

Введение
Со времени написания обзора NVPerfKit 2 прошло более года. Всё это время мы использовали PerfKit и PerfHUD для анализа современных игр в цикле статей 3D-технологии в играх, а игровые разработчики применяли упомянутые средства при работе над своими проектами. С того времени изменилось многое: появилась новая операционная система Microsoft Windows Vista, обновился DirectX API, добравшийся до десятой версии, а компанией Nvidia была выпущена новая линейка видеокарт на основе чипов G8x с поддержкой этого API.
Естественно, та устаревшая версия PerfKit не могла обеспечить поддержку этих нововведений, которые были важны для игровых разработчиков, и пакету понадобилось большое обновление. И в конце этого лета Nvidia выпустила PerfKit 5, наиболее многочисленные изменения в котором претерпела утилита PerfHUD. Как видите, оба названия отказались от префикса NV, теперь они называются Nvidia PerfKit и Nvidia PerfHUD, соответственно.
Упомянутые средства важны для 3D-разработчиков, так как современные трехмерные приложения очень сложны, и чтобы программисты могли полноценно использовать все возможности новых видеочипов, нужны утилиты, помогающие обнаруживать ошибки и «узкие» места в производительности. При рендеринге видеочипы выполняют множество различных операций графического конвейера, общая производительность приложения зависит от наиболее медленного участка, поэтому нужны удобные средства определения подобных мест. А ведь сложность графического конвейера за последние годы возросла, и разобраться в этих процессах без удобных инструментов очень сложно. Тем более что унификация шейдеров (вершинных, геометрических и пиксельных) изменила подход к оптимизации 3D-приложений. Привычный подход перекладывания расчетов от пикселей к вершинам и наоборот может не работать, особенно если количество вершин будет примерно равно количеству пикселей. Ведь теперь нет упора в производительность пиксельных или вершинных шейдеров по отдельности, а есть упор в производительность универсальных шейдерных блоков.
В прошлом существовали только простейшие средства отладки, и лишь затем появились специализированные инструменты, такие как PerfHUD. Утилита успешно используется при разработке большинства известных игровых проектов всеми крупными разработчиками. Достаточно привести несколько имён: Battlefield 2142 (DICE), World of Warcraft (Blizzard Entertainment), Gamebryo (Emergent Technologies) — TES4: Oblivion, Company of Heroes (Relic Entertainment), Settlers VI (Blue Byte). Эти названия приводит сама Nvidia, а исходя из наших исследований, PerfHUD использовался и при разработке следующих проектов: Armed Assault, Gothic 3, Far Cry, Serious Sam 2, S.T.A.L.K.E.R., Dark Messiah of Might and Magic, Need for Speed: Carbon, Test Drive: Unlimited, Splinter Cell: Double Agent, GTR 2 и многих других.
Естественно, такое широкое применение достигнуто PerfHUD не просто так, эта утилита действительно помогает разработчикам проще и эффективнее оптимизировать их проекты. По информации Nvidia, сотни пользователей PerfHUD получили улучшение производительности в своих программах. PerfHUD выгодно отличается от схожих по смыслу утилит тем, что он работает в реальном времени вместе с исследуемым приложением, и вся работа по отлову ошибок и узких мест проходит прямо в приложении, в то время как другие утилиты используют оффлайновый анализ, что менее удобно. Новая версия PerfKit 5 выложена в свободный доступ на сайте Nvidia для разработчиков, мы предлагаем вашему вниманию обзор его возможностей.
Описание набора PerfKit 5
Итак, PerfKit 5 — это набор программ для разработчиков 3D-приложений, содержащий мощные средства для анализа производительности Direct3D и OpenGL приложений при помощи счетчиков производительности драйвера и аппаратных счетчиков GPU. Счетчики производительности могут использоваться для обнаружения причин низкой производительности трехмерных приложений и для определения того, насколько полно конкретное приложение использует имеющиеся возможности видеочипов.
Компоненты, входящие в состав PerfKit 5:
- Инструментальный драйвер (instrumented driver) Nvidia ForceWare, с интерфейсом Performance Data Helper (PDH).
- PerfHUD 5.0 — мощная утилита для анализа производительности Direct3D 9 и Direct3D 10 приложений.
- Плагин Nvidia для Microsoft PIX for Windows — плагин, импортирующий данные счетчиков Nvidia в известную программу отладки, входящую в состав DirectX SDK.
- PerfSDK — средство доступа к счетчикам производительности из пользовательских OpenGL и Direct3D приложений, с примерами исходного кода.
- GLExpert — часть PerfKit, предназначенная для анализа производительности и отладки OpenGL приложений.
Одно из важных отличий PerfKit от других средств в том, что возможности пакета для Direct3D приложений хотя и богаче таковых, по сравнению с OpenGL, но менее популярный среди игровых разработчиков API также поддерживается. Для отладки соответствующих приложений компания Nvidia рекомендует использовать утилиту gDEBugger, пробная версия которой ранее поставлялась вместе с PerfKit, а теперь её можно скачать на сайте компании для разработчиков.
Системные требования PerfKit 5
- Видеокарта на основе современного видеочипа компании Nvidia из следующего списка: NV40, NV43, G70, G72, G80, G84. Как видите, в этот раз решения ограничены mid-end и high-end видеокартами серий Geforce 8, Geforce 7 и Geforce 6, а также соответствующими им профессиональными видеокартами семейства Quadro FX. Ранние видеочипы не поддерживаются или поддерживаются с ограниченной функциональностью.
- Операционная система Microsoft Windows XP или Windows Vista с установленным последним обновлением Microsoft DirectX (желательно иметь и последнюю версию DirectX SDK).
- Специальные отладочные драйверы Nvidia (инсталлятор PerfKit 5 сам устанавливает нужную версию, включая возможности отладки по умолчанию).
Установка специального драйвера обязательна, чтобы использовать набор PerfKit. Подобные специфические драйверы называются инструментальными (instrumented driver) или отладочными, они содержат дополнительный код для мониторинга и измерения производительности. Отладочные инструменты, такие как PerfHUD, используют связь с драйверами для получения необходимой информации о работе видеочипа и драйвера Nvidia. Инструментальные драйверы не рекомендуется использовать для обычного сравнительного тестирования производительности, так как они оказывают дополнительное влияние на скорость рендеринга. Впрочем, это отрицательное влияние не превышает нескольких процентов, и его можно отключить в панели управления Nvidia.
Рассмотрим основные особенности PerfKit по отдельности, и начнем с краткого описания самих счетчиков производительности, так как это основа всего набора утилит, в том числе и наиболее популярной утилиты PerfHUD, которая активно использует данные счетчиков.
Счетчики производительности PerfKit
Счетчики в PerfKit нескольких типов: аппаратные счетчики, считывающие данные из видеочипа, программные Direct3D и OpenGL счетчики, содержащие данные, полученные от отладочного драйвера. Есть так называемые «упрощенные эксперименты» (simplified experiments) — многопроходные операции, дающие подробную информацию о состоянии видеочипа.
Аппаратные счетчики GPU содержат данные, накопленные со времени прошлого опроса. Например, значение количества треугольников в счетчике setup_triangle_count равно числу полигонов, обработанных за время, прошедшее с момента последнего опроса счетчика. При использовании PDH для считывания данных со счетчиков, например, из встроенной утилиты Performance Monitor (PerfMon) из Windows, они будут опрашиваться раз в секунду, а при внедрении счетчиков в свои приложения, можно брать отсчеты сколь угодно часто. В отличие от аппаратных, счетчики драйвера возвращают значения за последний построенный кадр.
При использовании интерфейса PDH, счетчики могут быть представлены в двух видах: числовом и процентном. Первые содержат численные значения (количество пикселей, треугольников, миллисекунд), накопленные со времени прошлого опроса, а процентные возвращают долю времени, которое определенный блок GPU был занят работой или ожиданием данных от другого блока. Если вызывать значения счетчиков из программы при помощи функций NVPerfAPI, то они возвращают числовые значения и общее количество отработанных циклов GPU. Для счетчиков количества треугольников и вершин возвращается число обработанных элементов.
Некоторые из программных счетчиков производительности, существующих отдельно для Direct3D и OpenGL приложений: частота кадров в секунду (FPS), количество вызовов отрисовки, число вершин и треугольников на кадр (с учетом и без учета instancing), занятый объем видеопамяти (текстурами, вершинами, буферами и т.п.), несколько специальных счетчиков для режима SLI, показывающих количество и объем передач данных от чипа к чипу, число переданных буферов рендеринга и другое.
Аппаратные счетчики интереснее: общее время простоя видеочипа, процент использования шейдерных блоков, доля простоя блоков ROP, время ожидания выборки текстур блоком пиксельных шейдеров, время ожидания операций записи во фреймбуфер, количество обработанных вершин, примитивов, треугольников и пикселей и т.п. Рассмотрим счетчики GPU подробнее, их количество в PerfKit 5 возросло, исследовать поведение 3D-приложений теперь станет проще.
- gpu_idle и gpu_busy — соответственно, доля времени простоя и занятости видеочипа с момента прошлого считывания значения. Эта пара счетчиков показывает, насколько был загружен работой (и наоборот) видеочип, такие данные полезны при балансировке нагрузки на видеочип, они помогают определить, ограничено ли приложение производительностью CPU или GPU.
- shader_busy — время занятости универсальных шейдерных блоков обработкой соответствующих программ. Значение показывает процент загруженности шейдерных блоков в целом (вершинными, геометрическими и пиксельными шейдерами совместно) и полезен для определения того, нет ли упора в производительность универсальных блоков.
- vertex_shader_busy — доля рабочего времени блоков вершинных шейдеров (или блоков универсальных шейдеров, занятых обработкой вершинных шейдеров, в зависимости от видеочипа). На старых (не унифицированных) архитектурах этот счетчик полезен для нахождения баланса между количеством и сложностью обработки вершин и нагрузкой на блоки пиксельных шейдеров. А на унифицированных помогает понять, насколько сложны вершинные шейдеры.
- pixel_shader_busy — доля которое блоки обработки пиксельных (или универсальных) шейдеров были заняты пиксельной работой. Тут все, как и в случае с предыдущим пунктом, на старых архитектурах значение может использоваться для определения того, ограничена ли производительность приложения скоростью блоков пиксельных шейдеров, а на новых — для оценки сложности попиксельной обработки.
- geometry_shader_busy — доля занятости универсальных шейдерных блоков обработкой геометрических шейдеров. Тут нет двойственности, геометрические шейдеры есть только на унифицированных архитектурах. Значения счетчика помогут определить, нет ли упора в производительность обработки геометрических шейдеров.
- rop_busy — доля времени в процентах, когда блок ROP был занят работой. Большие значения счетчика обычно получаются при активном использовании трехмерным приложением альфа-блендинга или при большом значении overdraw, что служит еще одним весьма распространенным ограничителем производительности рендеринга. На значения сильно влияет и включенный мультисэмплинг, увеличивающий нагрузку на блок ROP, а также использование буферов «тяжелых» форматов типа FP16, FP32 и др.
- geom_busy — процент времени работы блока по обработке геометрических данных. Помогает определить, не ограничивается ли общая производительность слишком большим количеством геометрии. Впрочем, в реальных приложениях такое наблюдается крайне редко…
- texture_busy — доля занятости блока текстурных выборок соответствующей работой. Показывает, насколько сильно загружены TMU и TFU, блоки текстурной выборки и фильтрации. Данный счетчик важен для определения того, не слишком ли много текстурных выборок использует 3D приложение, и не ограничивает ли это общую скорость рендеринга.
- stream_out_busy — время занятости работой интерфейса stream output, идущего после геометрического шейдера. Данная возможность появилась в Direct3D 10, «вывод потока» помогает вернуть в память данные, прошедшие обработку в вершинной части конвейера, для дальнейшего использования. В определенных условиях трехмерное приложение может быть ограничено производительностью этого блока, счетчик будет полезен для определения таких моментов.
- shaded_pixel_count — число пикселей, посланных растеризатором на обработку в блоки пиксельных шейдеров. Совместно с числом обработанных треугольников, значение может использоваться при поиске оптимального соотношения реальной геометрии и её имитации при помощи наложения карт нормалей.
- rasterizer_pixels_killed_zcull_count — количество отброшенных растеризатором пикселей при ZCull. Счетчик полезен для проверки эффективности работы отсечения ZCull, например.
- input_assembler_busy — доля занятости работой блока input assembler. Этот блок выбирает геометрические и другие данные из памяти для использования другими блоками GPU и при его слишком большой загрузке общая скорость рендеринга может быть ограничена.
- setup_point_count/setup_line_count/setup_triangle_count/setup_primitive_count — количество точек/линий/треугольников/примитивов, поступивших на обработку в видеочип. Например, может использоваться для определения эффективности форматов хранения треугольников, таких как strips и fa ns, и для определения геометрической сложности сцены.
- geom_primitive_in_count/geom_primitive_out_count — количество входных и выходных примитивов (точки, линии и треугольники), поступивших и вышедших трансформированными из блока обработки геометрии. Также может использоваться для определения эффективности форматов хранения треугольников и в информационных целях.
- geom_vertex_in_count/geom_vertex_out_count — количество входных и выходных вершин, аналогично предыдущему пункту.
- shader_waits_for_texture — время ожидания выборки значений из текстур универсальными блоками шейдеров. Простои шейдерных блоков из-за ожидания текстурных выборок часто встречаются при отсутствии мип-уровней у текстур и при высоких уровнях анизотропной фильтрации.
- shader_waits_for_rop — время ожидания окончания операций блендинга и записи в буфер кадра (ROP) универсальными шейдерными блоками. Слишком большие значения наблюдаются в случаях частого использования альфа-блендинга, высоких уровней антиалиасинга и большого overdraw.
- shader_waits_for_geom — время ожидания работы блока обработки геометрии универсальными шейдерными блоками. Наши исследования показывают, что в реальных условиях крайне маловероятно, что упор производительности будет в обработку геометрии, но проверить никогда не помешает.
- input_assembler_waits_for_fb — время простоя input assembler из-за ожидания блока по работе с фреймбуфером. Чаще бывает, когда производительность ограничена работой с фреймбуфером, чем блоком выборки данных, поэтому значение счетчика чаще бывает большое.
- rop_waits_for_shader — время простоя блока ROP из-за работы универсальных шейдерных блоков. В реальности такое нечасто случается, но всё же счетчик может быть полезным.
- rop_waits_for_fb — время ожидания блоком ROP окончания работы блока фреймбуфера. То же самое, что и предыдущее, весьма редко на практике.
- texture_waits_for_fb — время ожидания блоком текстурных выборок работы блока фреймбуфера, показывающий время простоя TMU/TFU из-за загруженности блока фреймбуфера.
- texture_waits_for_shader — время ожидания блоком текстурных выборок работы универсальных шейдерных блоков. Обратный одному из вышеприведенных счетчиков, он показывает, когда простаивают текстурные блоки.
Использование счетчиков производительности из приложений
Есть два возможных пути для доступа к данным программных и аппаратных счетчиков Nvidia из пользовательских приложений. Для этого можно использовать интерфейсы NVPerfAPI и Performance Data Helper (PDH). PDH — это общий интерфейс доступа к счетчикам производительности, предложенный компанией Microsoft в своих операционных системах, он используется программой PerfMon и некоторыми другими утилитами.
Например, существует проект утилиты с открытым исходным кодом, предназначенный для доступа к счетчикам PDH — PerfGraph. К сожалению, особого развития он не получил, но последняя версия вполне применима на практике, она поддерживает сбор данных от программных и аппаратных счетчиков, а также другой системной информации, хотя и не позволяет сохранять данные для дальнейшего анализа. Проект кроссплатформенный, существуют версии утилиты для Windows и Linux. Применение NVPerfAPI
NVPerfAPI — специальный программный интерфейс, предоставляющий разработчикам 3D-приложений доступ к данным счетчиков производительности и «упрощенным экспериментам» (simplified experiments), дающих более подробную информацию о нюансах производительности GPU. В комплекте PerfKit поставляются соответствующие библиотеки NVPerfAPI и примеры их использования, в пользовательских приложениях для этого нужно добавить несколько строк кода. Кстати, в отличие от программных счетчиков, количество считываний с которых не ограничено, существуют ограничения по количеству аппаратных счетчиков, которые можно считывать единовременно.Simplified Experiments (SimExp)
Одной из полезнейших возможностей PerfKit является поддержка запуска экспериментов на отдельных блоках видеочипа и сбор информации о производительности. Эти эксперименты называются «упрощенные опыты» или «упрощенные эксперименты» (simplified experiments). SimExp показывает значения, названные «Speed of Light» (SOL) и «Bottleneck» для нескольких участков графического конвейера. Первая цифра содержит время использования определенного блока GPU, возвращаемое значение «value» показывает, сколько циклов блок был занят работой во время проведения опыта, а значение «cycles» возвращает общее количество циклов, потраченное на проведение эксперимента. Похоже работает и «Bottleneck», значение «value» показывает время, когда блок служил ограничивающим (bottleneck) фактором для всего конвейера, а значение «cycles» — общую продолжительность опыта. Использование возможностей PerfSDK при помощи Performance Data Helper
Чтобы начать сбор данных при помощи Performance Data Helper, нужно указать драйверу и системе PDH, значения каких счетчиков им нужно собирать. Это делается в панели управления разработчика Nvidia (Nvidia Developer Control Panel), запускаемой из стандартной панели управления (Control Panel) Windows. В Developer Control Panel нужно выбрать сигналы, значения которых нужно снимать во время работы 3D-приложений.

Добавленные счетчики должны быть в списке активных («Active Counters»). упоминалось, что видеочип может собирать данные с ограниченного количества аппаратных счетчиков, и это число разное для каждой модели GPU. Единовременное количество программных счетчиков не ограничено, но включение каждого из них снижает производительность, поэтому лучшим решением будет включение только тех из них, которые действительно нужны в определенный момент. При запуске приложения в оконном режиме, есть возможность изменять набор используемых счетчиков в реальном времени, что позволяет использовать только нужный набор. Кстати, общее число счетчиков и некоторую системную информацию можно получить прямо из панели разработчика:
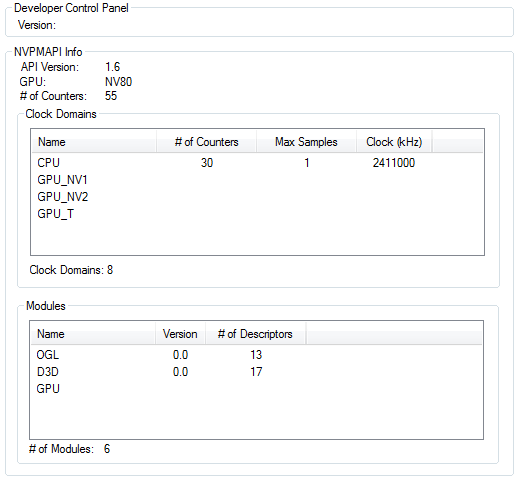
Использование стандартной системной утилиты PerfMon является одной из простейших возможностей по сбору информации со счетчиков производительности. Эта утилита строит несложные графики, основанные на информации счетчиков Nvidia, если их включить в панели управления разработчика Nvidia и добавить к графику PerfMon. Для этого нужно выбрать объект «Nvidia GPU Performance» для добавления аппаратных счетчиков, и «Nvidia Direct3D Driver» или «Nvidia OpenGL Driver» для программных. Получаемый в итоге график выглядит примерно так:
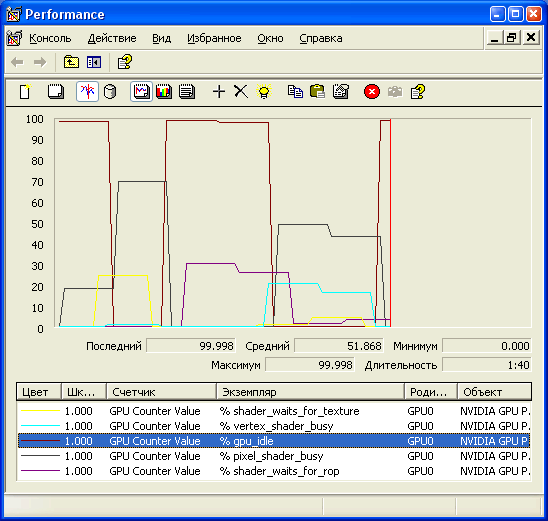
Особенно удобным такое использование не назовешь, лучше применять сторонние утилиты, позволяющие делать удобный анализ данных и сохранять их, или воспользоваться плагином для PIX. Плагин Nvidia для Microsoft PIX for Windows
В составе PerfKit поставляется плагин для импорта значений счетчиков производительности Nvidia в утилиту Microsoft PIX for Windows. Плагин для PIX позволяет собирать данные с программных и аппаратных счетчиков Nvidia в дополнение к возможностям мониторинга PIX, для более качественного анализа производительности и профилирования. Инсталлятор PerfKit при установке приложения автоматически записывает плагин в соответствующий каталог DirectX SDK, где расположена утилита. Для использования этих возможностей нужно не забывать об обязательном применении инструментального драйвера и о необходимых настройках в панели управления разработчика Nvidia.
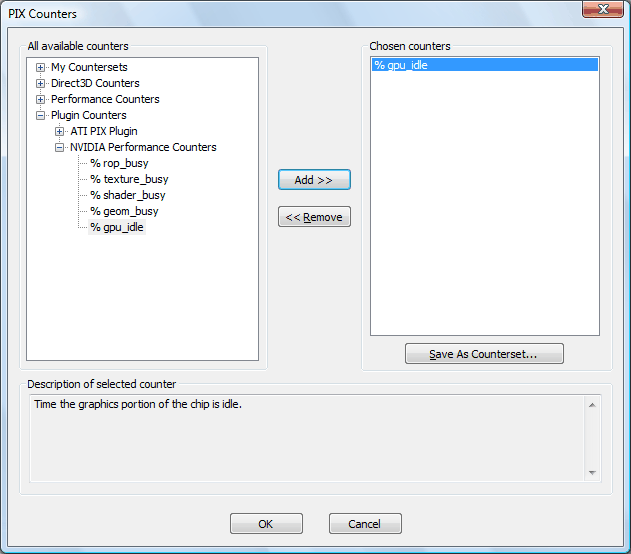
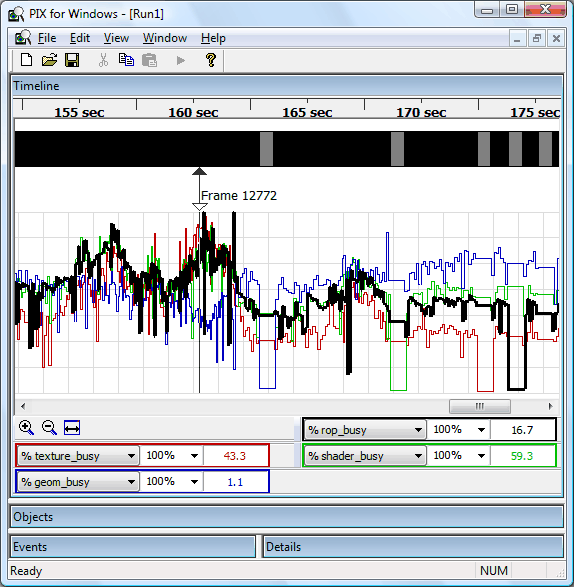
Чтобы настроить сбор информации со счетчиков в PIX, необходимо выбрать нужные счетчики в панели управления разработчика Nvidia, затем добавив их в настройках PIX. Для этого в окне эксперимента PIX нужно выбрать «More Options», выбрать вид действия «Set Per-Frame Counters» и нажать кнопку «Customize». Затем необходимо выбрать нужные счетчики из списка Plugin Counters — Nvidia Performance Counters в диалоге «PIX Counters». После этого действия значения счетчиков будут сниматься утилитой PIX в дополнение к ее собственным возможностям. Причем, если возможности PIX по построению графиков и их анализу недостаточны, все данные можно экспортировать в CSV формат и анализировать их другим программным обеспечением.
Усовершенствованная утилита PerfHUD 5.0
PerfHUD — это удобная утилита для профилирования и отладки Direct3D приложений, помогающая решить сложные проблемы со скоростью и качеством рендеринга при помощи подробного мониторинга производительности, инспекторов состояния графического конвейера и отладочной информации, которая выводится на информационную панель heads-up display (HUD). То есть, интерфейс PerfHUD рисуется прямо поверх изображения, построенного приложением, он содержит графики, текстовые поля и элементы управления.
Программа собирает данные от приложения, драйвера, API и видеочипа. После запуска она работает вместе с приложением и отображает собранную и информацию на экране вместе с картинкой приложения. PerfHUD использует специальный код в драйвере, собирающий данные со счетчиков видеочипа, а также перехватывающий вызовы API для сбора статистики и интеграции с приложением. Поэтому, по сравнению с обычным режимом, без специального драйвера и включенного HUD, наблюдается небольшое падение производительности, впрочем, ничуть не мешающее работе.
Главной отличительной особенностью утилиты является то, что она позволяет увидеть процесс построения кадра «на лету», вызов за вызовом, при этом можно исследовать (начиная с текущей версии утилиты уже и изменять!) шейдеры, геометрические данные, текстуры и т.п. Другие утилиты для похожих целей, такие как PIX, например, также позволяют прослеживать работу всех вызовов Direct3D API, но делают это не в реальном времени, а по запросу пользователя. Получается, что PerfHUD удобнее в работе, хотя даёт чуть меньше возможностей, чем PIX. В целом, можно сказать, что PIX лучше подходит для отлова ошибок, а PerfHUD — для обнаружения и устранения «узких» мест в производительности. Хотя прямо сравнивать PIX и PerfHUD нельзя, тот же PerfKit облегчает работу в PIX, давая возможность использования низкоуровневых счетчиков GPU, данные которых весьма важны при отладке.
PerfHUD 5 — это уже пятая версия утилиты для анализа производительности компании Nvidia, одна из главных частей набора PerfKit. Как и предыдущая версия, PerfHUD 5 позволяет проводить анализ построения кадра 3D приложениями отдельно по вызовам функций отрисовки, а также предоставляет несколько так называемых «экспериментов», и всё это — в режиме реального времени. Одним нажатием клавиши можно получить список вызовов функций отрисовки, сгруппированный по затраченному времени. Сбор данных о работе отдельных блоков чипа обычно непрост, тем более, что современные игры строят кадр за несколько тысяч вызовов функций отрисовки. PerfHUD позволяет разбить сцену и исследовать каждый вызов по отдельности, а также упрощает задачу, показывая ошибки и узкие в производительности места, чтобы разработчик смог их быстро исправить.
В PerfHUD 5 сделано множество улучшений по сравнению с предыдущей версией утилиты, это касается и функциональности и пользовательского интерфейса. Основные нововведения версии: полная поддержка семейства чипов Nvidia G8x, Direct3D 10 API и операционной системы Microsoft Windows Vista, а также большее количество возможностей и счетчиков, новый настраиваемый пользовательский интерфейс, возможность редактирования шейдеров и многое другое.
Вот подробный список изменений в Nvidia PerfHUD 5:
- поддержка архитектуры Nvidia G8x в Windows Vista и Windows XP
- поддержка DirectX 10 приложений в Windows Vista
- поддержка DirectX 9 приложений в Windows XP и Windows Vista
- режим «Edit & Continue» (возможность изменения «на лету») для HLSL и *.fx вершинных, геометрических и пиксельных шейдеров
- режим «Edit & Continue» (возможность изменения «на лету») для растровых операций
- настраиваемый интерфейс с возможностью выбора до четырех счетчиков на график, полным набором Direct3D и GPU счетчиков из PerfSDK, управлением размером и положением каждого графика, возможностью сохранения пользовательского интерфейса в файл
- улучшенный режим покадровой отладки «Frame Debugger» с визуализацией 1D, 2D и 3D текстур, карт теней и кубических карт, массивов текстур, возможностью показа результата лишь одного вызова отрисовки (draw call)
- улучшенный режим анализа производительности «Frame Profiler» с графиками «Instruction Count Ratio», всплывающими подсказками для графиков, поддержкой иерархических «Performance Markers»
- улучшенный пользовательский интерфейс, поддержка аппаратного курсора мыши, получение информации о аппаратной и программной конфигурации
- разнообразные улучшения, направленные на повышение совместимости и стабильности, исправления мелких ошибок
Помимо поддержки G8x и Direct3D 10, наиболее интересной новой возможностью, на наш взгляд, является редактирование шейдеров и состояний рендера (render state) в реальном времени. Утилита позволяет «на лету» делать изменения в коде шейдеров и сразу же видеть итоговый результат, что значительно облегчает опробование новых идей разработчиками и оптимизацию шейдерного кода.
Так как PerfHUD является мощнейшим инструментом по анализу 3D приложений, в Nvidia сделали защиту для того, чтобы исключить доступ третьих лиц к анализу пользовательских приложений без разрешения разработчика. Чтобы воспользоваться PerfHUD, нужно, чтобы в приложение была встроена соответствующая поддержка в виде нескольких строк кода в подпрограмме инициализации DirectX. Когда приложение запущено из-под PerfHUD, драйвером создается специальный видеоадаптер и пользовательское приложение должно его использовать, иначе PerfHUD не сработает. В дополнение к этому, сделано так, чтобы PerfHUD работал только при использовании референсного растеризатора, хотя при выборе рабочего видеоадаптера Nvidia PerfHUD приложение всё равно будет использовать аппаратные возможности видеочипа.
Такое решение применяется давно, начиная с версий PerfHUD 2.x, поэтому разработчики смогут использовать новую версию без изменений в своих программах. Приложения, в которых не включена поддержка PerfHUD описанным в документации образом, не могут быть исследованы при помощи этой утилиты. Причем, начиная с пятой версии PerfHUD, условия ещё больше ужесточились, если раньше показывался интерфейс и некоторые данные (FPS и количество треугольников в сцене) показывались на экране, то теперь никакие данные PerfHUD недоступны вообще:

Чтобы запустить Direct3D приложение совместно с PerfHUD, нужно задать путь к исполнимому файлу в командной строке утилиты или перетащить приложение или ссылку на него на ярлык PerfHUD. Интерфейс программы использует горячие клавиши для быстрого доступа к функциям, также есть элементы управления, которыми можно управлять мышью. Активность интерфейса переключается между пользовательским приложением и утилитой PerfHUD при помощи горячей клавиши, задаваемой в настройках утилиты. При первом запуске программы показывается конфигурационное окно, где можно задать основные настройки.
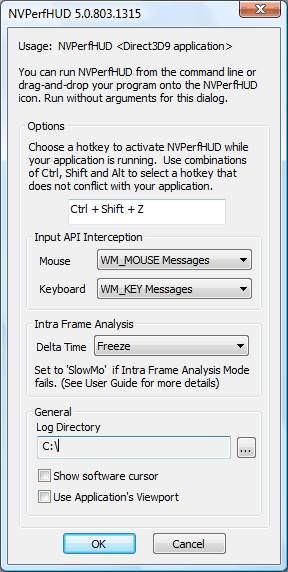
В настройках выбирается горячая клавиша для вызова PerfHUD, указывается место на жестком диске для хранения лог-файлов, выбирается способ перехвата сигналов мыши и клавиатуры (используя DirectInput или стандартные системные методы), и изменяется настройка для режимов Frame Debugger и Frame Profiler. В последней версии к этому добавилась возможность форсирования программного курсора мыши, ведь по умолчанию используется аппаратный, который улучшает управление при низкой частоте кадров, но может вызвать проблемы в редких случаях. Позднее, конфигурационное окно можно вызвать, запустив программу без указания имени приложения для анализа.
Режимы PerfHUD:
- Performance Dashboard — общий анализ производительности и поиск «узких» мест при помощи графиков и диаграмм со статистикой использования различных ресурсов видеокарты.
- Debug Console — просмотр отладочных сообщений библиотек DirectX, предупреждений PerfHUD и сообщений вашего приложения.
- Frame Debugger — подробное исследование работы этапов графического конвейера при помощи «заморозки» текущего кадра и анализа построения сцены по отдельным вызовам.
- Frame Profiler — режим отладки, в нем автоматически определяются и показываются наиболее требовательные вызовы функции отрисовки, он позволяет определить проблемные места с точки зрения производительности, а также то, насколько полно приложение использует возможности видеочипа.
Приведем пример работы с программой. При старте Direct3D приложения под PerfHUD запускается начальный режим интерфейса — Performance Dashboard, изображение которого накладывается поверх результата рендеринга запущенной из-под PerfHUD программы. Этот режим удобен для начальных исследований, он дает общие данные о работе графического конвейера в пользовательском приложении. Затем нужно вывести на экран сцену, которую хотелось бы исследовать подробнее. Если в ней наблюдаются ошибки рендеринга, их причины проще всего обнаружить в режиме Frame Debugger, где можно просмотреть построение сцены вызов за вызовом и для каждого вызова отрисовки увидеть используемую геометрическую модель, текстуры, шейдеры и растровые операции. Ну а в решении проблем производительности поможет режим Frame Profiler. В нем есть возможность продвинутого профилирования, помогающего найти проблемные участки с точки зрения производительности рендеринга. Frame Profiler выдает много полезной статистики в виде результатов автоматического анализа с полной информацией обо всех вызовах отрисовки и о времени, затраченном в них на работу различных блоков видеочипа. Рассмотрим все представленные режимы подробнее. Панель производительности Performance Dashboard
Это наиболее общий режим, знакомый нам с самых первых версий утилиты и позволяющий проводить детальный мониторинг и анализ общей производительности приложения. Здесь показывается статистика 3D приложения и использования ресурсов видеочипа и видеокарты в реальном времени.

В этом режиме PerfHUD'ом отображаются основные графики производительности. Прокручивающийся график в верхнем правом углу показывает загрузку универсальных вычислительных блоков видеочипа различными типами шейдеров: геометрическими, вершинными и пиксельными. В случае неунифицированных архитектур он показывает загрузку каждого типа шейдерных блоков. Этот график может использоваться для балансировки нагрузки между разными типами шейдерных программ. Левее него показан ещё один график загрузки блоков GPU, красным (по умолчанию) цветом выделен блок установки вершин, зеленым — загрузка блоков выполнения шейдеров, а синим — загрузка TMU. К графику можно добавлять и загрузку других блоков, например, блоков ROP. По этим графикам можно легко определить ограничивающие производительность участки графического конвейера.
Основной график этого режима PerfHUD, расположенный снизу посередине, содержит четыре линейных графика, показывающих общее время рендеринга кадра, время проведенное в драйвере, время простоя GPU и время ожидания. График расположен в нижней части экрана, выше него находится график Draw Primitives, показывающий число вызовов функций отрисовки DrawPrimitive, DrawPrimitiveUP и DrawIndexedPrimitive в процессе рендеринга кадра. Над последним расположен индикатор создания ресурсов, мигающий при динамическом создании различных Direct3D ресурсов: разных типов текстур, шейдеров, вершинных и индексных буферов и т.п. Этот индикатор полезен потому, что динамическое создание ресурсов в Direct3D приложениях негативно влияет на производительность. Другие элементы интерфейса в данном режиме: информационная полоса в верхней части экрана, и несколько графиков снизу.
Графики показывают количество вызовов DrawPrimitive и средний размер батча, а также использование видеопамяти, выделенной под экранные буферы, внеэкранные буферы (render targets) и текстуры. Вместо совмещенного графика Batch Size и Draw Primitives можно включить гистограмму, показывающую количество батчей в зависимости от объема используемой геометрии. В первом столбце графика расположена полоска, представляющая число батчей с количеством треугольников менее 100, во второй — с 100-200 треугольниками, и т.д.
Ещё один элемент интерфейса в данном режиме — информационная полоса в верхней части экрана, которая показывает текущее количество кадров в секунду (средний FPS за 20 последних кадров), количество треугольников в кадре, текущую скорость, а также подсказки о включенных режимах рендеринга: wireframe, текстуры размером 2х2 пикселя и др.
Эти режимы — ещё одна интересная возможность в режиме Performance Dashboard, эксперименты по определению «узких» мест графического конвейера при помощи их отключения. Эта работа требует отдельного анализа каждой стадии конвейера, и на новых видеочипах, начиная с Geforce 6, есть соответствующие аппаратные счетчики, показывающие загрузку каждого блока. Но можно воспользоваться методом отключения отдельных частей графического конвейера, что может дать похожий эффект. Например, можно форсировать применение специальной текстуры размером 2х2 пикселя вместо всех текстур, для значительного снижения влияния текстурирования на общую производительность. Эта возможность может применяться для определения того, является ли текстурирование основным ограничивающим фактором. Аналогично и с другими частями конвейера, есть возможность уменьшения влияния блоков ROP и пиксельных шейдеров, а также возможность отключения всех ступеней конвейера (игнорирование вызовов DrawPrimitive и DrawIndexedPrimitive), для определения того, не ограничена ли производительность 3D конвейера кодом пользовательского приложения.
Некоторые из имеющихся возможностей вызываются при помощи горячих клавиш. Например, есть возможность выборочного отключения пиксельных шейдеров разных версий. Можно включить визуализацию рендеринга каждой версии отдельно, вплоть до 4.0, при этом результат расчетов заменяется определенным цветом для каждой версии шейдеров. Подобным же образом можно включить каркасный режим (wireframe) и режим визуализации уровня перекрытия (overdraw).
Поговорим о нововведениях последней версии PerfHUD. Информационная панель утилиты была основательно переработана, разработчики сделали удобный и полностью настраиваемый пользовательский интерфейс, используя который можно сделать свой собственный набор необходимых графиков нужного размера. Для выбора доступен полный набор из нескольких десятков Direct3D и GPU счетчиков из PerfSDK, для каждого графика можно выбрать до четырех счетчиков:

Что важно, есть возможность нанесения собственных идентификационных надписей (впрочем, на нашей локализованный версии Windows XP не работающая), а также свободные размещение и выбор размера для графиков.

Потянув мышью за зелёный квадрат снизу-справа, можно изменять размер графика так же удобно, как это делается с размерами окон в операционных системах. Красный квадрат означает закрытие приложения, а синий вызывает конфигурационное меню графика (см. выше). Графики можно создавать в произвольном количестве, а также удалять их с экрана. Для максимального удобства сделаны сохранение и загрузка пользовательского интерфейса, для чего используется контекстное меню, облегчающее задачи конфигурации интерфейса под себя:

Есть возможность блокировки графиков, чтобы случайно не изменить их размеры и положение, а также восстановление вида интерфейса по умолчанию. Ну а из функциональных нововведений можно отметить появление новых «экспериментов»: минимизация геометрической обработки, подсветка результата работы пиксельных шейдеров версии 4.0 и других. Отладочная информация Debug Console
Отладочная консоль — это наиболее простой режим PerfHUD. В Debug Console можно просмотреть список диагностических сообщений об ошибках и предупреждениях отладочных библиотек DirectX, список событий создания ресурсов, а также дополнительные предупреждения самого PerfHUD и сообщения пользовательского приложения, выводимые при помощи функции OutputDebugString.

В данном режиме есть возможность очистки содержимого окна после каждого следующего кадра, чтобы видеть только относящиеся к текущему кадру сообщения. Это может быть полезно в случае большого числа ошибок и предупреждений. Также можно вообще отключить сбор данных при помощи опции «Stop Logging». Никаких особенных нововведений в PerfHUD 5 тут не появилось, да они и не нужны, режим выполняет свои задачи на 100%. Режим покадровой отладки Frame Debugger
Режим анализа построения кадра «Frame Debugger» — это один из наиболее впечатляющих режимов PerfHUD, в нём рендеринг приостанавливается на текущем кадре и становится возможным просмотр его построения шаг за шагом, отдельно по каждому вызову DrawPrimitive. Это помогает быстро найти проблемы, связанные с неправильным порядком отрисовки объектов, в этом режиме легко определить, из-за чего возникают ошибки рендеринга в процессе построения кадра. Используя полосу прокрутки внизу экрана, можно пошагово пройти весь кадр, что особенно полезно в случае сложных сцен с большим количеством вызовов функции отрисовки и несколькими буферами рендеринга.

После того, как в основном режиме Performance Dashboard обнаружен кадр с артефактами рендеринга, нужно переключиться в режим Frame Debugger, и, просматривая по одному вызову отрисовки, проверить порядок и правильность отрисовки сцены. Так как режим «замораживает» пользовательское приложение, существуют определенные ограничения по его использованию. Так, режим Frame Debugger будет корректно работать, только если приложение использует стандартные системные вызовы QueryPerformanceCounter или timeGetTime, также есть и некоторые другие ограничения, о которых подробно написано в документации PerfKit.
При первом запуске режима на экране показываются результаты первого вызова отрисовки. Пользуясь полосой прокрутки внизу экрана или клавиатурными стрелками «влево» и «вправо», можно просматривать результаты каждого последующего вызова функции draw call. Геометрические данные, используемые в текущей функции отрисовки, подсвечиваются оранжевой wireframe сеткой, применяемые текстуры показываются в поле слева, а буферы справа. Информация, отображаемая для текстур и внеэкранных буферов рендеринга включает в себя изображение текстуры и ее параметры (вид текстуры: 1D, 2D, 3D, кубическая, разрешение, метод фильтрации, формат текстуры, количество мип-уровней). Если вызов отрисовки при рендеринге использует внеэкранную поверхность, то его содержимое показывается в центре экрана. При включенном показе предупреждений, их список показывается в верхней части экрана, при нажатии на любом из них вызывается соответствующий DrawPrimitive вызов.
Нажатием на кнопку «Advanced» можно перейти в «продвинутый» режим, который предлагает подробный анализ каждого вызова отрисовки при помощи так называемых инспекторов состояния (state inspectors). В advanced режиме всё так же доступна полоса прокрутки внизу экрана, а остальная его часть делится на пять частей — по количеству стадий в графическом конвейере: выборка вершин (Vertex Assembly), вершинный шейдер (Vertex Shader), геометрический шейдер (Geometry Shader), пиксельный шейдер (Pixel Shader), растровые операции с буферами (Raster Operations). Соответствующие инспекторы позволяют просматривать геометрические модели, используемые шейдеры всех типов, а также операции растеризации для выбранного вызова отрисовки.

Когда выбран инспектор состояния Vertex Assembly, PerfHUD отображает на экране информацию о состоянии блока выборки вершин в текущем вызове отрисовки. В центре экрана в каркасном режиме показывается геометрия, используемая в данном вызове, а сбоку расположено поле с параметрами вызова отрисовки, форматами индексного и вершинного буферов, их размерами и т.п. В этом режиме можно убедиться, что все геометрические данные посылаются корректно.
В режимах Vertex Shader State Inspector, Geometry Shader State Inspector и Pixel Shader State Inspector окно отображает информацию об используемом в вызове отрисовки коде шейдера, соответственно. Показывается сама вершинная/геометрическая/пиксельная программа и используемые в ней константы и текстуры. Окно режима растровых операций (Raster Operations) выводит информацию об операциях, производимых блоком ROP в текущем вызове draw call. Показывается формат буфера кадра, состояние рендера (render state) и т.п. Этот инспектор полезен для проверки правильности работы альфа-блендинга. Например, можно посмотреть, содержит ли необходимые данные буфер, если блендинг не работает корректно.
Новыми для режима Frame Debugger в PerfHUD 5 стали возможности вращения каркасной модели и показ лишь одного вызова draw call вместо суммы работы всех предыдущих. Полезной является визуализация большего количества типов текстур: 1D, 2D, 3D карт теней, кубических карт и текстурных массивов, ещё одной новинкой стало то, что при наведении курсора мыши на текстуры и render targets, показываются всплывающие сообщения с текстурными координатами и цветом текселя:

Но самым интересным нововведением является режим «Shader Edit-and-Continue», который позволяет отредактировать шейдеры и тут же исполнить их. Можно изменять программы в форматах HLSL и .fx для DirectX 9 и DirectX 10 программ, это относится ко всем типам шейдеров: вершинным, геометрическим и пиксельным. Редактирование их кода производится обычным образом — в специальных текстовых полях, в которых есть возможность поиска текста, равно как и переключение между оригинальным кодом и модифицированным, а также восстановление оригинальной программы. Это сильно облегчает процесс поиска ошибок и оптимизацию 3D приложения, не нужно выходить из приложения и запускать его вновь, изменив одну строчку шейдерного кода, теперь можно всё сразу делать наглядно.

Кстати, подобный же режим, позволяющий менять состояния рендера, называется «Render State Edit-and-Continue». Тут всё аналогично редактированию шейдеров, можно менять состояния рендера, переключаться между оригинальным набором и измененным.
Режим PerfHUD под названием Frame Profiler, появившийся впервые в предыдущей версии утилиты, призван помочь в оптимизации производительности 3D приложений. Frame Profiler использует аппаратные блоки видеочипа и инструментальный код драйвера для измерения загрузки отдельных блоков GPU пользовательским приложением, помогая найти узкие места графического конвейера. При вызове режима, PerfHUD выполняет несколько экспериментов по анализу производительности текущего кадра, выдавая детальный отчет по вызовам отрисовки.
Режим профилирования является эффективным методом нахождения проблемных мест в отдельных сценах, он показывает самые требовательные вызовы функции отрисовки в кадре, а также предоставляет подробную информацию о каждом вызове функции отрисовки, что позволяет определить те из них, которые требуют особого внимания. Суть работы режима в том, что текущий кадр рендерится несколько раз и в это время производится замер использования ресурсов видеочипа, отдельно по вызовам отрисовки. Исходя из этой информации, вызовы отрисовки группируются в так называемые блоки состояния (state buckets). Все вызовы в одном блоке имеют общие характеристики, поэтому устранение узкого места в одном из вызовов отрисовки вызовет увеличение производительности остальных вызовов этого блока.

В нижней части экрана по умолчанию отображается диаграмма использования блоков видеочипа. На этом графике верхняя полоска (бар) показывает весь кадр целиком, а бары, расположенные ниже, показывают степень загруженности отдельных блоков видеочипа (блок установки вершин, блок обработки геометрии, универсальный блок шейдеров, блок текстурирования, блок ROP и блок работы с буфером кадра) во время текущего вызова отрисовки и всех вызовов в блоке состояния state bucket. Желтая секция каждой полоски показывает общее время кадра в миллисекундах, красная — время использования блоков видеочипа всеми вызовами блока состояния, а оранжевая полоска показывает время использования блока в текущем вызове функции отрисовки.
График использования блоков чипа похож на тот, что показывается в режиме Performance Dashboard, но рассматриваемый график в режиме Frame Profiler основан на анализе единственного кадра и показывает использование блоков GPU отдельно для каждого вызова отрисовки. Также есть возможность просмотра графиков: продолжительности вызовов отрисовки, показывающего время в миллисекундах, которое занимает каждый вызов отрисовки в кадре; продолжительности использования блока depth/stencil удвоенной производительности, показывающего время активности данного блока в миллисекундах и счетчик количества обработанных пикселей в каждом вызове draw call.
Как и в предыдущем режиме, в Frame Profiler есть второй вид интерфейса — Advanced, для доступа к инспекторам состояния. Этот вид в Frame Profiler позволяет просматривать (а начиная с пятой версии PerfHUD и изменять) детали отдельных вызовов отрисовки (геометрические данные, применяемые пиксельные, геометрические и вершинные шейдеры, растровые операции) с одновременным просмотром времени, затрачиваемого на каждый вызов draw call в выбранном кадре. Режим сделан в том же стиле, что и Advanced во Frame Debugger, а цветная временная диаграмма схожа с тем, как сделаны бары в описанных выше графиках использования блоков видеочипа.

Улучшения PerfHUD 5 коснулись и режима Frame Profiler, появились графики «Instruction Count Ratio», показывающие соотношение количества инструкций в вершинных, геометрических и пиксельных шейдерах отдельно для всего кадра, блока состояния и отдельного вызова функции отрисовки (см. скриншот), появились всплывающие подсказки для графиков с цифровыми значениями, новый критерий «Alpha Enabled» для блоков состояния, а также поддержка иерархической структуры меток производительности Direct3D.
Мелкие недоработки
Бочка мёда, которую получили 3D разработчики с PerfKit 5, очевидна, набор инструментов сильно облегчает труд программистов, давая им удобное средство для анализа производительности и отлова ошибок, пришло время и для ложки дёгтя. Как и у любого нового продукта, у PerfKit 5 есть несколько мелких недоработок, которые, впрочем, оперативно исправляются в обновлениях набора утилит (поэтому удостоверьтесь в применении последней версии, посетив соответствующий сайт Nvidia). Так, некоторые пользователи сталкиваются с трудностями при установке, инструментальные драйверы не всегда желают корректно работать на всех системах, может выдаваться ошибка при завершении работы Direct3D приложения под PerfHUD. Ну а лично мы по какой-то странной причине так и не смогли воспользоваться интерфейсом PDH из Windows Vista, хотя в XP всё работает нормально.
Ещё одной небольшой проблемой является то, что снижение производительности от инструментального драйвера по сравнению с обычным в Windows Vista пока что может быть выше, чем в Windows XP. Но в Nvidia над этим работают и в будущем обещают исправить этот недостаток. Из сопутствующих недоделок, объяснимых новизной утилиты — отсутствие обновленной документации для PerfKit, на момент написания обзора была отредактирована только часть руководства пользователя (User Guide).
А ещё не совсем понятно, каким образом можно включать и выключать специальные возможности инструментальных драйверов. Эта возможность может пригодиться в реальности, так как использование специальных возможностей снижает производительность на несколько процентов. Панель Nvidia в трее под Windows XP не запускается, вылетая с ошибкой инициализации, а в панели «Nvidia Developer Control Panel» нет ничего похожего на возможность отключения «driver instrumentation». Это ещё одна недоработка, хотя и не мешающая основной задаче PerfKit, с которой набор великолепно справляется.
Выводы
Пакет PerfKit предлагает удобнейшие средства для поиска причин низкой производительности 3D приложений, их оптимизации, а также устранения ошибок рендеринга. Используя возможности, предлагаемые PerfKit, можно определить влияние каждого блока графического конвейера на общую производительность, а затем, уже зная все узкие места, устранить их.
Возможности обновленного PerfKit 5 позволяют значительно упростить поиск проблемных мест кода, программные и аппаратные счетчики производительности предоставляют полезную информацию о работе видеочипов Nvidia, с их помощью можно определить загрузку основных блоков GPU в разных сценах. Возможностей по использованию счетчиков несколько, можно использовать как NVPerfAPI из своего приложения и анализ в PerfMon и PIX. А если нужен более наглядный и удобный инструмент по анализу Direct3D приложений, можно воспользоваться PerfHUD, который предоставит полную информацию о работе приложения и видеочипа в удобной форме, прямо во время работы пользовательской программы.
Последняя версия PerfKit привнесла несколько новых возможностей, которых долго ждали 3D разработчики, среди них можно отметить: поддержку архитектуры видеочипов Nvidia G8x, полную поддержку Windows Vista и Direct3D 10 приложений, увеличенное количество экспериментов, аппаратных и программных счетчиков, удобный настраиваемый пользовательский интерфейс PerfHUD 5, возможность редактирования вершинных, геометрических и пиксельных шейдеров и растровых операций в реальном времени в PerfHUD 5 и многое другое. Не забыли и про повышение совместимости и стабильности, исправления мелких ошибок предыдущих версий. Конечно, не обошлось без появления новых, но они оперативно исправляются в частых обновлениях пакета.
Наиболее интересной новой возможностью, появившейся в PerfHUD, на наш взгляд, является редактирование шейдеров и состояний рендера в реальном времени. Утилита позволяет «на лету» делать изменения в коде шейдеров и сразу же видеть итоговый результат, что значительно облегчает разработчикам опробование новых и оптимизацию старых идей.
Итак, обновленный набор утилит PerfKit 5 будет весьма полезен для всех разработчиков современных трехмерных приложений, использующих в своей работе Direct3D или OpenGL. Он поможет в большинстве непростых вопросов, возникающих в процессе разработки: определении узких мест в производительности, нахождении ошибок рендеринга, наиболее полном использовании возможностей современных GPU, поиске баланса между нагрузкой на разные блоки видеочипов и многих других.
