослучайный | 30.3 нс 33.9 нс 101.4 нс 49.4 нс | 32.3 нс 35.7 нс 100.9 нс 51.5 нс | 30.0 нс 33.5 нс 90.0 нс 47.8 нс |
*Шаг обхода 128 байт
**Размер блока 4 МБ
Минимальная латентность кэша данных/памяти
Наиболее интересные открытия в ядре Presler ждут нас именно в этом разделе. Что касается минимальной латентности L1-кэша, никаких отличий как от средней латентности этого уровня кэша, так и от других процессорных ядер, мы не видим (и соответствующие рисунки не приводим) — она остается равной 4 тактам процессора во всех случаях. Гораздо более интересны картины достижения минимальной латентности L2-кэша путем разгрузки L1-L2 шины процессора.
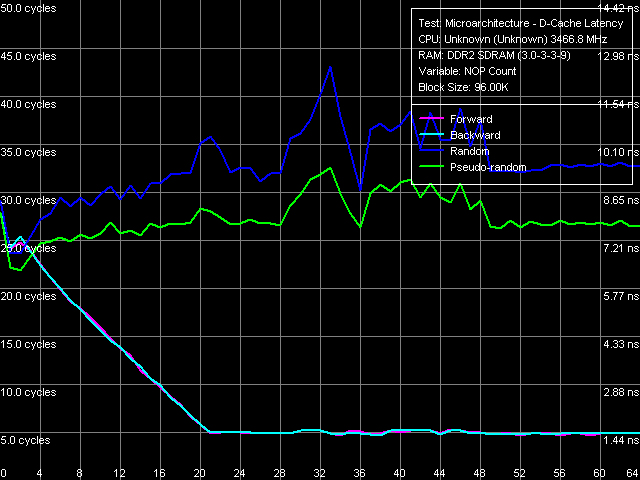
Рис. 4. Минимальная латентность L2 кэша, метод 1
Потрясающий результат наблюдается уже в первом случае (рис. 4), при использовании стандартной методики разгрузки шины, которая, как известно, не очень-то годится для тестирования процессоров с ярко выраженной спекулятивной загрузкой данных.
Начнем рассмотрение режимов обхода L2-кэша в обратном порядке. Итак, привычный (для ядер Prescott и их последователей) вид кривых сохраняется только в случае истинно случайного обхода 96-КБ блока данных, находящихся в L2-кэше — минимальная латентность составляет 24 такта, разгрузка шины не наблюдается при вставке даже большого количества NOP-ов. Псевдослучайный обход дает очень похожую кривую, но смещенную относительно основной примерно на 2 такта вниз — соответственно, минимальная латентность в этом случае равняется 22 тактам. С чем связано некоторое снижение латентности при псевдослучайном обходе — не очень понятно, но аппаратная предвыборка данных здесь не причем — т.к. разгрузка шины здесь также не наблюдается. Последняя вступает в силу лишь при строго последовательном (прямом и обратном) обходе цепочки данных, расположенных в L2-кэше — наблюдается типичная картина разгрузки шины с достижением 5(!)-тактной латентности L2-кэша при количестве NOP-ов свыше 21 (в первом приближении получаем, что вставка каждого последующего NOP-а в области от 0 до 21 снижает латентность L2-кэша на 1 такт).
О чем это говорит? Разумеется, об истинной 5-тактной латентности L2-кэша (при 4-тактном L1) говорить было бы абсурдно — скорее, можно говорить о реализации аппаратной предвыборки данных на уровне L2-кэша процессора! В пользу аппаратной предвыборки, которую, как известно, легко реализовать именно для линейного считывания данных, говорят «разгрузочные кривые», наблюдаемые именно при последовательном обходе. В остальных же случаях наблюдаем латентность L2-кэша «практически в чистом виде», как и во всех остальных ядрах семейства Prescott.
Что ж, реализация аппаратной предвыборки из L2-кэша — довольно неплохое решение, позволяющее хотя бы отчасти скрыть большие задержки, связанные с доступом в этот уровень кэша процессора.

Рис. 5. Минимальная латентность L2 кэша, метод 2
Различия в латентности L2-кэша в зависимости от режима его обхода заметны и по кривым достижения минимальной латентности L2-кэша, полученных альтернативным методом (рис. 5), подходящим для процессорных ядер класса Prescott. В этом случае, по кривым псевдослучайного и случайного обхода четко видно достижение минимальной 22-тактной латентности L2, привычной для процессоров семейства Prescott (точка перегиба при вставке 22 однотактных операций NOP, величина латентности в этой точке также равняется 22). Этот тест подтверждает нашу гипотезу о том, что латентность L2-кэша в Presler как таковая не изменилась.
Переходим к тестам минимальной латентности оперативной памяти. Для демонстрации второго значимого отличия Presler от предыдущих ядер своего семейства, мы привели кривые разгрузки шины памяти, полученные при «неправильном», 64-байтном обходе последней на процессорах Smithfield (рис. 6a) и Presler (рис. 6b) — именно в этом случае можно увидеть наиболее значимые отличия в реализации в этих процессорах алгоритма аппаратной предвыборки, но уже на уровне оперативной памяти.

Рис. 6a. Минимальная латентность памяти, шаг 64 байта, Smithfield
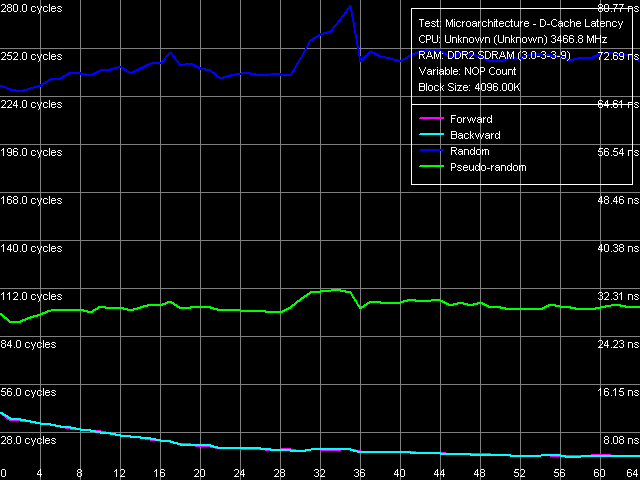
Рис. 6b. Минимальная латентность памяти, шаг 64 байта, Presler
Как и в случае L2-кэша, кривые псевдослучайного и случайного обхода, при которых аппаратная предвыборка практически бездействует, выглядят вполне одинаково на обоих процессорах. Различия наблюдаются при прямом и обратном обходе цепочки данных в памяти. В случае Smithfield имеем кривые, качественно аналогичные двум рассмотренным выше, но лишь с меньшими абсолютными величинами. В случае же Presler наблюдается качественно иная «разгрузочная картина», напоминающая разгрузку шины L1-L2 в этом же процессоре, а также, скажем, на процессорах семейства AMD K8. Таким образом, наряду с введением аппаратной предвыборки на уровне L2-кэша процессора, можно говорить и об усовершенствовании аппаратной предвыборки данных процессором Presler из памяти.
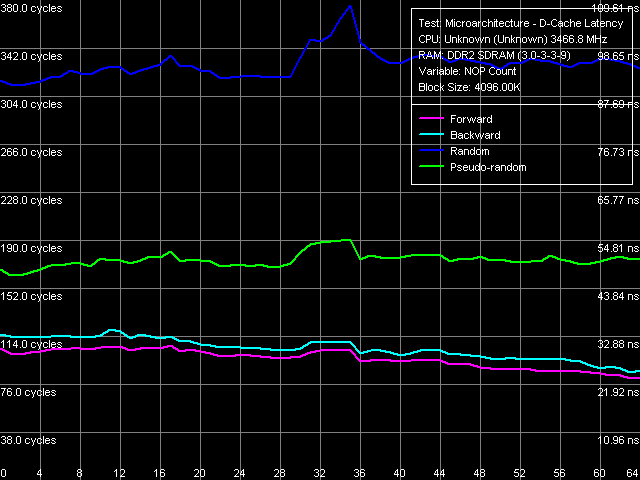
Рис. 7. Минимальная латентность памяти, шаг 128 байт
Кривые разгрузки шины L2-RAM при 128-байтном обходе (рис. 7) выглядят совершенно иначе — точнее сказать, они практически идентичны кривым, полученным на процессорах Prescott и Smithfield.
Таблица 7
| Уровень, доступ | Минимальная латентность, тактов (нс) | ||
|---|---|---|---|
| Pentium 4 EE (Prescott N0) | Pentium EE 840 (Smithfield A0) | Pentium EE 955 (Presler B1) | |
| L1 (все случаи) | 4 | 4 | 4 |
| L2*, прямой L2, обратный L2, случайный L2, псевдослучайный | 24 (22) 24 (22) 24 (22) 24 (22) | 24 (22) 24 (22) 24 (22) 24 (22) | 5 (22) 5 (22) 24 (22) 22 (22) |
| RAM**, прямой RAM, обратный RAM, случайный*** RAM, псевдослучайный | 27.0 нс 31.1 нс 105.4 нс 50.9 нс | 24.6 нс 27.0 нс 98.9 нс 50.5 нс | 23.4 нс 24.8 нс 90.3 нс 47.0 нс |
*В скобках указаны значения, полученные методом 2
**Шаг обхода 128 байт
***Размер блока 4 МБ
Сводные данные по минимальным латентностям L1/L2-кэша данных и оперативной памяти процессоров с ядрами Prescott N0, Smithfield и Presler представлены в табл. 7. Характерно отметить, что в случае всех трех процессорных ядер минимальные латентности оперативной памяти при ее 128-байтном обходе, когда эффективность аппаратной предвыборки данных процессором резко снижена, практически не отличаются.
Ассоциативность кэша данных

Рис. 8. Ассоциативность кэша данных
Тест ассоциативности L1/L2 кэша данных Presler (рис. 8) показывает картину, типичную для процессоров семейства Prescott — «эффективная» ассоциативность L1-кэша данных в этом процессоре получается равной единице, ассоциативность объединенного L2-кэша инструкций/данных — восьми.
Реальная пропускная способность шины L1-L2 кэша
Характерная зависимость между увеличения объема L2-кэша и снижения пропускной способности шины L1-L2, выявленная в нашем исследовании ядра Smithfield, хорошо себя подтверждает и в случае ядра Presler (табл. 8). А именно, пропускная способность его шины L1-L2 практически один в один совпадает с ПС шины L1-L2 процессора Pentium 4 Extreme Edition с ядром Prescott N0, содержащем 2 МБ L2-кэша.
Таблица 8
| Режим доступа | Пропускная способность, байт/такт* | ||
|---|---|---|---|
| Pentium 4 EE (Prescott N0) | Pentium EE 840 (Smithfield A0) | Pentium EE 955 (Presler B1) | |
| Чтение (прямое) Чтение (обратное) Запись (прямая) Запись (обратная) | 14.66 (45.8%) 14.60 (45.6%) 4.10 (12.8%) 4.10 (12.8%) | 16.75 (52.3%) 16.58 (51.8%) 4.89 (15.3%) 4.85 (15.2%) | 14.62 (45.7%) 14.55 (45.5%) 4.10 (12.8%) 4.10 (12.8%) |
*в скобках указаны значения относительно теоретического предела
Trace Cache, эффективность декодирования/исполнения
Наиболее интересной деталью микроархитектуры NetBurst является специализированный кэш микроопераций, предоставляемых ему предекодером, именуемый Execution Trace Cache. Посмотрим, какие отличия по этой части покажет нам новое ядро Presler.

Рис. 9. Эффективность декодирования/исполнения
Как обычно, наиболее показательной является общая картина скорости декодирования/исполнения, полученная при исполнении последовательности «крупных», но простых 6-байтных инструкций CMP. В этом тесте, как и во всех других тестах этого типа, качественных отличий между Presler и ранее изученными ядрами Prescott и Smithfield не наблюдается. Переходим к количественным оценкам.
Таблица 9. Эффективность декодирования/исполнения, Pentium 4 EE (Prescott N0)
| Тип инструкций | Эффективный объем Trace Cache, КБ (Kuop) | Эффективность декодирования, байт/такт (инструкций/такт) | |
|---|---|---|---|
| Trace Cache | L2 Cache | ||
| NOP | 10.5 (10.5) | 2.87 (2.87) | 1.00 (1.00) |
| SUB | 22.0 (11.0) | 5.73 (2.87) | 2.00 (1.00) |
| XOR | 22.0 (11.0) | 4.00 (2.00) | 2.00 (1.00) |
| TEST | 22.0 (11.0) | 3.42 (1.71) | 2.00 (1.00) |
| XOR/ADD | 22.0 (11.0) | 5.73 (2.87) | 2.00 (1.00) |
| CMP 1 | 22.0 (11.0) | 5.16 (2.58) | 2.00 (1.00) |
| CMP 2 | 44.0 (11.0) | 10.32 (2.58) | 4.00 (1.00) |
| CMP 3 | 63.0 (10.5) | 15.48 (2.58) | 4.00 (0.67) |
| CMP 4 | 63.0 (10.5) | 15.48 (2.58) | 4.00 (0.67) |
| CMP 5 | 63.0 (10.5) | 15.48 (2.58) | 4.00 (0.67) |
| CMP 6* | 32.0 (10.6) | 8.67 (1.45) | 4.00 (0.67) |
| Prefixed CMP 1 | 63.0 (7.9; 10.5**) | 20.62 (2.58) | 4.14 (0.52) |
| Prefixed CMP 2 | 63.0 (7.9; 10.5**) | 20.60 (2.58) | 4.14 (0.52) |
| Prefixed CMP 3 | 63.0 (7.9; 10.5**) | 20.60 (2.58) | 4.14 (0.52) |
| Prefixed CMP 4* | 44.0 (11.0; 14.7**) | 11.56 (1.45) | 4.12 (0.52) |
*2 микрооперации
**в предположении, что префиксы отбрасываются еще до помещения в Trace Cache
Как известно по нашим предыдущим исследованиям различных воплощений микроархитектуры NetBurst, в первых ядрах с официальной поддержкой технологии EM64T — вроде Nocona D0 и Prescott E0, впервые наметилась тенденция ухудшения эффективности исполнения некоторых команд — в частности, простейших операций типа «TEST» (test eax, eax) и «CMP 1» (cmp eax, eax). Намеченная тенденция продолжила свое развитие в ядре «Prescott/2M» ревизии N0 (табл. 9; для удобства, значения, претерпевающие изменения в последующих ядрах, выделены жирным шрифтом). Прежде всего, в этом ядре стало заметно дальнейшее снижение эффективности исполнения команд «TEST» и «CMP 1». Второе значимое изменение проявилось в виде снижения максимальной скорости исполнения всех операций CMP из L2-кэша до 4.0 байт/такт (1.0 или 0.67 инструкций/такт, в зависимости от длины команды), а также «префиксных» CMP до 4.14 байт/такт (0.52 операций/такт).
Таблица 10. Эффективность декодирования/исполнения, Pentium EE 840 (Smithfield A0)
| Тип инструкций | Эффективный объем Trace Cache, КБ (Kuop) | Эффективность декодирования, байт/такт (инструкций/такт) | |
|---|---|---|---|
| Trace Cache | L2 Cache | ||
| NOP | 10.5 (10.5) | 2.87 (2.87) | 1.00 (1.00) |
| SUB | 22.0 (11.0) | 5.73 (2.87) | 2.00 (1.00) |
| XOR | 22.0 (11.0) | 3.99 (2.00) | 2.00 (1.00) |
| TEST | 22.0 (11.0) | 3.42 (1.71) | 2.00 (1.00) |
| XOR/ADD | 22.0 (11.0) | 5.73 (2.87) | 2.00 (1.00) |
| CMP 1 | 22.0 (11.0) | 5.16 (2.58) | 2.00 (1.00) |
| CMP 2 | 44.0 (11.0) | 10.32 (2.58) | 3.99 (1.00) |
| CMP 3 | 63.0 (10.5) | 15.48 (2.58) | 4.26 (0.71) |
| CMP 4 | 63.0 (10.5) | 15.48 (2.58) | 4.26 (0.71) |
| CMP 5 | 63.0 (10.5) | 15.48 (2.58) | 4.26 (0.71) |
| CMP 6* | 32.0 (10.6) | 8.67 (1.45) | 4.26 (0.71) |
| Prefixed CMP 1 | 63.0 (7.9; 10.5**) | 20.60 (2.58) | 4.45 (0.56) |
| Prefixed CMP 2 | 63.0 (7.9; 10.5**) | 20.60 (2.58) | 4.45 (0.56) |
| Prefixed CMP 3 | 63.0 (7.9; 10.5**) | 20.60 (2.58) | 4.45 (0.56) |
| Prefixed CMP 4* | 44.0 (11.0; 14.7**) | 11.55 (1.45) | 4.45 (0.56) |
*2 микрооперации
**в предположении, что префиксы отбрасываются еще до помещения в Trace Cache
Дальнейшая эволюция микроархитектуры NetBurst, проявившая себя в виде выпуска первого двухъядерного процессора Pentium Extreme Edition 840 (и Pentium D 800-й серии) с ядром Smithfield (табл. 10) не внесла существенных изменений в эффективность исполнения «TEST» и «CMP 1» — она осталась такой же, как и у процессоров с ядром «Prescott/2M». Зато эффективность исполнения операций CMP3-CMP6, а также префиксных CMP1-CMP4 из L2-кэша вновь возросла. В нашем исследовании ядра Smithfield мы предположили, что это связано с различиями в объеме L2-кэша в процессорах с ядрами Prescott N0 и Smithfield. Самое время проверить это предположение, основываясь на результатах тестов нового ядра Presler (табл. 11).
Таблица 11. Эффективность декодирования/исполнения, Pentium EE 955 (Presler B1)
| Тип инструкций | Эффективный объем Trace Cache, КБ (Kuop) | Эффективность декодирования, байт/такт (инструкций/такт) | |
|---|---|---|---|
| Trace Cache | L2 Cache | ||
| NOP | 10.5 (10.5) | 2.87 (2.87) | 1.00 (1.00) |
| SUB | 22.0 (11.0) | 5.73 (2.87) | 2.00 (1.00) |
| XOR | 22.0 (11.0) | 3.99 (2.00) | 2.00 (1.00) |
| TEST | 22.0 (11.0) | 3.42 (1.71) | 2.00 (1.00) |
| XOR/ADD | 22.0 (11.0) | 5.73 (2.87) | 2.00 (1.00) |
| CMP 1 | 22.0 (11.0) | 5.16 (2.58) | 2.00 (1.00) |
| CMP 2 | 44.0 (11.0) | 10.32 (2.58) | 3.99 (1.00) |
| CMP 3 | 63.0 (10.5) | 15.47 (2.58) | 4.00 (0.67) |
| CMP 4 | 63.0 (10.5) | 15.48 (2.58) | 4.00 (0.67) |
| CMP 5 | 63.0 (10.5) | 15.48 (2.58) | 4.00 (0.67) |
| CMP 6* | 32.0 (10.6) | 8.66 (1.45) | 4.00 (0.67) |
| Prefixed CMP 1 | 63.0 (7.9; 10.5**) | 20.62 (2.58) | 4.14 (0.52) |
| Prefixed CMP 2 | 63.0 (7.9; 10.5**) | 20.62 (2.58) | 4.14 (0.52) |
| Prefixed CMP 3 | 63.0 (7.9; 10.5**) | 20.61 (2.58) | 4.14 (0.52) |
| Prefixed CMP 4* | 44.0 (11.0; 14.7**) | 11.55 (1.45) | 4.12 (0.52) |
*2 микрооперации
**в предположении, что префиксы отбрасываются еще до помещения в Trace Cache
Предположение подтверждается — увеличение объема L2-кэша до 2 МБ вновь сопровождается уменьшением предельной скорости декодирования крупных простых инструкций до 4.0 — 4.14 байт/такт. Каких-либо иных отличий нового ядра Presler от Smithfield и Prescott N0 в этой серии тестов не наблюдается.
Второе ощутимое изменение декодера ядер Prescott/Nocona с введением EM64T заключалось в снижении эффективности отбрасывания «бессмысленных» префиксов в тесте исполнения инструкций вида [0x66]nNOP, n = 0..14.

Рис. 10. Эффективность декодирования/исполнения префиксных инструкций
Таблица 12
| Количество префиксов | Эффективность декодирования/исполнения,байт/такт (инструкций/такт) | ||
|---|---|---|---|
| Pentium 4 660 (Prescott N0) | Pentium EE 840 (Smithfield A0) | Pentium EE 955 (Presler B1) | |
| 0 | 2.80 (2.80) | 2.80 (2.80) | 2.79 (2.79) |
| 1 | 5.43 (2.72) | 5.43 (2.72) | 5.37 (2.69) |
| 2 | 8.13 (2.71) | 8.13 (2.71) | 8.06 (2.69) |
| 3 | 10.42 (2.61) | 10.42 (2.61) | 10.32 (2.58) |
| 4 | 12.74 (2.55) | 12.74 (2.55) | 12.58 (2.52) |
| 5 | 14.74 (2.46) | 14.74 (2.46) | 14.33 (2.38) |
| 6 | 16.64 (2.38) | 16.64 (2.38) | 16.12 (2.30) |
| 7 | 18.76 (2.35) | 18.76 (2.35) | 18.43 (2.30) |
| 8 | 20.23 (2.25) | 20.23 (2.25) | 19.84 (2.20) |
| 9 | 21.96 (2.20) | 21.96 (2.20) | 21.50 (2.15) |
| 10 | 23.45 (2.13) | 23.45 (2.13) | 22.43 (2.04) |
| 11 | 25.17 (2.10) | 25.17 (2.10) | 24.57 (2.05) |
| 12 | 26.46 (2.04) | 26.46 (2.04) | 25.80 (1.98) |
| 13 | 27.89 (1.99) | 27.89 (1.99) | 27.15 (1.94) |
| 14 | 30.35 (2.02) | 30.35 (2.02) | 28.66 (1.91) |
Напомним, что в этом плане, ядра Prescott N0 и Smithfield не претерпели больших изменений по сравнению с предыдущими ядрами процессоров, поддерживающих EM64T. Тем не менее, результаты данного теста на Presler (рис. 10, табл. 12) указывают на дальнейшее снижение эффективности отсечения «бессмысленных» префиксов.
Буфер переупорядочивания инструкций (I-ROB)

Рис. 11. Глубина буфера переупорядочивания инструкций
Оценка глубины буфера переупорядочивания инструкций на Presler (рис. 11) дает картину, схожую с полученной в ходе тестов процессорного ядра Nocona степпинга D0. Перегиб наблюдается в области 120 NOP-ов, что весьма близкую к подлинному значению, заявленному для процессоров класса Pentium 4 Prescott (126). Разумно предложить, что такую же глубину I-ROB имеют и новые двухъядерные процессоры Pentium D/Extreme Edition 800-й и 900-й серий, основанные на ядрах Smithfield и Presler.
Характеристики TLB
На изучении характеристик D-TLB и I-TLB подробно останавливаться не будем, учитывая, что они (по значениям дескрипторов CPUID) не изменились еще со времен первого ядра Prescott.

Рис. 12. Объем D-TLB

Рис. 13. Ассоциативность D-TLB
Объем D-TLB (рис. 12) составляет 64 записи страниц (что мы уже видели по результатам тестов пропускной способности и латентности L1/L2/RAM), его промах при исчерпании объема «обходится» процессору минимум в 57 тактов. Ассоциативность (рис. 13) — полная.

Рис. 14. Объем I-TLB

Рис. 15. Ассоциативность I-TLB
Объем I-TLB (рис. 14) — 64 записи, штраф промаха буфера — 45 тактов (прямой, обратный обход) и выше (случайный обход), ассоциативность (рис. 15) — полная.
Заключение
Наше сегодняшнее исследование низкоуровневых характеристик одного из двух полностью независимых ядер нового 65-нм двухъядерного процессора Pentium Extreme Edition 955 (Presler) выявило его максимальную близость с предыдущим 90-нм вариантом «Prescott/2M», реализованном в процессорах Pentium 4 600-й серии и Pentium 4 Extreme Edition 3.73 ГГц. Сходство проявляется в объемах и организации кэшей данных процессора, их скоростных характеристиках, пропускной способности шины L1-L2, а также по большинству характеристик предекодера и Execution Trace Cache.
Вместе с тем, был выявлен ряд серьезных отличий, положительно характеризующих новое ядро Presler. Прежде всего, речь идет о реализации принципиально нового элемента как для процессоров x86 вообще, так и микроархитектуры NetBurst в частности — аппаратной предвыборки данных на уровне L2-кэша, позволяющей маскировать ощутимые задержки, связанные с доступом в этот сравнительно медленный кэш при считывании данных в строго прямом или обратном направлении. Во-вторых, в ядре Presler значительно переработана и предвыборка данных из памяти, что позволяет достичь еще меньших задержки подсистемы памяти (в тех же самых случаях прямого или обратного последовательного доступа). Немножко подпортить картину можно упоминанием дальнейшего снижения эффективности декодирования/исполнения префиксных инструкций, однако сам по себе этот факт представляет лишь теоретический интерес, ибо эти инструкции не применяются на практике. Таким образом, указанный недочет никак не проявит себя в действительности, при исполнении кода реальных приложений.