Технология создания позиционируемого 3D звука
Звуковое сопровождение компьютера всегда находилось несколько на втором плане. Большинство пользователей более охотно потратят деньги на новейший акселератор 3D графики, нежели на новую звуковую карту. Однако за последний год производители звуковых чипов и разработчики технологий 3D звука приложили немало усилий, чтобы убедить пользователей и разработчиков приложений в том, что хороший 3D звук является неотъемлемой частью современного мультимедиа компьютера. Пользователей убедить в пользе 3D звука несколько легче, чем разработчиков приложений. Достаточно расписать пользователю то, как источники звука будут располагаться в пространстве вокруг него, т.е. звук будет окружать слушателя со всех сторон и динамично изменяться, как многие сразу потянутся за кошельком. С разработчиками игр и приложений сложнее. Их надо убедить потратить время и средства на реализацию качественного звука. А если звуковых интерфейсов несколько, то перед разработчиком игры встает проблема выбора. Сегодня есть два основных звуковых интерфейса, это DirectSound3D от Microsoft и A3D от Aureal. При этом, если разработчик приложения предпочтет A3D, то на всем аппаратном обеспечении DS3D будет воспроизводиться 3D позиционируемый звук, причем такой же, как если бы изначально использовался API DS3D. Само понятие "трехмерный звук" подразумевает, что источники звука располагаются в трехмерном пространстве вокруг слушателя. Это основа. Далее, чтобы придать звуковой модели реализм и усилить ощущения при восприятии звука слушателем, используются различные технологии, обеспечивающие воспроизведение реверберации, отраженных звуков, окклюзии (звук прошедший через препятствие), обструкции (звук не прошел через препятствие), дистанционное моделирование (вводится параметр удаленности источника звука от слушателя) и масса других интересных эффектов. Цель всего этого — создать у пользователя ощущение реальности звука и усилить впечатления от видеоряда в игре или приложении. Не секрет, что слух это второстепенное чувство человека, именно поэтому, каждый индивидуальный пользователь воспринимает звук по-своему. Никогда не будет однозначного мнения о звучании той или иной звуковой карты или эффективности той или иной технологии 3D звука. Сколько будет слушателей, столько будет мнений. В данной статье мы попытались собрать и обобщить информацию о принципах создания 3D звука, а также рассказать о текущем состоянии звуковой компьютерной индустрии и о перспективах развития. Мы уделим отдельное внимание необходимым составляющим хорошего восприятия и воспроизведения 3D звука, а также расскажем о некоторых перспективных разработках. Некоторые данные в статье рассчитаны на подготовленного пользователя, однако, никто не мешает пропустить нудные формулы тем, кому это не интересно или давно надоело в институте.
Итак, наверняка почти все слышали, что для позиционирования источников звука в виртуальном 3D пространстве используются HRTF функции. Ну что же, попробуем разобраться в том, что такое HRTF и действительно ли их использование так эффективно.
Сколько раз происходило следующее: команда разработчиков, отвечающая за звук, только что закончила встраивание 3D звукового движка на базе HRTF в новейшую игру; все комфортно расселись, готовясь услышать "звук окружающий вас со всех сторон" и "свист пуль над вашей головой"; запускается демо версия игры и… и ничего подобного вы просто не слышите!
HRTF (Head Related Transfer Function) это процесс, посредством которого наши два уха определяют слышимое местоположение источника звука; наши голова и туловище являются в некоторой степени препятствием, задерживающим и фильтрующим звук, поэтому ухо, скрытое от источника звука головой воспринимает измененные звуковые сигналы, которые при "декодировании" мозгом интерпретируются соответствующим образом для определения местоположения источника звука. Звук, улавливаемый нашим ухом, создает давление на барабанную перепонку. Для определения создаваемого звукового давления необходимо определить характеристику импульса сигнала от источника звука, попадающего на барабанную перепонку, т.е. силу, с которой звуковая волна от источника звука воздействует на барабанную перепонку. Эту зависимость называют Head Related Impulse Response (HRIR), а ее интегральное преобразование по Фурье называется HRTF.
Если вас интересует научное объяснение, то нет проблем, оно будет ниже. Если вас пугают формулы или вы их уже видеть не можете, просто пролистайте пару экранов вниз.
С точки зрения науки, правильнее характеризовать акустические источники скоростью распространения вещества в звуковой волне V(t), нежели давлением P(t), распространяемой звуковой волны. Теоретически, давление, создаваемой идеальным точечным источником звука бесконечно, но ускорение распространяемой звуковой волны есть величина конечная. Если вы достаточно удалены от источника звука и если вы находитесь в состоянии "free field" (т.е. в окружающей среде нет ничего кроме, источника звука и среды распространения звуковой волны), тогда давление "free field" (ff) на расстоянии "r" от источника звука определяется по формуле:
Pff(t) = Zo V(t — r/c) / r
где Zo это постоянная, называемая волновым сопротивлением среды (characteristic impedance of the medium),
а "c" это скорость распространения звука в среде. Итак, давление ff пропорционально скорости в начальный период
времени (происход "сдвиг" по времени, обусловленный конечной скоростью распространения сигнала, т.е. возмущение в
этой точке описывается скоростью источника в момент времени, отстоящий на r/c — время которое затрачено на то, чтобы
сигнал дошел до наблюдателя. В принципе не зная V(t) нельзя утверждать характера изменения скорости при сдвиге, т.е.
произойдет замедление или ускорение) и уменьшается обратно пропорционально расстоянию от источника звука до точки наблюдения.
С точки зрения частоты, давление звуковой волны можно выразить так:
Pff(f) = Zo V(f) exp(- i 2 pi r/c) / r
где "f" это частота в герцах (Hz), i = sqrt(-1), а V(f) получается в результате применения преобразования Фурье к
скорости распространения вещества в звуковой волне V(t). Таким образом, задержки при распространении звуковой волны
можно охарактеризовать параметром, называемым "phase factor", т.е. фазовым коэффициентом exp(- i 2 pi r / c). Или,
говоря словами, это означает, что функция преобразования в "free field" Pff(f) просто
является результатом произведения масштабирующего коэффициента Zo, фазового коэффициента
exp(- i 2 pi r /c) и обратно пропорциональна расстоянию 1/r. Заметим, что более рациональным будет
использовать традиционную циклическую частоту, равную 2*pi*f, нежели просто частоту.
Если поместить в среду распространения звуковых волн человека, тогда звуковое поле вокруг человека искажается за счет дифракции (рассеивания или иначе говоря наблюдается различие скоростей распространения волн разной длины), отражения и дисперсии (рассредоточения) при контакте человека со звуковыми волнами. Теперь все тот же источник звука будет создавать несколько другое давление звука P(t) на барабанную перепонку в ухе человека. С точки зрения частоты это давление обозначим как P(f). Теперь, P(f), как и Pff(f) также содержит фазовый коэффициент, чтобы учесть задержки при распространении звуковой волны, при этом давление вновь ослабевает обратно пропорционально расстоянию. Для исключения этих концептуально незначимых эффектов HRTF функция H определяется как соотношение P(f) и Pff(f). Итак, строго говоря, H это функция, определяющая коэффициент умножения для значение давления звука, присутствующее в центре головы слушателя, если нет никаких объектов на пути распространения волны, по отношению к величине давления на барабанную перепонку в ухе слушателя.
Обратным преобразованием Фурье функции H(f) является функция H(t), представляющая собой HRIR (Head-Related Impulse Response). Таким образом, строго говоря, HRIR это коэффициент (он же есть отношение давлений, т.е. безразмерен; это просто удобный способ загнать в одну букву в формуле очень сложный параметр), который определяет воздействие на барабанную перепонку, когда звуковой импульс испускается источником звука, за исключением того, что мы сдвинули временную ось так, что t=0 соответствует времени, когда звуковая волна в "free field" достигнет центра головы слушателя. Также мы масштабировали результаты таким образом, что они не зависят от того, как далеко источник звука расположен от человека, относительно которого производятся все измерения.
Если вы готовы пренебречь этим временным сдвигом и масштабированием расстояния до источника звука, вы можете просто сказать, что HRIR это давление, воздействующее на барабанную перепонку, когда источник звука является импульсным.
Напомним, что интегральным преобразованием Фурье функции HRIR является HRTF функция. Если известно значение HRTF для каждого уха, мы можем точно синтезировать бинауральные сигналы от монофонического источника звука (monaural sound source). Соответственно, для разного положения головы относительно источника звука задействуются разные HRTF фильтры. Библиотека HRTF фильтров создается в результате лабораторных измерений, производимых с использованием манекена, носящего название KEMAR (Knowles Electronics Manikin for Auditory Research, т.е. манекен Knowles Electronics для слуховых исследований) или с помощью специального "цифрового уха" (digital ear), разработанного в лаборатории Sensaura, располагаемого на голове манекена. Понятно, что измеряется именно HRIR, а значение HRTF получается путем преобразования Фурье. На голове манекена располагаются микрофоны, закрепленные в его ушах. Звуки воспроизводятся через акустические колонки, расположенные вокруг манекена и происходит запись того, что слышит каждое "ухо".
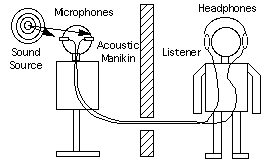
HRTF представляет собой необычайно сложную функцию с четырьмя переменными: три пространственных координаты и частота. При использовании сферических координат для определения расстояния до источников звука больших, чем один метр, считается, что источники звука находятся в дальнем поле (far field) и значение HRTF уменьшается обратно пропорционально расстоянию. Большинство измерений HRTF производится именно в дальнем поле, что существенным образом упрощает HRTF до функции азимута (azimuth), высоты (elevation) и частоты (frequency), т.е. происходит упрощение, за счет избавления от четвертой переменной. Затем при записи используются полученные значения измерений и в результате, при проигрывании звук (например, оркестра) воспроизводится с таким же пространственным расположением, как и при естественном прослушивании. Техника HRTF используется уже несколько десятков лет для обеспечения высокого качества стерео записей. Лучшие результаты получаются при прослушивании записей одним слушателем в наушниках.
Наушники, конечно, упрощают решение проблемы доставки одного звука к одному уху и другого звука к другому уху. Тем не менее, использование наушников имеет и недостатки. Например:
- Многие люди просто не любят использовать наушники. Даже легкие беспроводные наушники могут быть обременительны. Наушники, обеспечивающие наилучшую акустику, могут быть чрезвычайно неудобными при длительном прослушивании.
- Наушники могут иметь провалы и пики в своих частотных характеристиках, которые соответствуют характеристикам ушной раковины. Если такого соответствия нет, то восприятие звука, источник которого находится в вертикальной плоскости, может быть ухудшено. Иначе говоря, мы будем слышать преимущественно только звук, источники которого находится в горизонтальной плоскости.
- При прослушивании в наушниках, создается ощущение, что источник звука находится очень близко. И действительно, физический источник звука находится очень близко к уху, поэтому необходимая компенсация для избавления от акустических сигналов влияющих на определение местоположения физических источников звука зависит от расположения самих наушников.
Использование акустических колонок позволяет обойти большинство из этих проблем, но при этом не совсем понятно, как можно использовать колонки для воспроизведения бинаурального звука (т.е. звука, предназначенного для прослушивания в наушниках, когда часть сигнала предназначена для одного уха, а другая часть для другого уха). Как только мы подключим вместо наушников колонки, наше правое ухо начнет слышать не только звук, предназначенный для него, но и часть звука, предназначенную для левого уха. Одним из решений такой проблемы является использование техники cross-talk-cancelled stereo или transaural stereo, чаще называемой просто алгоритм crosstalk cancellation (для краткости CC).
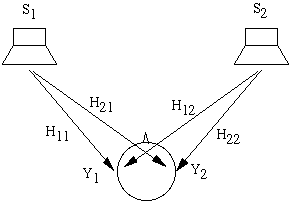
Идея CC просто выражается в терминах частот. На схемы выше сигналы S1 и S2 воспроизводятся колонками. Сигнал Y1 достигающий левого уха представляет собой смесь из S1 и "crosstalk" (части) сигнала S2. Чтобы быть более точными, Y1=H11 S1 + H12 S2, где H11 является HRTF между левой колонкой и левым ухом, а H12 это HRTF между правой колонкой и левым ухом. Аналогично Y2=H21 S1 + H22 S2. Если мы решим использовать наушники, то мы явно будем знать искомые сигналы Y1 и Y2 воспринимаемые ушами. Проблема в том, что необходимо правильно определить сигналы S1 и S2, чтобы получить искомый результат. Математически для этого просто надо обратить уравнение:

На практике, обратное преобразование матрицы не является тривиальной задачей.
- При очень низкой частоте звука, все функции HRTF одинаковы и поэтому матрица является вырожденной, т.е. матрицей с нулевым детерминантом (это единственная помеха для тривиального обращения любой квадратной матрицы). На западе такие матрицы называют сингулярными. (К счастью, в среде отражающей звук, т.е. где присутствует реверберация, низкочастотная информация не являются важной для определения местоположения источника звука).
- Точное решение стремиться к результату с очень длинными импульсными характеристиками. Эта проблема становится все более и более сложной, если в дальнейшем искомый источник звука располагается вне линии между двумя колонками, т.е. так называемый фантомный источник звука.
- Результат будет зависеть от того, где находится слушатель по отношению к колонкам. Правильное восприятие звучания достигается только в районе так называемого "sweet spot", предполагаемого месторасположения слушателя при обращении уравнения. Поэтому, то, как мы слышим звук, зависит не только от того, как была сделана запись, но и от того, из какого места между колонками мы слушаем звук.
При грамотном использовании алгоритмов CC получаются весьма хорошие результаты, обеспечивающие воспроизведение звука, источники которого расположены в вертикальной и горизонтальной плоскости. Фантомный источник звука может располагаться далеко вне пределов линейного сегмента между двумя колонками.
Давно известно, что для создания убедительного 3D звучания достаточно двух звуковых каналов. Главное это воссоздать давление звука на барабанные перепонки в левом и правом ушах таким же, как если бы слушатель находился в реальной звуковой среде.
Из-за того, что расчет HRTF функций сложная задача, во многих системах пространственного звука (spatial audio systems) разработчики полагаются на использование данных, полученных экспериментальным путем, например, данные получаются с помощью KEMAR, о чем мы писали выше. Тем не менее, основной причиной использования HRTF является желание воспроизвести эффект elevation (звук в вертикальной плоскости), наряду с азимутальными звуковыми эффектами. При этом восприятие звуковых сигналов, источники которых расположены в вертикальной плоскости, чрезвычайно чувствительно к особенностям каждого конкретного слушателя. В результате сложились четыре различных метода расчета HRTF:
- Использование компромиссных, стандартных HRTF функций. Такой метод обеспечивает посредственные результаты при воспроизведении эффектов elevation для некоторого процента слушателей, но это самый распространенный метод в недорогих системах. На сегодня, ни IEEE, ни ACM, ни AES не определили стандарт на HRTF, но похоже, что компании типа Microsoft и Intel создадут стандарт де-факто.
- Использование одного типа HRTF функций из набора стандартных функций. В этом случае необходимо определить HRTF для небольшого числа людей, которые представляют все различные типы слушателей, и предоставить пользователю простой способ выбрать именно тот набор HRTF функций, который наилучшим образом соответствует ему (имеются в виду рост, форма головы, расположение ушей и т.д.). Несмотря на то, что такой метод предложен, пока никаких стандартных наборов HRTF функций не существует.
- Использование индивидуализированных HRTF функций. В этом случае необходимо производить определение HRTF исходя из параметров конкретного слушателя, что само по себе сложная и требующая массы времени процедура. Тем не менее, эта процедура обеспечивает наилучшие результаты.
- Использование метода моделирования параметров определяющих HRTF, которые могут быть адаптированы к каждому конкретному слушателю. Именно этот метод сейчас применяется повсеместно в технологиях 3D звука.
На практике существуют некоторые проблемы, связанные с созданием базы HRTF функций при помощи манекена. Результат будет соответствовать ожиданиям, если манекен и слушатель имеют головы одинакового размера и формы, а также ушные раковины одинакового размера и формы. Только при этих условиях можно корректно воссоздать эффект звучания в вертикальной плоскости и гарантировать правильное определение местоположения источников звука в пространстве. Записи, сделанные с использованием HRTF называются binaural recordings, и они обеспечивают высококачественный 3D звук. Слушать такие записи надо в наушниках, причем желательно в специальных наушниках. Компакт диски с такими записями стоят существенно дороже стандартных музыкальных CD. Чтобы корректно воспроизводить такие записи через колонки необходимо дополнительно использовать технику CC. Но главный недостаток подобного метода — это отсутствие интерактивности. Без дополнительных механизмов, отслеживающих положение головы пользователя, обеспечить интерактивность при использовании HRTF нельзя. Бытует даже поговорка, что использовать HRTF для интерактивного 3D звука, это все равно, что использовать ложку вместо отвертки: инструмент не соответствует задаче.
Sweet Spot
На самом деле значения HRTF можно получить не только с помощью установленных в ушах манекена специальных внутриканальных микрофонов (inter-canal microphones). Используется еще и так называемая искусственная ушная раковина. В этом случае прослушивать записи нужно в специальных внутриканальных (inter-canal) наушниках, которые представляют собой маленькие шишечки, размещаемые в ушном канале, так как искусственная ушная раковина уже перевела всю информацию о позиционировании в волновую форму. Однако нам гораздо удобнее слушать звук в наушниках или через колонки. При этом стоит помнить о том, что при записи через inter-canal микрофоны вокруг них, над ними и под ними происходит искажение звука. Аналогично, при прослушивании звук искажается вокруг головы слушателя. Поэтому и появилось понятие sweet spot, т.е. области, при расположении внутри которой слушатель будет слышать все эффекты, которые он должен слышать. Соответственно, если голова слушателя расположена в таком же положении, как и голова манекена при записи (и на той же высоте), тогда будет получен лучший результат при прослушивании. Во всех остальных случаях будут возникать искажения звука, как между ушами, так и между колонками. Понятно, что необходимость выбора правильного положения при прослушивании, т.е. расположение слушателя в sweet spot, накладывает дополнительные ограничения и создает новые проблемы. Понятно, что чем больше область sweet spot, тем большую свободу действий имеет слушатель. Поэтому разработчики постоянно ищут способы увеличить область действия sweet spot.
Частотная характеристика
Действие HRTF зависит от частоты звука; только звуки со значениями частотных компонентов в пределах от 3 kHz до 10 kHz могут успешно интерпретироваться с помощью функций HRTF. Определение местоположения источников звуков с частотой ниже 1 kHz основывается на определении времени задержки прибытия разных по фазе сигналов до ушей, что дает возможность определить только общее расположение слева/справа источников звука и не помогает пространственному восприятию звучания. Восприятие звука с частотой выше 10 kHz почти полностью зависит от ушной раковины, поэтому далеко не каждый слушатель может различать звуки с такой частотой. Определить местоположение источников звука с частотой от 1 kHz до 3 kHz очень сложно. Число ошибок при определении местоположения источников звука возрастает при снижении разницы между соотношениями амплитуд (чем выше пиковое значение амплитуды звукового сигнала, тем труднее определить местоположение источника). Это означает, что нужно использовать частоту дискретизации (которая должна быть вдвое больше значения частоты звука) соответствующей как минимум 22050 Hz при 16 бит для реальной действенности HRTF. Дискретизация 8 бит не обеспечивает достаточной разницы амплитуд (всего 256 вместо 65536), а частота 11025 Hz не обеспечивает достаточной частотной характеристики (так как при этом максимальная частота звука соответствует 5512 Hz). Итак, чтобы применение HRTF было эффективным, необходимо использовать частоту не ниже 22050 Hz при, хотя бы, 16 битной дискретизации.
Ушная раковина (Pinna)
Мозг человека анализирует разницу амплитуд, как звука, достигшего внешнего уха, так и разницу амплитуд в слуховом канале после ушной раковины для определения местоположения источника звука. Ушная раковина создает нулевую и пиковую модель звучания между ушами; эта модель совершенно разная в каждом слуховом канале и эта разница между сигналами в ушах представляет собой очень эффективную функцию для определения, как частоты, так и местоположения источника звука. Но это же явление является причиной того, что с помощью HRTF нельзя создать корректного восприятия звука через колонки, так как по теории ни один из звуков, предназначенный для одного уха не должен быть слышимым вторым ухом.
Мы вновь вернулись к необходимости использования дополнительных алгоритмов CC. Однако, даже при использовании кодирования звука с помощью HRTF источники звука являются неподвижными (хотя при этом амплитуда звука может увеличиваться). Это происходит из-за того, что ушная раковина плохо воспринимает тыловой звук, т.е. когда источники звука находятся за спиной слушателя. Определение местоположения источника звука представляет собой процесс наложения звуковых сигналов с частотой, отфильтрованной головой слушателя и ушными раковинами на мозг с использованием соответствующих координат в пространстве. Так как происходит наложение координат только известных характеристик, т.е. слышимых сигналов, ассоциируемых с визуальным восприятием местоположения источников звука, то с течением времени мозг "записывает" координаты источников звука и в дальнейшем определение их местоположения может происходить лишь на основе слышимых сигналов. Но видим мы только впереди. Соответственно, мозг не может правильно расположить координаты источников звука, расположенных за спиной слушателя при восприятии слышимых сигналов ушной раковиной, так как эта характеристика является неизвестной. В результате, мозг может располагать координаты источников звука совсем не там, где они должны быть. Подобную проблему можно решить только при использовании вспомогательных сигналов, которые бы помогли мозгу правильно располагать в пространстве координаты источников звуков, находящихся за спиной слушателя.
Неподвижные источники звука
Все выше сказанное подвело нас к еще одной проблеме:
Если источники звука неподвижны, они не могут быть точно локализованы, как "статические" при моделировании, т.к. мозгу для определения местоположения источника звука необходимо наличие перемещения (либо самого источника звука, либо подсознательных микро перемещений головы слушателя), которое помогает определить расположение источника звука в геометрическом пространстве. Нет никаких оснований, ожидать, что какая-либо система на базе HRTF функций будет корректно воспроизводить звучание, если один из основных сигналов, используемый для определения местоположения источника звука, отсутствует. Врожденной реакцией человека на неожидаемый звук является повернуть голову в его сторону (за счет движения головы мозг получает дополнительную информацию для локализации в пространстве источника звука). Если сигнал от источника звука не содержит особую частоту, влияющую на разницу между фронтальными и тыловыми HRTF функциями, то такого сигнала для мозга просто не существует; вместо него мозг использует данные из памяти и сопоставляет информацию о местоположении известных источников звука в полусферической области.
Каково же будет решение?
Лучший метод воссоздания настоящего 3D звука это использование минимальной частоты дискретизации 22050 Hz при 16 битах и использования дополнительных тыловых колонок при прослушивании. Такая платформа обеспечит пользователю реалистичное воспроизведение звука за счет воспроизведение через достаточное количество колонок (минимум три) для создания настоящего surround звучания. Преимущество такой конфигурации заключается в том, что когда слушатель поворачивает голову для фокусировки на звуке какого-либо объекта, пространственное расположение источников звука остается неизменным по отношению к окружающей среде, т.е. отсутствует проблема sweet spot.
Есть и другой метод, более новый и судить о его эффективности пока сложно. Суть метода, который разработан Sensaura и называется MultiDrive, заключается в использовании HRTF функций на передней и на тыловой паре колонок (и даже больше) с применением алгоритмов CC. На самом деле Sensaura называет свои алгоритмы СС несколько иначе, а именно Transaural Cross-talk cancellation (TCC), заявляя, что они обеспечивают лучшие низкочастотные характеристики звука. Инженеры Sensaura взялись за решение проблемы восприятия звучания от источников звука, которые перемещаются по бокам от слушателя и по оси фронт/тыл. Заметим, что Sensaura для вычисления HRTF функций использует так называемое "цифровое ухо" (Digital Ear) и в их библиотеке уже хранится более 1100 функций. Использование специального цифрового уха должно обеспечивать более точное кодирование звука. Подчеркнем, что Sensaura создает технологии, а использует интерфейс DS3D от Microsoft.
Технология MultiDrive воспроизводит звук с использованием HRTF функций через четыре или более колонок. Каждая пара колонок создает фронтальную и тыловую полусферу соответственно.
Фронтальные и тыловые звуковые поля специальным образом смещены с целью взаимного дополнения друг друга и за счет применения специальных алгоритмов улучшает ощущения фронтального/тылового расположения источников звука. В каждом звуковом поле применяются собственный алгоритм cross-talk cancellation (CC). Исходя из этого, есть все основания предполагать, что вокруг слушателя будет плавное воспроизведение звука от динамично перемещающихся источников и эффективное расположение тыловых виртуальных источников звука. Так как воспроизводимые звуковые поля основаны на применении HRTF функций, каждое из создаваемых sweet spot (мест, с наилучшим восприятием звучания) способствует хорошему восприятию звучания от источников по сторонам от слушателя, а также от движущихся источников по оси фронт/тыл. Благодаря большому углу перекрытия результирующее место с наилучшим восприятием звука (sweet spot) покрывает область с гораздо большей площадью, чем конкурирующие четырех колоночные системы воспроизведения. В результате качество воспроизводимого 3D звука должно существенно повысится.
Если бы не применялись алгоритмы cross-talk cancellation (CC) никакого позиционирования источников звука не происходило бы. Вследствие использования HRTF функций на четырех колонках для технологии MultiDrive необходимо использовать алгоритмы CC для четырех колонок, требующие чудовищных вычислительных ресурсов. Из-за того, что обеспечить работу алгоритмов CC на всех частотах очень сложная задача, в некоторых системах применяются высокочастотные фильтры, которые срезают компоненты высокой частоты. В случае с технологией MultiDrive Sensaura заявляет, что они применяют специальные фильтры собственной разработки, которые позволяют обеспечить позиционирование источников звука, насыщенными высокочастотными компонентами, в тыловой полусфере. Хотя sweet spot должен расшириться и восприятие звука от источников в вертикальной плоскости также улучшается, у такого подхода есть и минусы. Главный минус это необходимость точного позиционирования тыловых колонок относительно фронтальных. В противном случае никакого толка от HRTF на четырех колонках не будет.
Стоит упомянуть и другие инновации Sensaura, а именно технологии ZoomFX и MacroFX, которые призваны улучшить восприятие трехмерного звука. Расскажем о них подробнее, тем более что это того стоит.
MacroFX
Как мы уже говорили выше, большинство измерений HRTF производятся в так называемом дальнем поле (far field), что существенным образом упрощает вычисления. Но при этом, если источники звука располагаются на расстоянии до 1 метра от слушателя, т.е. в ближнем поле (near field), тогда функции HRTF плохо справляются со своей работой. Именно для воспроизведения звука от источников в ближнем поле с помощью HRTF функций и создана технология MacroFX. Идея в том, что алгоритмы MacroFX обеспечивают воспроизведение звуковых эффектов в near-field, в результате можно создать ощущение, что источник звука расположен очень близко к слушателю, так, будто источник звука перемещается от колонок вплотную к голове слушателя, вплоть до шепота внутри уха слушателя. Достигается такой эффект за счет очень точного моделирования распространения звуковой энергии в трехмерном пространстве вокруг головы слушателя из всех позиций в пространстве и преобразование этих данных с помощью высокоэффективного алгоритма. Особое внимание при моделировании уделяется управлению уровнями громкости и модифицированной системе расчета задержек по времени при восприятии ушами человека звуковых волн от одного источника звука (ITD, Interaural Time Delay). Для примера, если источник звука находится примерно посередине между ушами слушателя, то разница по времени при достижении звуковой волны обоих ушей будет минимальна, а вот если источник звука сильно смещен вправо, эта разница будет существенной. Только MacroFX принимает такую разницу во внимание при расчете акустической модели. MacroFX предусматривает 6 зон, где зона 0 (это дистанция удаления) и зона 1 (режим удаления) будут работать точно так же, как работает дистанционная модель DS3D. Другие 4 зоны это и есть near field (ближнее поле), покрывающие левое ухо, правое ухо и пространство внутри головы слушателя.
Этот алгоритм интегрирован в движок Sensaura и управляется DirectSound3D, т.е. является прозрачным для разработчиков приложений, которые теперь могут создавать массу новых эффектов. Например, в авиа симуляторах можно создать эффект, когда пользователь в роли пилота будет слышать переговоры авиа диспетчеров так, как если бы он слышал эти переговоры в наушниках. В играх с боевыми действиями может потребоваться воспроизвести звук пролетающих пуль и ракет очень близко от головы слушателя. Такие эффекты, как писк комара рядом с ухом теперь вполне реальны и доступны. Но самое интересное в том, что если у вас установлена звуковая карта с поддержкой технологии Sensaura и с драйверами, поддерживающими MacroFX, то пользователь получит возможность слышать эффекты MacroFX даже в уже существующих DirectSound3D играх, разумеется, в зависимости от игры эффект будет воспроизводиться лучше или хуже. Зато в игре, созданной с учетом возможности использования MacroFX. Можно добиться очень впечатляющих эффектов.
Поддержка MacroFX будет включена в драйверы для карт, которые поддерживают технологию Sensaura.
ZoomFX
Современные системы воспроизведения позиционируемого 3D звука используют HRTF функции для создания виртуальных источников звука, но эти синтезированные виртуальные источники звука являются точечными. В реальной жизни звук зачастую исходит от больших по размеру источников или от композитных источников, которые могут состоять из нескольких индивидуальных генераторов звука. Большие по размерам и композитные источники звука позволяют использовать более реалистичные звуковые эффекты, по сравнению с возможностями точечных источников звука. Так, точечный источник звука хорошо применим при моделировании звука от большого объекта удаленного на большое расстояние (например, движущийся поезд). Но в реальной жизни, как только поезд приближается к слушателю, он перестает быть точечным источником звука. Однако в модели DS3D поезд все равно представляется, как точечный источник звука, а значит, страдает реализм воспроизводимого звука (т.е. мы слышим звук скорее от маленького поезда, нежели от огромного состава громыхающего рядом). Технология ZoomFX решает эту проблему, а также вносит представление о большом объекте, например поезде как собрание нескольких источников звука (композитный источник, состоящий из шума колес, шума двигателя, шума сцепок вагонов и т.д.).
Для технологии ZoomFX будет создано расширение для DirectSound3D, подобно EAX, с помощью которого разработчики игр смогут воспроизводить новые звуковые эффекты и использовать такой параметр источника звука, как размер. Пока эта технология находится на стадии завершения.
Компания Creative реализовала аналогичный подход, как в MultiDrive от Sensaura, в своей технологии CMSS (Creative Multispeaker Surround Sound) для серии своих карт SB Live!. Поддержка этой версии технологии CMSS, с реализацией HRTF и CC на четырех колонках, встроена в программу обновления LiveWare 2.x. По своей сути, технология CMSS является близнецом MultiDrive, хотя на уровне алгоритмов CC и библиотек HRTF наверняка есть отличия. Главный недостаток CMSS такой же, как у MultiDrive — необходимость расположения тыловых колонок в строго определенном месте, а точнее параллельно фронтальным колонкам. В результате возникает ограничение, которое может не устроить многих пользователей. Не секрет, что место для фронтальных колонок давно зарезервировано около монитора. Место для сабвуфера можно выбрать любым, обычно это где-то в углу и на полу. А вот тыловые колонки пользователи располагают там, где считают удобным для себя. Не каждый захочет расположить их строго за спиной и далеко не у всех есть свободное место для такого расположения.
Заметим, что главный конкурент Creative на рынке 3D звука, компания Aureal, использует технику панорамирования на тыловых колонках. Объясняется это именно отсутствием строгих ограничений на расположение тыловых колонок в пространстве.
Не стоит забывать и о больших объемах вычислений при расчете HRTF и Cross-talk Cancellation для четырех колонок.
Еще один игрок на рынке 3D звука — компания QSound пока имеет сильные позиции только в области воспроизведения звука через наушники и две колонки. При этом свои алгоритмы для воспроизведения 3D звука через две колонки и наушники (в основе лежат HRTF) QSound создает исходя из результатов тестирования при прослушивании реальными людьми, т.е. не довольствуется математикой, а делает упор на восприятие звука конкретными людьми. И таких прослушиваний было проведено более 550000! Для воспроизведения звука через четыре колонки QSound использует панорамирование, т.е. тоже, что было в первой версии CMSS. Такая техника плохо показала себя в играх, обеспечивая слабое позиционирование источников звука в вертикальной плоскости.
Компания Aureal привнесла в технологии воспроизведения 3D звука свою технику Wavetracing. Мы уже писали об этой технологии, вкратце, это расчет распространения отраженных и прошедших через препятствия звуковых волн на основе геометрии среды. При этом обеспечивается полный динамизм восприятия звука, т.е. полная интерактивность.
Итак, подведем итоги. Однозначный вывод состоит в том, что если вы хотите получить наилучшее качество 3D звука, доступное на сегодняшний день, вам придется использовать звуковые карты, поддерживающие воспроизведение минимум через четыре колонки. Использование только двух фронтальных колонок — это конфигурация вчерашнего дня. Далее, если вы только собираетесь переходить на карты с поддержкой четырех и более колонок, то перед вами встает классическая проблема выбора. Как всегда единственная рекомендация состоит в том, чтобы вы основывали свой выбор на собственных ощущениях. Послушайте максимально возможно число разных систем и сделайте именно свой выбор.
Теперь посмотрим, с каким багажом подошли ведущие игроки 3D звукового рынка к сегодняшнему дню и что нас ждет в ближайшем будущем.
EAR
EAR — в текущей версии IAS 1.0 реализована поддержка воспроизведения DS3D, A3D 1.0 и EAX 1.0 через четыре и более колонок. За счет воспроизведения через четыре и более колонок, мозг слушателя получает дополнительные сигналы для правильного определения местоположения источников звука в пространстве.
Осенью ожидается выход IAS 2.0 с поддержкой DirectMusic, YellowBook, EAX 2.0 и A3D 2.0, force-feed back (мы сможем чувствовать звук, а именно давление звука, громкость и т.д.), декодирование в реальном времени MP3 и Dolby/DTS, будет реализована поддержка ".1" канала (сабвуфера). Кроме того, в IAS 2.0 будет реализовано звуковое решение, не требующее наличие звуковой карты (cardless audio solution) для использования с полностью цифровой системой воспроизведения звука, например с USB колонками или в тандеме с домашней системой Dolby Digital.
Главные достоинства IAS от EAR:
- Один интерфейс для любой многоколоночной платформы, обеспечивающий одинаковый результат вне зависимости от того, как воспроизводится звук при использовании специального API.
- Имеется поддержка воспроизведения через две колонки (для старых систем), если многоколоночная конфигурация недоступна.
- Пользователь может подключить свой компьютер к домашней звуковой системе (Dolby Digital и т.д.) и IAS будет воспроизводить звук без необходимости какой-либо модернизации.
Итак, по сравнению с конкурентами, IAS работает на любой платформе и не требует специального аппаратного обеспечения. При этом IAS использует любое доступное аппаратное обеспечение и обеспечивает пользователю наилучшее качество звука, которое доступно на его системе. Только вот остановит ли свой выбор пользователь на этой технологии, это большой вопрос. С другой стороны, для использования IAS не нужно покупать специальных звуковых карт.
Sensaura
Sensaura — компания занимающаяся созданием технологий. Производители звуковых чипов лицензируют разработки Sensaura и воплощают их в жизнь. В чипе Canyon3D от ESS будет реализована поддержка современных технологий Sensaura, которые должны обеспечить слушателем 3D звук на современном уровне, т.е. позиционируемый в пространстве и с воспроизведением через четыре и более колонок. За воспроизведение через четыре и более колонок отвечает технология MultiDrive, которая реализует HRTF и алгоритмы Cross-talk cancellation. Многообещающе выглядят технологии ZoomFX и MacroFX. Кроме того, Sensaura поддерживает воспроизведение реверберации через EAX от Creative, равно как и через I3DL2, а также эмулирует поддержку A3D 1.х через DS3D.
Первым звуковым чипом, который реализует технологию MultiDrive на практике, является Canyon3D компании ESS Technology. Более подробную информацию о чипе Canyon3D можно найти на официальном сайте www.canyon3d.com.
Первая карта на базе чипа Canyon3D называется DMX и производит ее компания Terratec.
Как только эта карта попадет к нам на испытания, мы представим на ваш суд обзор. Заметим только, что на этой карте будут сразу оба типа цифровых выходов S/PDIF коаксиальный (RCA) и оптический (Toslink), и один цифровой вход. Так что продукт обещает быть очень интересным.
Creative
Creative — занимается совершенствованием своего движка реверберации. В итоге в свет выйдет EAX 3.0, который должен добавить больше реализма в воспроизводимый звук. Никто не спорит, что реверберация это хорошо, что именно она обеспечивает насыщенное и живое звучание. При этом Creative упорно не собирается вести разработки в области геометрии акустики. Кстати, Microsoft объявила о намерении включить EAX в состав DirectSound3D 8.0. С другой стороны, есть неподтвержденные слухи, что EAX 3.0 будет закрытым стандартом. Интересно, изменит ли Creative свою позицию со временем? Пока же в новых версиях EAX нам обещают больше реализма и гибкости в настройках реверберации и моделировании звуковой среды для конкретных объектов и помещений, плюс плавные переходы от одной заранее созданной звуковой среды к другой при движении слушателя в 3D мире. Будут улучшения в области воспроизведения эффектов окклюзии и обструкции. Обещают и поддержку отраженных звуков, но без учета геометрии и более продвинутую дистанционную модель. Вообще, я не удивлюсь, если Creative лицензирует MacroFX и ZoomFX у Sensaura. Что касается моделирования звука на основе физической геометрии среды, то Creative очень усиленно отрицает для себя возможность поддержки такого метода. Хотя, если поднять архивы и посмотреть первый пресс-релиз о будущем чипе Emu10k1, то вы будете удивлены. Там говорится именно об использовании физической геометрии среды при моделировании звука. Потом планы изменились. Кто помешает Creative вновь изменить планы? Особенно если учесть появление в ближайшее время движка реверберации от Aureal. Вряд ли Creative не сделает ответного хода.
QSound
QSound ведет работы по созданию новой технологии воспроизведения 3D звука через четыре и более колонок. Зная пристрастия QSound, можно предположить, что в основу новой технологии опять лягут результаты реальных прослушиваний. QSound, как и Sensaura занимается именно технологиями, которые воплощают в виде чипов другие компании. Так, чип Thunderbird128 от VLSI воплощает в себе все последние достижения QSound в области 3D звука, при этом Thunderbird128 это DSP, а значит, есть все основания ожидать последующей модернизации. Стоит упомянуть, что QSound, подобно Creative считает, что главное в 3D звуке это восприятие слушателем окружающей атмосферы игры. Поэтому QEM (QSound Environmental Modeling) совместима с EAX 1.0 от Creative. Следует ожидать, что QEM 2.0 будет совместима с EAX 2.0. Отметим, что QSound славится очень эффективными алгоритмами и грамотным распределением доступных ресурсов, неслучайно именно их менеджер ресурсов был лицензирован Microsoft и включен в DirectX.
Aureal
С Aureal все более-менее понятно. В ближайшем будущем нам обещают дальнейшее улучшение функциональности A3D, мощный движок реверберации, поддержку HRTF на четырех и более колонках. Кроме того, есть вероятность, что Aureal начнет продавать свои карты под своей маркой. Кстати, осенью должны начаться продажи супер колонок под маркой Aureal.
Мы упомянули основные разработки в области 3D звука, которые применяются в компьютерном мире. Есть еще ряд фирм с интересными решениями, но они делают упор на рынок бытовой электроники, поэтому мы не стали в данном материале рассказывать о них.
Ну что же, надеюсь, вы получили представление о том, как создается 3D звук и о том, какими параметрами должны обладать звуковые карты и акустические системы. Компьютерная индустрия звука продолжает поступательное развитие. Нам, как пользователям, это только на руку. Можно прогнозировать, что будущие звуковые карты и звуковые интерфейсы позволят разработчикам игр создавать потрясающие своей реальностью и производимым впечатлением эффекты. Библиотеки HRTF будут все дальше совершенствоваться. Возможно, чипы звуковых карт будут поддерживать декодирование AC-3 и других форматов цифрового звука. Звуковые карты будут поддерживать подключение более четырех колонок. Широкое распространение получат цифровые интерфейсы и цифровые подключения. Отдельной веткой будут развиваться дешевые решения на базе AMR. Нам же остается самая сложная часть, выбрать именно тот продукт, который устроит нас по всем параметрам. Не забывайте, что звук каждый слышит по-своему, поэтому, только послушав самостоятельно, вы составите правильное мнение о звуковой карте и звуковых технологиях.
Помощь при подготовке статьи оказал профессор Richard O. Duda (Web Site)
из San Jose State University с кафедры Electrical Engineering .
Использованы материалы с сайтов EAR и Sensaura.
| 15 июля 1999 г., дополнено 17 октября 1999 г. |