

Необходимость создания данного тестового пакета вызвана тем, что до настоящего времени не существовало ни одного хорошего программного продукта для измерения важнейших параметров подсистемы CPU/Chipset/RAM, выдающего стабильные, надежные (воспроизводимые) результаты тестирования и позволяющего задавать параметры тестов в широких пределах. В качестве важнейших «низкоуровневых» характеристик системы можно перечислить латентность и реальную пропускную способность оперативной памяти, среднюю/минимальную латентность различных уровней кэша и степень его ассоциативности, реальную пропускную способность шины L1-L2 кэша, характеристики уровней TLB. При этом данные моменты в технической документации того или иного продукта (CPU или чипсета), зачастую рассматриваются недостаточно подробно, если рассматриваются вообще. Таким образом, можно смело утверждать, что подобный тестовый пакет, объединяющий в себе целый ряд подтестов, предназначенных для измерения объективных характеристик элементов системы, крайне необходим для оценки важнейших объективных характеристик платформы в целом. Предлагаемый вашему вниманию тестовый пакет разработан в рамках проекта RightMark, имеет рабочее название RightMark Memory Analyzer и доступен для ознакомления в виде открытого исходного кода (Open Source). Итак, приступим к рассмотрению самого тестового пакета. Системные требования
Минимальными системными требованиями программы являются:
- Процессор не ниже Pentium MMX;
- Минимум 32 MB свободной оперативной памяти;
- Операционная система Windows 2000 и выше.

В этом разделе программы находятся настройки, являющиеся общими для всех подтестов, реализованных в RMMA.
CPU Clock, CPU Count
Информация о частоте процессора и количестве логических процессоров, присутствующих в системе.
Cache Line Size
Эффективный размер строки кэша, определяемый автоматически при запуске приложения (процедура определения занимает несколько секунд). Этот параметр является одним из важнейших для получения правильных результатов в большинстве реализованных подтестов. В связи с этим его автоматическое определение является неотъемлемой частью функциональности RMMA.
Memory Allocation
Выбор метода размещения памяти, необходимой для выполнения тестов.
Standard — стандартный метод выделения блока памяти с помощью malloc() с последующим вызовом VirtualLock() по выделенному региону памяти, гарантирующим, что последующее обращение к этому региону не вызовет page fault.
AWE — метод, использующий расширения Address Windowing Extensions, доступные в операционных системах класса Windows 2000/XP/2003 Server. Данный метод выделения памяти является более надежным для ряда тестов, например, таких как тест ассоциативности кэша. Использование расширений AWE требует наличия у пользователя привилегии Lock Pages in Memory, которая, недоступна по умолчанию. Для получения данной привилегии необходимо выполнить следующие действия:
- Войти в систему с административным уровнем доступа;
- Запустить Local Security Policy из Administrative Tools;
- Выбрать Security Settings —> Local Policies —> User Rights Assignment;
- Выбрать политику Lock pages in memory и добавить имя пользователя или группы (например, Administrators).
- Чтобы данная политика вступила в силу, достаточно просто выйти из системы и войти в нее заново.
Data Set Size
Общий объем данных, который будет прочитан/записан при измерении каждой последующей точки. Само измерение в каждой точке повторяется четыре раза, после чего выбирается минимальный (по количеству тактов процессора) результат, что позволяет достичь большей воспроизводимости. Таким образом, например, если вы измеряете пропускную способность памяти на чтение с размером блока 1MB, величина Data Set Size = 128 MB означает, что в этом случае будет осуществлено 4 измерения с 32 итерациями чтения в каждом. Большие значения Data Set Size приводят к более достоверным результатам (более гладким кривым), но увеличивают время исполнения теста в соответствующее число раз.
Thread Lock
В общем случае, каждый тест запускается в главном потоке, которому присваивается наивысший возможный приоритет (realtime), что гарантирует практически полное отсутствие влияния на результаты тестирования других процессов, которые могут быть запущены в операционной системе. Однако это утверждение справедливо далеко не всегда, а именно — только в случае с однопроцессорными системами, каковыми, правда, и является большинство пользовательских систем. В случае мультипроцессорных систем (SMP или Hyper-Threading) посторонние процессы могут оказывать существенное влияние на результаты тестов. В связи с этим, данная опция введена с целью блокирования исполнения других процессов на мультипроцессорных системах класса SMP, что ведет к повышению точности и стабильности измерений. В то же время, использование данной опции крайне не рекомендуется в системах с технологией Hyper-Threading, поскольку в этом случае оно начинает сильно влиять на результаты тестирования. Оптимальным режимом тестирования систем с Hyper-Threading является условие по возможности максимально полного отсутствия загрузки операционной системы. Настоятельно рекомендуется закрыть все приложения, в т.ч. работающие в фоновом режиме и имеющие минимальный приоритет.
Logarithmic Y Scale
Включает логарифмический масштаб по оси ординат. По умолчанию используется линейный масштаб.
White Background
Позволяет использовать белый фон в графическом представлении результатов теста, как по мере тестирования, так и в отчетном (BMP) файле. По умолчанию используется черный фон. Эта опция введена для удобства распечатки полученных результатов теста.
Create Test Report
Эта опция определяет, будет ли создан отчет после завершения теста. Отчет включает в себя два файла, с текстовым (MS Excel CSV) и графическим (BMP) представлением результатов теста.
Последовательность исполнения тестов (Batch)
Возможность последовательного исполнения тестов введена, прежде всего, из соображений удобства, в частности, для «потокового» тестирования большого количества разнообразных систем одним и тем же набором тестов. RMMA позволяет осуществлять следующие действия с набором тестов (Batch):
- Delete — удаление выбранного теста из набора;
- Clear — очистка всего набора;
- Load — загрузка сохраненного набора из файла;
- Save — сохранение текущего набора в файл.
Добавление индивидуальных тестов в набор осуществляется нажатием кнопки Add to Batch при нахождении в любом из подтестов программы. Описание тестов, реализованных в RMMA
В тестовом пакете RMMA реализовано семь видов тестов, позволяющих оценить основные характеристики подсистемы CPU/Chipset/RAM. Важнейшие из этих характеристик включают в себя:
- Среднюю и максимальную реальную пропускную способность памяти (ПСП);
- Среднюю и минимальную латентность L1/L2 кэша данных и оперативной памяти;
- Ассоциативность L1/L2 кэша данных;
- Реальную пропускную способность шины L1-L2 кэша данных;
- Размер и ассоциативность каждого (при наличии нескольких) уровня D-TLB;
- Размер (в т.ч. «эффективный») и ассоциативность L1 кэша инструкций;
- Эффективность декодирования различных наборов инструкций ALU/FPU/MMX;
- Размер и ассоциативность каждого (при наличии нескольких) уровня I-TLB.
В каждом из тестов существует возможность задания пользовательских настроек или выбора одного из наборов заранее определенных настроек (Preset). Наличие последних введено для удобства ознакомления с опциями каждого из тестов и возможности сравнения систем различных классов в одних и тех же условиях. Из соображений надежности, в случае выбора любого пресета возможность модификации параметров теста блокируется. Тест №1: Тест реальной пропускной способности памяти (ПСП) (Memory BW)

Первый тест предназначен для оценки реальной пропускной способности L1/L2/L3 кэша данных и оперативной памяти (RAM). Принцип этого теста предельно прост: замеряется время (в тактах процессора), потраченное на полное чтение/запись/копирование блока данных определенного размера (который может быть как переменным, так и фиксированным) с использованием тех или иных регистров процессора (MMX, SSE или SSE2). В случае операций чтения и копирования тест также позволяет использовать различные оптимизации, направленные на достижение максимальной реальной пропускной способности при операциях чтения (Maximal Real Read Bandwidth) — методы Software Prefetch или Block Prefetch. Результат представляется в виде количества байт, переданных процессору (процессором) за один такт, а также в MB/s. Ниже перечислены настройки первого теста.
Variable Parameter
Выбор одного из трех режимов тестирования:
Block Size — построение зависимости реальной ПСП от размера блока;
PF Distance — построение зависимости реальной ПСП от длины префетча в методе Software Prefetch. Поскольку этот режим ориентирован на достижение максимальной действительной пропускной способности памяти на чтение, он рекомендуется только для больших размеров блока (заведомо больших, чем общий размер кэша данных);
Block PF Size — построение зависимости реальной ПСП от размера префетч-блока в одном из двух методов Block Prefetch. Аналогично случаю PF Distance, рекомендуется только для больших размеров блока данных.
Minimal Block Size
Minimal Block Size, KB — минимальный размер блока данных, в килобайтах, в случае Variable Parameter = Block Size; размер блока данных в остальных случаях.
Maximal Block Size
Maximal Block Size, KB — максимальный размер блока данных в случае Variable Parameter = Block Size.
Minimal PF Distance
Minimal PF Distance — минимальная длина Software Prefetch, в байтах, в случае Variable Parameter = PF Distance; длина Software Prefetch в остальных случаях. Величина 0 означает, что режим Software Prefetch не используется.
Maximal PF Distance
Maximal PF Distance — максимальная длина Software Prefetch в случае Variable Parameter = PF Distance.
Minimal Block PF Size
Minimal Block PF Size — минимальная величина Prefetch-блока, в килобайтах, в случае Variable Parameter = Block PF Size; величина Prefetch-блока в остальных случаях. Данный параметр имеет смысл только в случае использования методов Block Prefetch (1, 2), описанных ниже.
Maximal Block PF
Maximal Block PF Size — максимальная величина Prefetch-блока, в килобайтах, в случае Variable Parameter = Block PF Size.
Stride Size
Stride Size — размер шага при чтении данных в кэш в методах Block Prefetch (1, 2), в байтах. Для получения достоверных результатов этот параметр должен соответствовать длине строки кэша. Поэтому здесь и в остальных подтестах этот параметр выставлен по умолчанию как auto-detect, что означает, что будет использоваться величина размера строки кэша, автоматически определенная программой при ее запуске.
CPU Register Usage
CPU Register Usage — выбор используемых регистров для осуществления операций чтения/записи. Возможными вариантами являются 64-bit MMX, 128-bit SSE и 128-bit SSE2.
Read Prefetch Type
Read Prefetch Type — тип используемых инструкций для метода Software Prefetch (PREFETCHNTA/T0/T1/T2), а также включение одного из режимов Block Prefetch. Последние необходимы для измерения в режиме Variable Parameter = Block PF Size. Метод Block Prefetch 1 использует «начитку» строк из памяти в кэш в префетч-блок заданного размера с использованием инструкций MOV и рекомендуется для процессоров семейства AMD K7 (Athlon/Athlon XP/MP). В то же время, «начитка» данных в методе Block Prefetch 2 осуществляется с помощью одной из инструкций Software Prefetch (PREFETCHNTA). Этот метод рекомендован AMD для процессоров семейства K8 (Opteron/Athlon 64/FX).
Non-Temporal Store
Non-Temporal Store — использование режима прямого доступа в память (протокола write combining) при осуществлении операций записи. Данный режим доступа осуществляет запись данных в память без предварительного считывания старых данных в систему кэш-уровней процессора (т.е., не используя режим write allocate), что минимизирует «засорение» кэша процессора ненужными данными, в частности, при операции копирования данных.
Copy-to-Self Mode
Copy-to-Self Mode — использование режима «копирования на себя». В этом случае копирование блока данных осуществляется в ту же область памяти, где находится сам копируемый блок, т.е. фактически содержимое памяти не изменяется. По умолчанию эта опция не выбрана, и копирование осуществляется со смещением, равным длине перемещаемого блока данных. В связи со 100% попаданиями операций записи в кэш в режиме Copy-to-Self, в основном, тестируется способность памяти к чтению после записи (read around write). В этом случае утилизация кэш-памяти оказывается значительно выше, и тест является более «легким» для подсистемы памяти. Важно отметить, что режимы Non-Temporal Store и Copy-to-Self не совместимы друг с другом.
Selected Tests
Selected Tests — выбор одного или нескольких способов доступа к памяти.
Тест №2: Тест латентности/ассоциативности L1/L2 кэша данных (D-Cache Lat)Read Bandwidth — реальная пропускная способность памяти при операциях чтения;
Write Bandwidth — реальная пропускная способность памяти при операциях записи;
Copy Bandwidth — реальная пропускная способность памяти при операциях копирования.

Второй тест предназначен для определения средней/минимальной латентности L1/L2 кэша данных и памяти, размера строки L2 кэша и степени ассоциативности L1/L2 кэша данных. Ниже перечислены его параметры и рассмотрены основные режимы его работы.
Variable Parameter
Выбор одной из четырех разновидностей теста:
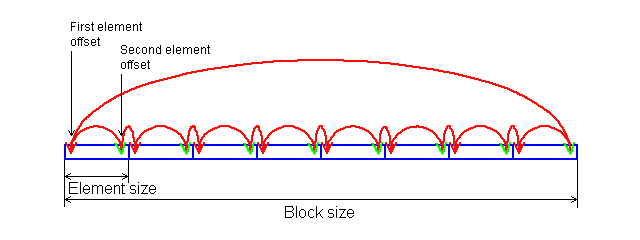
Block Size — построение зависимости латентности кэша данных/памяти от размера блока. Данный режим теста позволяет получить общую картину латентности различных областей подсистемы памяти — L1, L2, L3 (при наличии такового) кэша данных или оперативной памяти (RAM). Принцип его работы следующий: в выделенной области памяти создается цепочка зависимого доступа, каждый элемент которой содержит в себе адрес последующего элемента. При этом соблюдается условие, что на каждой полной итерации чтения к каждому элементу цепочки будет осуществлено строго одно обращение. Количество элементов цепочки берется равное размеру блока, деленному на величину шага по цепочке (Stride Size, см. ниже). В случае если размер шага соответствует длине строки кэша, размер блока является истинной характеристикой количества прочитанных данных (поскольку считывание данных из оперативной памяти в L2 кэш или из L2 кэша в L1 кэш осуществляется «построчно»). Таким образом, использование размеров блока, меньших или равных размеру L1 кэша позволяет оценить латентность доступа (load-use latency) к первому уровню кэша; размер блока в интервале (L1..L1+L2) или (L1..L2), в зависимости от архитектуры кэша (эксклюзивной и инклюзивной, соответственно) даст нам оценку латентности второго уровня (L2) кэша, и, наконец (поскольку L3 кэш является сравнительно редким явлением), размер блока, заведомо больший, чем сумма объемов L1+L2 кэша позволяет нам оценить латентность доступа к оперативной памяти (RAM). Порядок обхода цепочки зависит от выбранного метода тестирования (см. ниже). В случае прямого последовательного доступа (Forward Read Latency) обход осуществляется строго с первого элемента по последний, при этом последний элемент цепочки содержит указатель на первый, что позволяет многократно повторять операцию обхода. В случае обратного последовательного доступа (Backward Read Latency) первый элемент цепочки содержит адрес последнего элемента, после чего чтение осуществляется от последнего элемента к первому. Наконец, случайный доступ (Random Read Latency), как следует из его названия, характеризуется случайной последовательностью элементов в цепочке, однако условие выборки каждого из элементов строго по одному разу сохраняется. Для примера, ниже на рисунке изображен принцип прямого последовательного обхода цепочки из 8 элементов.

Stride Size — построение зависимости латентности кэша от размера шага. Использование этого режима теста является осмысленным только для размеров блока, попадающих в L2 кэш, и позволяет определить длину строки последнего. Данный метод определения длины строки кэша является далеко не единственным — в RMMA реализовано три таких метода, остальные из которых будут рассмотрены ниже.
Chains Count — построение зависимости латентности кэша от количества последовательных зависимых цепочек доступа, позволяющей оценить ассоциативность L1/L2 кэша данных. «Количество» цепочек — это условное понятие, т.к. реально осуществляется обход одной и той же цепочки зависимого доступа. Единственное отличие «многоцепочечного» варианта от «одноцепочечного» заключается в том, что в этом случае чтение данных осуществляется не в пределах одной и той же области памяти, а из разных областей (количество которых равно числу «цепочек»), расположенных друг относительно друга со смещением, кратным размеру сегмента кэша. Чтобы все это выглядело менее запутанно, проиллюстрируем, как осуществляется прямой последовательный обход массива при количестве цепочек, равном четырем.

Для определения такого важного параметра кэша процессора, как степень его ассоциативности, достаточно последовательно увеличивать число зависимых цепочек доступа, сохраняя минимальным размер блока данных. Последний факт доказывает, что «испортить жизнь» кэшу процессора очень легко — для этого вовсе не обязательно «засорять» весь его объем. На деле, для того, чтобы «пробить» ассоциативность n-way set associative кэша, достаточно прочитать всего лишь n строк кэша по строго определенным адресам, имеющим относительное смещение, кратное размеру сегмента кэша. Именно это обстоятельство и эксплуатирует данный подтест. Для примера, чтобы показать «полную несостоятельность» кэша L2 процессора Pentium 4 размером 512K, имеющего степень ассоциативности n = 8 и размер строки 64 байт достаточно будет прочитать всего лишь 8 x 64 = 512 байт данных, т.е. занять меньше 0.1% его объема(!). В качестве минимального размера сегмента кэша в текущей реализации теста выбрано значение, равное 1MB. Столь большое значение гарантирует, что тест будет корректно определять степень ассоциативности L2/L3 кэша данных даже в системах с большим объемом последнего (отметим, что сегмент кэша, равный 1MB, соответствует, например, 8MB кэшу данных третьего уровня со степенью ассоциативности, равной 8).
NOP Count — построение зависимости латентности выбранной области (L2 кэша или памяти) от количества «пустых» операций, вставленных между двумя последующими обращениями к выбранной области (L2 кэшу или памяти). Эти операции, называемые для краткости «NOP»-ами, не связаны с доступом в кэш, но приводят к появлению фиксированного временного промежутка между двумя последующими обращениями к разным строкам кэша/памяти, что позволяет «разгрузить» шину данных, соответствующую коммуникации между L1-L2 или L2-RAM, соответственно, и достичь таким образом минимального значения латентности доступа к выбранной подсистеме памяти. В текущей реализации RMMA в качестве такой «пустой» операции используется команда x86 ALU or eax, edx (при этом в eax хранится адрес элемента цепочки, а edx инициализирован нулем), которая, как показывает практика, одинаково хорошо подходит для тестирования большинства современных процессоров.
Minimal Block Size, KB
Minimal Block Size, KB — минимальный размер блока данных, в килобайтах, в случае Variable Parameter = Block Size; размер блока данных в остальных случаях.
Maximal Block Size, KB
Maximal Block Size, KB — максимальный размер блока данных в случае Variable Parameter = Block Size.
Minimal NOP Count
Minimal NOP Count — минимальное количество вставленных «пустых» операций в случае Variable Parameter = NOP Count; количество вставленных «пустых» операций в остальных случаях.
Maximal NOP Count
Maximal NOP Count — максимальное количество вставленных «пустых» операций в случае Variable Parameter = NOP Count.
Minimal Chains Count
Minimal Chains Count — минимальное количество последовательных зависимых цепочек доступа в случае Variable Parameter = Chains Count; количество последовательных зависимых цепочек доступа в остальных случаях. Как было сказано выше, смещение каждой из таких зависимых цепочек доступа от соседней составляет величину, кратную максимально возможному размеру сегмента кэша.
Maximal Chains Count
Maximal Chains Count — максимальное количество последовательных зависимых цепочек доступа в случае Variable Parameter = Chains Count.
Minimal Stride Size
Minimal Stride Size — минимальная величина шага, в байтах, по зависимой цепочке доступа (каждой из них, в случае нескольких цепочек) в случае Variable Parameter = Stride Size; величина шага по зависимой цепочке доступа в остальных случаях.
Maximal Stride Size
Maximal Stride Size — максимальная величина шага по зависимой цепочке доступа в случае Variable Parameter = Stride Size.
Latency Measurement
Latency Measurement — используемая методика определения минимальной латентности (параметр доступен для конфигурирования только в режиме Variable Parameter = NOP Count). В методе №1 (Method 1) для определения минимальной латентности используется обычная цепочка зависимого доступа со вставкой переменного количества «пустых» операций, рассмотренных выше (edx = 0):
// загрузка следующего элемента цепочки
mov eax, [eax]
// разгрузка шины, переменное количество «пустых» операций
or eax, edx
…
or eax, edx
Тем не менее, в ряде случаев (если эффективно работает спекулятивная загрузка) минимальная латентность кэша может не достигаться таким способом. Для достижения минимальной латентности в подобных случаях в RMMA реализована альтернативная методика (Method 2), в которой используется несколько иной код обхода цепочки (ebx = edx = 0):
// разгрузка шины, фиксированное количество «пустых» операций
add ebx, edx
…
add ebx, edx
// загрузка следующего элемента цепочки
mov eax, [eax+ebx]
and ebx, eax
// разгрузка шины, переменное количество «пустых» операций
add ebx, edx
…
add ebx, edx
Selected Tests
Selected Tests — выбор способов обхода цепочки при тестировании латентности.
Тест №3: Тест реальной пропускной способности шины L1/L2 кэша данных (D-Cache BW)Forward Read Latency — латентность прямого последовательного доступа;
Backward Read Latency — латентность обратного последовательного доступа;
Random Read Latency — латентность случайного доступа.

Третий тест предназначен для оценки реальной пропускной способности шины L1-L2 кэша (с таким же успехом его можно использовать для оценки ПС шины L2-RAM). Он является, пожалуй, наиболее простым из реализованных в RMMA тестов в плане его конфигурирования. В сущности, в его основе лежит тот же метод, что и в тесте реальной пропускной способности L1/L2/RAM (тест №1). Отличие заключается в том, что чтение/запись блока памяти в этом тесте осуществляется «построчно», т.е. с шагом, равным длине строки кэша и использованием ALU регистров процессора. Поддерживается как прямой, так и обратный режим доступа. Параметрами этого теста являются:
Variable Parameter
Variable Parameter — выбор одного из двух режимов работы теста:
Block Size — построение зависимости реальной ПС шины данных от размера блока данных;Stride Size — построение зависимости реальной ПС шины L1-L2 или L2-RAM от величины шага. Данный режим является вторым из возможных способов определения размера длины строки кэша.
Minimal Block Size, KB
Minimal Block Size, KB — минимальный размер тестируемого блока, в килобайтах, в случае Variable Parameter = Block Size; размер блока данных в остальных случаях. Задание величины, меньшей чем (по крайней мере) полуторный размер кэша L1 приведет к бессмысленным результатам. Действительно, данный тест не позволяет оценить пропускную способность связки L1-LSU-registers, потому что загрузка данных из L1 в LSU (Load-Store Unit) и, далее, в регистры процессора осуществляется отнюдь не «построчно». Для оценки ПС L1-LSU гораздо лучше использовать первый тест (Memory BW) в области размеров блока, попадающих в L1 кэш.
Maximal Block Size, KB
Maximal Block Size, KB — максимальный размер тестируемого блока, в килобайтах. Указание величины, меньшей, чем размер L2 (инклюзивная архитектура кэша) или L1+L2 (эксклюзивная архитектура кэша) позволяет оценить реальную ПС шины L1-L2. При задании интервала значений Block Size от L1+L2 до некоторого заведомо большего значения с помощью данного теста можно оценить максимальную действительную пропускную способность памяти (ПСП) при операциях чтения/записи целых строк кэша, которая в ряде случаев оказывается выше, чем максимальная реальная ПСП при операциях тотального чтения/записи данных.
Minimal Stride Size
Minimal Stride Size — минимальная величина шага доступа к кэшу при осуществлении операций чтения/записи в случае Variable Parameter = Stride Size; величина шага доступа к кэшу в остальных случаях.
Selected Tests
Selected Tests — выбор вида измерений.
Тест №4: Тест прибытия данных по шине L1/L2 (D-Cache Arrival)Forward Read Bandwidth — прямое последовательное чтение строк кэш;
Backward Read Bandwidth — обратное последовательное чтение строк кэш;
Forward Write Bandwidth — прямая последовательная запись строк кэш;
Backward Write Bandwidth — обратная последовательная запись строк кэш;

Четвертый тест предназначен для тестирования деталей реализации шины L1-L2 кэша данных (разрядность, мультиплексность) некоторых процессоров с эксклюзивной архитектурой кэша, в частности, процессоров семейства AMD K7/K8. В этом тесте, по сути, измеряется суммарная латентность двух обращений к одной и той же строке кэша, отстоящих друг относительно друга на заданную величину. Лежащий в основе метод измерений идентичен реализованному в тесте №2, который мы рассматривали выше, за исключением того, что два соседних элемента цепочки находятся в одной и той же строке кэша. Для наглядности изобразим это на следующем рисунке.
Кроме того, четвертый тест можно использовать для определения размера строки кэша L2 (это является третьим реализованным в RMMA способом определения последней, который, кстати, используется для ее измерения при запуске программы). Параметры четвертого теста таковы:
Variable Parameter
Variable Parameter — выбор одной из пяти разновидностей теста:
Block Size — построение зависимости суммарной латентности от размера блока.
NOP Count — построение зависимости суммарной латентности от количества «пустых» операций, вставленных между двумя последующими обращениями к разным строкам кэша.
SyncNOP Count — построение зависимости суммарной латентности от количества «пустых» операций, вставленных между двумя последующими обращениями к одной и той же строке кэша.
1st DW Offset — построение зависимости суммарной латентности от смещения первого слова в пределах строки кэша.
2nd DW Offset — построение зависимости суммарной латентности от смещения второго слова в пределах строки кэша.
Minimal Block Size, KB
Minimal Block Size, KB — минимальный размер блока данных, в килобайтах, в случае Variable Parameter = Block Size; общий размер блока данных в остальных случаях.
Maximal Block Size, KB
Maximal Block Size, KB — максимальный размер блока данных в случае Variable Parameter = Block Size.
Minimal NOP Count
Minimal NOP Count — минимальное количество вставленных «пустых» операций между двумя последующими обращениями к соседним строкам кэша в случае Variable Parameter = NOP Count; количество вставленных «пустых» операций между двумя последующими обращениями к соседним строкам кэша в остальных случаях.
Maximal NOP Count
Maximal NOP Count — максимальное количество вставленных «пустых» операций между двумя последующими обращениями к соседним строкам кэша в случае Variable Parameter = NOP Count.
Minimal SyncNOP Count
Minimal SyncNOP Count — минимальное количество вставленных «пустых» операций между двумя последующими обращениями к одной и той же строке кэша в случае Variable Parameter = SyncNOP Count; количество вставленных «пустых» операций между двумя последующими обращениями к одной и той же строке кэша в остальных случаях.
Maximal SyncNOP Count
Maximal SyncNOP Count — максимальное количество вставленных «пустых» операций между двумя последующими обращениями к одной и той же строке кэша в случае Variable Parameter = SyncNOP Count.
Stride Size
Stride Size — величина шага, в байтах, по зависимой цепочке доступа между двумя последовательными обращениями к соседним строкам кэша.
Minimal 1st Dword Offset
Minimal 1st Dword Offset — минимальная величина смещения первого слова в пределах строки кэша, в байтах, в случае Variable Parameter = 1st DW Offset; величина смещения первого слова в пределах строки кэша в остальных случаях.
Maximal 1st Dword Offset
Maximal 1st Dword Offset — максимальная величина смещения первого слова в пределах строки кэша в случае Variable Parameter = 1st DW Offset.
Minimal 2nd Dword Offset
Minimal 2nd Dword Offset — минимальная величина смещения второго слова в пределах строки кэша, в байтах, в случае Variable Parameter = 2nd DW Offset; величина смещения второго слова в пределах строки кэша в остальных случаях. Смещение второго слова вычисляется относительно смещения первого слова, по модулю величины шага (размера строки кэша):
2nd_Dword_Offset = (2nd_Dword_Offset + 1st_Dword_Offset) % Stride_Size
Maximal 2nd Dword Offset
Maximal 2nd Dword Offset — максимальная величина смещения второго слова в пределах строки кэша в случае Variable Parameter = 2nd DW Offset.
Selected Tests
Selected Tests — выбор способов тестирования латентности двойного доступа.
Тест №5: Тест трансляционного буфера данных (D-TLB)Forward Two-Dword Read Latency — латентность двойного обращения при прямом последовательном доступе;
Backward Two-Dword Read Latency — латентность двойного обращения при обратном последовательном доступе;
Random Two-Dword Read Latency — латентность двойного обращения при случайном доступе.

Пятый тест предназначен для определения объема и степени ассоциативности трансляционного буфера данных (Translation Lookaside Buffer, L1/L2 D-TLB). В этом тесте, фактически, измеряется латентность доступа в L1 кэш, но при том условии, что каждая последующая строка кэша загружается не из той же самой, а из следующей страницы памяти.

(В скобках заметим, что размер страницы памяти в реальных операционных системах гораздо больше (для примера, 4096 байт), чем в нашей схеме, где в нее помещается всего 4 строки кэша).
Таким образом, если количество задействованных страниц меньше размера TLB данных, мы определяем собственную латентность кэша L1 (TLB hit). В противном случае измеряется латентность кэша L1 в условиях промаха TLB (TLB miss). Важно отметить, что максимальное количество задействованных страниц памяти (Maximal TLB Entries) не должно превышать количество строк L1 кэша, иначе кривая зависимости будет иметь скачок, связанный с попаданием из области L1 в область L2, но не связанный с размером структуры D-TLB. Следует отметить, что общий размер уровней TLB всегда оказывается заведомо меньшим, чем количество кэш-линий, помещающихся в L1 кэше (чему можно придумать вполне объективное объяснение). Настройки этого теста таковы:
Variable Parameter
Variable Parameter — выбор одного из двух режимов работы теста.
TLB Entries — построение зависимости латентности доступа в L1 кэш от количества задействованных страниц памяти.
Chains Count — построение зависимости латентности доступа в L1 кэш от количества последовательных цепочек доступа при заданном количестве задействованных страниц, позволяющей оценить степень ассоциативности каждого из уровней D-TLB. Принцип построения «цепочек» аналогичен применяемому в тесте латентности (тест №2), но в этом случае к величине смещения между «цепочками» добавляется величина, равная шагу при обращении к каждому последующему элементу (длине строки кэша). Для наглядности, изобразим обход четырех элементов TLB при двух «цепочках» доступа.

Stride Size
Stride Size — шаг доступа по зависимой цепочке данных, в байтах.
Minimal TLB Entries
Minimal TLB Entries — минимальное количество используемых страниц памяти, по которым осуществляется считывание кэш-линий, в случае Variable Parameter = TLB Entries; количество используемых страниц памяти в остальных случаях.
Maximal TLB Entries
Maximal TLB Entries — максимальное количество используемых страниц памяти в случае Variable Parameter = TLB Entries.
Minimal Chains Count
Minimal Chains Count — минимальное количество последовательных зависимых цепочек доступа в случае Variable Parameter = Chains Count; количество последовательных зависимых цепочек доступа в остальных случаях.
Maximal Chains Count
Maximal Chains Count — максимальное количество последовательных зависимых цепочек доступа в случае Variable Parameter = Chains Count.
Selected Tests
Selected Tests — выбор способов тестирования.
Тест №6: Тест кэша инструкций (I-Cache)Forward Access — прямой последовательный доступ;
Backward Access — обратный последовательный доступ;
Random Access — случайный доступ.
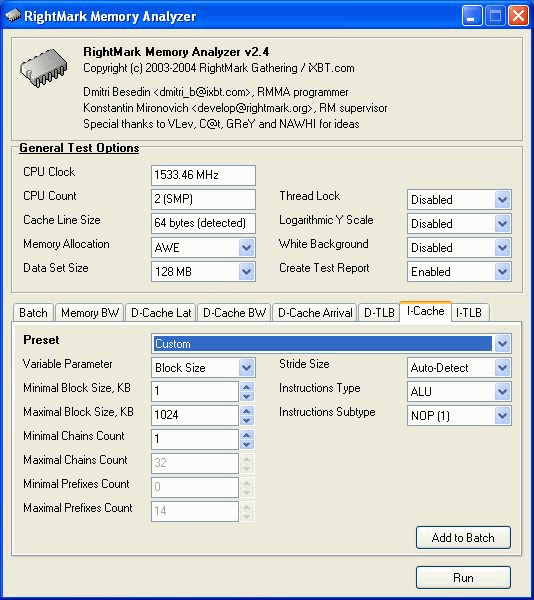
Шестой тест позволяет оценить эффективность декодирования/исполнения ряда простых команд процессора (ALU/FPU/MMX), а также эффективность работы L1 кэша инструкций и ассоциативность последнего. Он представляет особый интерес для оценки эффективного объема Trace Cache процессоров семейства Pentium 4 при декодировании/исполнении различных инструкций. Параметры этого теста перечислены ниже.
Variable Parameter
Выбор одного из трех типов данного теста:
Block Size — построение зависимости скорости декодирования от размера блока кода (здесь и далее под «скоростью декодирования» (Decode Bandwidth) будем понимать скорость последовательности операций считывания, декодирования и исполнения инструкций процессором). Методика тестирования заключается в создании блока кода заданного размера «на лету» (в runtime) и измерении количества тактов процессора, потраченных на его исполнение. Последней инструкцией в блоке кода во всех случаях является инструкция возврата контроля вызывающей процедуре (RET).
Chains Count — построение зависимости скорости декодирования от количества последовательных цепочек доступа. По аналогии с тестом №2, это позволяет определить степень ассоциативности L1 кэша инструкций. С методологической точки зрения, переходы между соседними «цепочками», соответствующими разным сегментам кэша, осуществляются с помощью команды безусловного перехода jmp. Для примера на рисунке приведена схема исполнения кода (красные стрелки) в случае использования двух «цепочек» (операции перехода отмечены зелеными стрелками).

Prefixes Count — построение зависимости скорости декодирования инструкций вида [pref]nNOP от количества используемых префиксов (pref = 0x66, operand-size override prefix).
Minimal Block Size, KB
Minimal Block Size, KB — минимальный размер блока кода, в килобайтах, в случае Variable Parameter = Block Size; размер блока кода в остальных случаях.
Maximal Block Size, KB
Maximal Block Size, KB — максимальный размер блока кода в случае Variable Parameter = Block Size.
Minimal Chains Count
Minimal Chains Count — минимальное количество последовательных цепочек доступа в случае Variable Parameter = Chains Count; количество последовательных цепочек доступа в остальных случаях.
Maximal Chains Count
Maximal Chains Count — максимальное количество последовательных цепочек доступа в случае Variable Parameter = Chains Count.
Minimal Prefixes Count, Maximal Prefixes Count
Minimal Prefixes Count, Maximal Prefixes Count — минимальное и максимальное количество префиксов в случае Variable Parameter = Prefixes Count. Недоступны в остальных случаях.
Stride Size
Stride Size — минимальный размер исполняемого кода в данной цепочке, включающий в себя операцию перехода на соседнюю цепочку, рекомендуется выбрать равным размеру строки кэша инструкций.
Instructions Type
Instructions Type — тип декодируемых/исполняемых инструкций:
ALU — арифметическо-логические целочисленные операции с использованием регистров общего назначения;
FPU — некоторые элементарные и вычислительные операции, осуществляемые блоком вычислений с плавающей точкой (FPU);
MMX — арифметическо-логические целочисленные операции, использующие блок MMX процессора.
Instructions Subtype
Instructions Subtype — подтип декодируемых/исполняемых инструкций. Зависит от выбранного типа инструкций. В скобках указан размер инструкции, в байтах.
| Тип инструкций | Подтип инструкций | Операция |
|---|---|---|
| ALU | NOP (1) LEA (2) MOV (2) ADD (2) SUB (2) OR (2) XOR (2) TEST (2) CMP (2) SHL (3) ROL (3) XOR/ADD (4) CMP-0 (4) CMP-0 (6) CMP-8 (6) CMP-16 (6) CMP-32 (6) CMP-0 (8) CMP-8 (8) CMP-16 (8) CMP-32 (8) | nop lea eax, [eax] mov eax, eax add eax, eax sub eax, eax or eax, eax xor eax, eax test eax, eax cmp eax, eax shl eax, 0 rol eax, 0 xor eax, eax; add eax, eax cmp ax, 0x00 cmp eax, 0x00000000 cmp eax, 0x0000007f cmp eax, 0x00007fff cmp eax, 0x7fffffff [rep][addrovr]cmp eax, 0x00000000 [rep][addrovr]cmp eax, 0x0000007f [rep][addrovr]cmp eax, 0x00007fff [rep][addrovr]cmp eax, 0x7fffffff |
| FPU | WAIT (1) FADD (2) FMUL (2) FSUB (2) FSUBR (2) FCHS (2) FABS (2) FTST (2) FXAM (2) FCOM (2) FCOMI (2) FST (2) FXCH (2) FDECSTP (2) FINCSTP (2) FFREE (2) FFREEP (2) | wait fadd st(0), st(1) fmul st(0), st(1) fsub st(0), st(1) fsubr st(0), st(1) fchs fabs ftst fxam fcom st(1) fcomi st(0), st(1) fst st(0) fxch fdecstp fincstp ffree st(0) ffreep st(0) |
| MMX | EMMS (2) MOVQ (3) POR (3) PXOR (3) PADDD (3) PSUBD (3) PCMPEQD (3) PUNPCKLDQ (3) PSLLD (4) | emms movq mm0, mm0 por mm0, mm0 pxor mm0, mm0 paddd mm0, mm0 psubd mm0, mm0 pcmpeqd mm0, mm0 punpckldq mm0, mm0 pslld mm0, 0 |

Последний из реализованных в RMMA тестов предназначен для определения объема и степени ассоциативности трансляционного буфера инструкций (Instructions Translation Lookaside Buffer, L1/L2 I-TLB). Настройки этого теста являются абсолютно такими же, как и у теста №5:
Variable Parameter
Variable Parameter — выбор одного из двух режимов работы теста:
TLB Entries — построение зависимости латентности доступа в L1i от количества задействованных страниц памяти.
Chains Count — построение зависимости латентности доступа в L1i от количества последовательных цепочек доступа при заданном количестве задействованных страниц.
Stride Size — шаг доступа по зависимой цепочке данных, в байтах. Шаг по цепочке осуществляется операцией безусловного перехода (jmp). Для примера, на рисунке приведен прямой последовательный обход четырех элементов I-TLB с двумя цепочками доступа.

Последний элемент цепочки, обозначенный крестиком, содержит в себе инструкцию возврата контроля вызывающей процедуре (ret).
Minimal TLB Entries
Minimal TLB Entries — минимальное количество используемых страниц памяти, по которым осуществляется обращение к кэш-линиям L1i, в случае Variable Parameter = TLB Entries; количество используемых страниц памяти в остальных случаях.
Maximal TLB Entries
Maximal TLB Entries — максимальное количество используемых страниц памяти в случае Variable Parameter = TLB Entries.
Minimal Chains Count
Minimal Chains Count — минимальное количество последовательных зависимых цепочек доступа в случае Variable Parameter = Chains Count; количество последовательных зависимых цепочек доступа в остальных случаях.
Maximal Chains Count
Maximal Chains Count — максимальное количество последовательных зависимых цепочек доступа в случае Variable Parameter = Chains Count.
Selected Tests
Selected Tests — выбор способов тестирования.
Forward Access — прямой последовательный доступ;
Backward Access — обратный последовательный доступ;
Random Access — случайный доступ.
Следует отметить, что «латентность», выдаваемая в результатах тестирования, в данном случае является весьма условным понятием. Фактически, можно говорить о латентности исполнения связки инструкций
mov ecx, address_value
jmp ecx
при различном их количестве и относительном расположении. Тем не менее, такая характеристика является вполне приемлемой для определения структуры уровней I-TLB и их ассоциативности. Приложение 1: RightMark Memory Analyzer 2.5
Изменения и дополнения
Проведенные нами и представленные вашему вниманию первые сравнительные тестирования различных платформ (AMD K7/K8, Intel Pentium 4, Intel Pentium III / Pentium M) позволили выявить ряд основных моментов, которые в предыдущей версии RightMark Memory Analyzer 2.4 были либо реализованы недостаточно хорошо, либо не были реализованы вовсе. Обнаруженные недочеты были учтены при разработке новой версии тестового пакета, рассмотрению которой и посвящено это небольшое приложение.
Общие настройки теста (General)

Как можно заметить по представленному рисунку, основным изменением этого раздела является введение автоматического определения размера строки обоих уровней кэша данных (L1 Cache Line Size, L2 Cache Line Size). Ранее этот момент несколько умалчивался, но фактически измерялся и отображался размер строки только первого уровня кэша. Тем не менее, теория и практика показали, что эффективные размеры строк L1 и L2 у некоторых процессоров могут отличаться. Рассмотрим, для примера, процессоры семейства Intel Pentium 4. Эффективный размер строки L2 у этих процессоров — 128 байт (точнее, такая строка называется «двухсекторной», и состоит она из двух «обычных» 64-байтных строк), что означает, что пересылка данных по шине L2-RAM (или L2-L3, L3-RAM у процессоров Pentium 4 XE) осуществляется сразу по 128 байт за одно обращение.
В связи с этим значения, получаемые в тесте D-Cache Bandwidth при оценке реальной пропускной способности шины L2-RAM (L2-L3, L3-RAM) оказывались заниженными, если использовался размер шага, равный автоматически определенному размеру строки (первого уровня кэша), а для получения объективных характеристик требовалось указание правильного размера шага вручную. Этот недостаток был устранен — в соответствующем разделе теста появилась возможность выбора параметра Minimal Stride Size, равного как размеру строки L1, так и L2 (что продемонстрировано на приведенном выше скриншоте).
Вернемся к общим настройкам теста. Здесь присутствует еще один новый параметр, Active CPU Index, предоставляющий возможность указания номера активного CPU (физического или логического), на котором будет исполняться главный поток теста. В то время как данная опция довольно бесполезна для обычных SMP- (и уж тем более, HT-) систем, ее можно с интересом применять для изучения различий в поведении системы при обращении CPU к «своей» и «чужой» памяти, в системах с раздельной архитектурой последней (яркий тому пример — двухпроцессорные платформы AMD K8, в которых каждый процессор «наделен» собственной памятью).
Наконец, отметим последнее изменение в этом разделе — это возможность выбора одного из трех способов выделения памяти (Memory Allocation): Standard, VirtualLock и AWE. Первый использует обычный malloc() и не рекомендуется для обычного тестирования платформ. Он введен, в основном, для изучения возможности работы теста под менеджерами памяти, отличными от стандартного менеджера памяти ОС Windows и имеющими те или иные преимущества (например, поддержку «больших» 4МБ страниц памяти). Напомним, что для получения достоверных и воспроизводимых результатов по-прежнему рекомендуется использовать метод, использующий расширения AWE, в связи с чем он выбран по умолчанию.
Тест №1: Memory Bandwidth
Главные изменения этого теста коснулись процедур чтения/записи/копирования памяти во всех режимах доступа (MMX, SSE, SSE2), в т.ч. методов, использующих Software Prefetch. Применение большего фактора «раскручивания» циклов позволило оптимизировать режим работы этих процедур в области малых размеров блока (в области L1 кэша данных) и увеличить достигаемые значения реальной пропускной способности этого уровня кэша.
Тест №2: D-Cache Latency

Существенным дополнением этого теста является введение нового режима обхода памяти, названного псевдослучайным (Pseudo-Random Read Latency) и разработанного с целью уменьшения величин латентности случайного доступа к памяти. В этом режиме обход цепочки зависимого доступа является случайным в пределах каждой страницы памяти, но при этом обход страниц памяти в целом осуществляется прямым последовательным образом.

Первое обстоятельство минимизирует вмешательство алгоритма Hardware Prefetch, а второе приводит к практически полному устранению промахов D-TLB. В связи с этим латентность псевдослучайного обхода оказывается заметно меньшей по сравнению с латентностью при случайном обходе (который зачастую осуществляется в условиях значительного количества промахов D-TLB) и вполне может претендовать на звание объективной характеристики латентности памяти.
Вторым изменением этого теста является изменение процедуры построения зависимости латентности выбранного уровня подсистемы памяти (L1/L2 кэш/RAM) от величины шага (Variable Parameter = Walk Size). В предыдущей реализации RMMA реальное количество шагов по цепочке зависимого доступа в этом подтесте определялось как размер блока, деленный на величину шага (которая являлась переменной), что приводило к значительному уменьшению количества шагов по мере увеличения их размера. В новой версии теста количество шагов является фиксированным (не зависящим от размера шага, границы которого задаются новыми параметрами Minimal Walk Size и Maximal Walk Size). Оно определяется как размер блока, деленный на «базовую» величину шага (Stride Size, которая по умолчанию берется равной длине строки L1 кэша).