nForce — это сила!
Интересно, что в английской транскрипции nForce звучит как "enforce", что означает "принуждать; насаждать; навязывать". Но может и не стоит ничего навязывать — с такой теоретической функциональностью и производительностью, если она подтвердится на практике, платы на этом чипсете будут разлетаться громадными тиражами…
В наше время бурного развития IT индустрии зачастую получается, что главное — это темпы роста. А порою, даже, величина изменения в большую сторону этих темпов роста. И здесь перспективная компания NVIDIA вынуждена искать новые резервы, чтобы оставаться на лидирующих позициях. Львиная доля рынка графических ускорителей, принадлежащая ныне этой компании по-прежнему увеличивается. Но увеличивать ее становится все сложнее и сложнее, особенно учитывая наметившиеся тенденции спада покупательной способности. Все равно, как ни крути, останется XX% "недовольных и непримкнувших", которые будут покупать альтернативную продукцию. И переубедить их если и возможно, то очень дорого. Другое дело корпоративный рынок — тут у NVIDIA еще непаханое поле — здесь царствуют Intel с его интегрированными решениями и ATI. Именно захват весомой доли корпоративного рынка становится для NVIDIA одной из основных задач на ближайшее время. Надо отметить, что NVIDIA, как всегда, на высоте в смысле стратегии. Вместо того, чтобы прилежно играть на чужом поле, конкурируя с Intel и ATI, она просто создает новые правила, удобные именно для нее. А именно: не секрет, что бытует мнение (не безосновательное) что для офисных и корпоративных применений, как правило, не нужна 3D графика. С другой стороны, именно в 3D позиции NVIDIA сильны как никогда. Большие компании уделяют большое внимание TCO (total cost of ownership — общая стоимость владения) и поэтому в офисах очень популярны интегрированные решения в смысле затрат на приобретение и обслуживание. Что ж, NVIDIA создает интегрированный чипсет "все в одном" и активно начинает продвигать инструментарии, позволяющие использовать 3D графику в бизнесе (объемные модели продуктов, презентации, графики и т.д.). В итоге NVIDIA попытается изменить стереотипы и убедить корпоративный рынок, что без современной 3D графики в офисе обойтись никак нельзя, а заодно и предложит своевременное решение этой проблемы.
И действительно, если NVIDIA может сделать графический ускоритель из 57 миллионов транзисторов, то, поверьте, опыт разработки таких сложных чипов уже обеспечивает 50% успеха при разработке любого другого решения, в том числе чипсета. Тем более — чипсета с интегрированной графикой, что позволяет кроме чисто "теоретических" наработок использовать готовое графическое ядро. Кроме того, всячески подчеркивается, что если ранее компьютер использовался, как правило, для классического офисного набора приложений (почта, редактор таблиц, редактор текстов), то сейчас даже в корпоративной среде возникает необходимость в решении широкого круга именно мультимедийных задач — редактирование видео, объемный звук, 3D графика. Именно для офисных компьютеров XXI века предлагает свое новое детище NVIDIA.
Представляем NVIDIA nForce Platform Processing Architecture (NVIDIA nForce)
Чипсет выполнен как классический набор из двух микросхем, которые являются северным и южным мостами соответственно. Но компания NVIDIA не была бы собой, если бы преподнесла все именно в таком виде. Вместо банальных и приевшихся North Bridge и South Bridge на арену выходят nForce Integrated Graphics Processor (IGP) и nForce Media and Communications Processor (MCP). Причем каждое из устройств позиционируется именно как процессор, способный взвалить на себя часть работы CPU, тем самым освободив его от части нагрузки. Несомненно, в этой предпосылке есть определенная доля правды — достаточно вспомнить, какое количество ресурсов центрального процессора забирает под свои нужды, например, AC'97 звук. Более того, именно такой подход к проектированию чипсетов представляется нам наиболее рациональным — стремление покорять все новые вершины производительности вынуждает применять механизмы более совершенные, нежели обычная буферизация и конвейеризация.
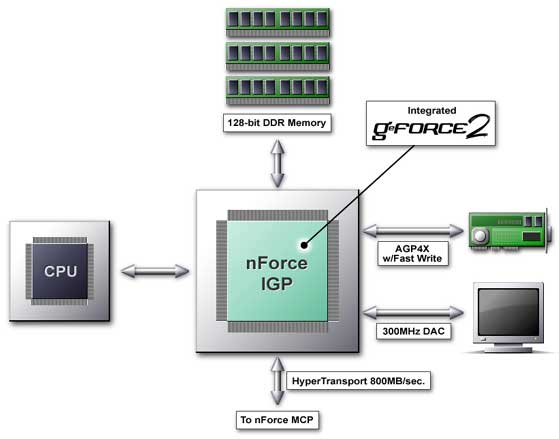
Северный мост (Integrated Graphics Processor — интегрированный графический процессор), как вы, наверное, уже догадались, снабжен интегрированным графическим решением. Фактически это встроенное в северный мост ядро GeForce2 MX. Все функциональные и тактические параметры интегрированного графического ядра полностью совпадают с GeForce2 MX. Отличия -
использование общей системной памяти (Shared Memory) и, как следствие, иная предельная
пропускная способность шины памяти и иная результирующая производительность, а также общение с процессором по более широкой (с пропускной полосой порядка 8x AGP) внутренней шине. Подробнее мы обсудим это чуть ниже.
А пока давайте отметим три основных момента, связанных с северным мостом:

- На данный момент планируется выпуск двух вариантов северного моста, IGP 64 и IGP 128, снабженных, соответственно, одной или двумя независимыми 64 битными (DDR SDRAM) шинами памяти. Судя по всему, фактически, это будет один чип, просто вторая шина памяти будет тем или иным образом отключаться.
- Возможно подключение внешнего AGP 4х ускорителя.
- На данный момент планируется выпуск только Socket A (предназначенных для процессоров AMD) версий северного моста, хотя разработан и Socket 370 вариант. Но Intel пока не выдал лицензию NVIDIA для производства чипсетов под Socket370.
Давайте более подробно познакомимся с архитектурой IGP:
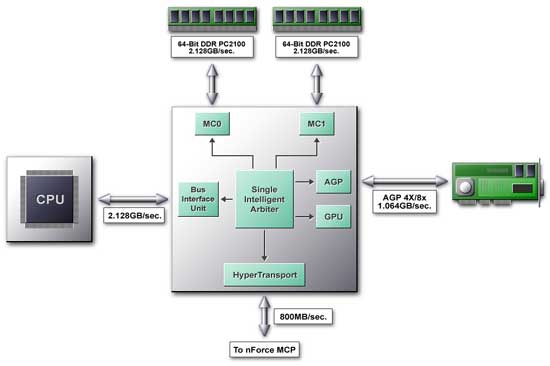
В основе северного моста лежит Single Intelligent Arbiter, являющийся связующим звеном для всех функциональных блоков. За этим названием скрывается специализированный блок, совмещающий в себе две функции. Первая достаточно проста и заключается в высокоскоростной коммутации функциональных блоков северного моста. В этой ипостаси Single Intelligent Arbiter выступает как кросс-коммутатор, обеспечивая следующие пути передачи данных при обмене с памятью:
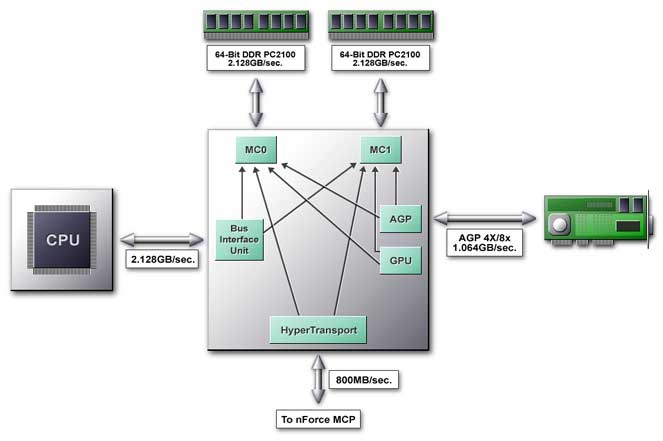
Кроме того, он обеспечивает передачу данных от процессора к внешней AGP 4х шине, встроенному графическому ядру и шине HyperTransport, но на этой схеме они не показаны. Зато вторая функция полностью оправдывает слово "Intelligent" в названии — арбитр располагает продвинутой системой кэширования, причем не только самих данных (очереди не редкость в современных чипсетах), но и различных алгоритмов (паттернов) обращения к памяти и на их основе способен осуществлять предсказание и выборку данных, которые, возможно, понадобятся в будущем (!). Этот механизм называется DASP.
DASP
В стремлении обеспечить процессоры, работающие на все более высоких частотах, непрерывным потоком данных, что позволило бы избежать простоев, компании-производители чипсетов придумывают все более сложные методы реализации этого механизма. Классическим примером может служить технология SuperBypass от AMD, позволяющая процессору в ряде случаев напрямую получать данные из памяти. Компания NVIDIA предлагает свой вариант реализации механизма, призванного обеспечить минимальные задержки данных на магистрали "процессор — чипсет — память". При этом, независимо от того, насколько большой обеспечивается прирост производительности, он внушает уважение уже одним названием — DASP (Dynamic Adaptive Speculative Pre-Processor). В данном случае ключевым словом в названии является Speculative, в общем случае применительно к микропроцессорным технологиям означающее выполнение каких-либо действий "по предположению" или, иначе говоря, "досрочно". Именно выполнение по предположению, независимо от того, потребуется ли оно реально, является основополагающим принципом уменьшения простоев конвейера в процессорах. Но почему бы не применить аналогичные технологии в чипсетах, благо связи компании NVIDIA c TSMC, уже сейчас располагающей технологическим процессом в .15 микрон, позволяют "нафаршировать" чипсет гигантским количеством дополнительных транзисторов без особого вреда для цены.
Итак, рассмотрим подробнее, что собой представляет DASP. Это устройство (agent), которое отслеживает запросы процессора, и на основе определенных алгоритмов пытается предсказать алгоритм (pattern) запросов. В примитивном виде это выглядит так: не секрет, что большинство обращений процессора к памяти имеет определенную форму, по которой можно судить, какие данные, и из какого участка памяти потребуются процессору. Подобно тому, как блок предсказания ветвлений в процессоре с большой вероятностью предугадывает, куда произойдет переход в программе, DASP предугадывает последовательность обращений процессора и заранее загружает данные, которые, по его мнению, понадобятся процессору, в свой кэш. В результате, при благоприятном исходе, к тому моменту, как процессор обращается за данными, они находятся не в оперативной памяти, а в кэше DASP, что позволяет серьезно уменьшить задержки. По словам NVIDIA, латентность в данном случае снижается на 40-60 процентов.
При этом эффективность DASP обусловлена двумя важными моментами.
Блок предсказаний одновременно отслеживает не один, а множество потоков данных, что позволяет максимально эффективно выбирать данные-кандидаты для помещения в кэш DASP. Более того, полностью конвейерная архитектура позволяет производить операции чтения из кэша/записи из памяти в кэш одновременно.
И второй момент — чипсет спроектирован таким образом, что в случае помещения в кэш ошибочно предсказанных данных, процессор в состоянии обратиться напрямую в память, минуя DASP. Результат — даже в случае "сложных" приложений, при крайне неэффективной работе DASP, никаких потерь в производительность системы он не внесет.
Давайте рассмотрим этот механизм более подробно. С точки зрения памяти процессор самый неприятный ее клиент. Если графический ускоритель, DMA контроллер IDE или звуковая карта считывают и записывают в память весьма предсказуемо и последовательно, из областей, заранее им отведенных, друг другу не мешают и безобразий не чинят, то вот центральный процессор скачет по памяти галопом, заглядывая в различные места и пересекаясь с ранее упомянутыми устройствами. А самое печальное, что зачастую CPU крохоборствует — прочитает строчечку своего кэша, потом из другого места строчечку. Синхронная память, даже с двумя параллельными каналами, существенно замедляет свою работу — ей приходиться заново устанавливать начальный адрес со всеми отсюда вытекающими задержками.
Как с этим бороться? Давайте для примера посмотрим на две распространенные задачи — умножение матрицы и поиск в базе данных (в памяти) по ключу:
Умножение. Параллельно идут две последовательности считывания и одна записи:
| Действие | Считывание из первой матрицы | Считывание из второй | Запись |
|---|---|---|---|
| 1 | ADDR1 (1 элемент 1 строки) | ADDR2 (1 элемент 1 строки) | ADDR3 |
| 2 | ADDR1+M (1 элемент 2 строки) | ADDR2+1 (2 элемент 1 строки) | ADDR3+1 |
| 3 | ADDR1+M*2 (1 элемент 3 строки) | ADDR2+2 (3 элемент 1 строки) | ADDR3+2 |
| … | … | ||
| N | ADDR1+M*N (1 элемент N строки) | ADDR2+N (N элемент 1 строки) | ADDR3+N |
Как мы видим, считывание выполняется последовательно только для второй матрицы, первая же читается скачками, пускай и через равный промежуток.
Поиск в базе по двум полям. Размер всей записи SIZE, смещение первого искомого поля от начала SHIFT1, второго SHIFT2.
| Сравнение | Чтение ключевого поля записей |
|---|---|
| 1 | ADDR+SHIFT1 (ключевое поле 1, первая запись) |
| 2 | ADDR+SHIFT2 (ключевое поле 2, первая запись) |
| 3 | ADDR+SIZE+SHIFT1 (ключевое поле 1, вторая запись) |
| ADDR+SIZE+SHIFT2 (ключевое поле 1, вторая запись) | |
| … | … |
| N*2 | ADDR+N*SIZE+SHIFT1 (ключевое поле 1, запись N) |
| N*2+1 | ADDR+N*SIZE+SHIFT2 (ключевое поле 1, запись N) |
Здесь уже сложнее, промежуток снова равный, но вот доступ к самой записи может затрагивать несколько полей. Однако и тут есть за что уцепиться — поля, как правило, бездушная машина считывает в одном и том же порядке.
DASP запоминает в ассоциативном массиве смещения между последующими операциями чтения, и потом, когда процессор снова начинает выполнять схожую операцию (например, обрабатывать следующую запись тем же образом) распознает уже известные ему последовательности или алгоритмы доступа (access patterns) и инициирует упреждающую выборку. Причем, он способен отслеживать несколько паттернов доступа параллельно, что отнюдь не редкость для современных мультимедийных и многозадачных применений. Об эффективности подобного механизма можно спорить очень долго, особенно не имея понятия о конкретном размере кэша паттернов и кэша для упреждающего чтения, а также, принимая во внимание наличие весьма эффективных механизмов кэширования внутри центрального процессора и весьма агрессивного доступа к памяти со стороны оного (не остается свободного времени для упреждающей выборки).
NVIDIA приводит цифры, согласно которым выигрыш (разница между работой с включенным и отключенным DASP) составляет от 6% до 30%. Причем, наибольшее преимущество достигается на валовых задачах копирования и поиска в памяти, посередине вычислительно интенсивные тесты, и в самом низу (8%-6%) хай-энд применения, такие как кодирование Windows Media Encoder 4.0 или окончательный рендеринг фильма в Adobe Premiere 5.0. Как бы там ни было — новаторская технология предвыборки данных из памяти на основе предсказания характера доступа устанавливает новую планку для всех разработчиков современных компьютерных архитектур.
Twinbank
Еще одним кардинальным нововведением компании NVIDIA стала разработка уникального двухканального контроллера DDR памяти, названного TwinBank Memory Architecture. Благодаря этой архитектуре обеспечивается невиданная для обычных PC пропускная способность подсистемы памяти, составляющая при использовании модулей PC2100, целых 4.2 ГБ/сек.
При этом возникает вопрос о сбалансированности системной шины процессоров Athlon и Duron, пропускная способность которой составляет 2.1 ГБ/сек при частоте 266 МГц, по отношению к возросшей в два раза пропускной способности шины памяти.
Для того, чтобы понять, насколько важен правильный баланс, вернемся немного назад. Для примера рассмотрим чипсет i840, в котором появился революционный двухканальный RDRAM контроллер с пропускной способностью 3.2 ГБ/сек, но при этом осталась обычная 133 МГц FSB. Можно констатировать факт, что выигрыш систем на базе i840 у систем на базе i815 с обычной PC133 памятью был крайне мал. В данном случае узким местом становилась шина FSB с пропускной способностью в 1.066 ГБ/сек. Более того, в ряде случаев система на i840 даже проигрывала i815 за счет более высокой латентности памяти RDRAM.
Казалось бы, ситуация повторяется, и компания NVIDIA усложнила себе жизнь, но при этом вряд ли добьется серьезного прироста производительности. Но не все так просто.
Здесь важно отметить два момента, которые отличают ситуацию с TwinBank Memory Architecture от описанной выше проблемы на примере i840. Очевидно, что переход на DDR память все же не влечет за собой того серьезного увеличения задержек, как в случае с RDRAM, обусловленных архитектурой памяти, и вполне сопоставим с обычным SDRAM. Но это не главное — главное, что такая подсистема памяти создавалась именно с расчетом на ту графическую подсистему, которая встраивается в чипсет. Именно доселе невиданная мощь графического GPU, использующего не отдельную память, а работающего по SMA (Shared Memory Architecture) принципу, вынудила инженеров NVIDIA расширить разрядность шины памяти до 128 бит, обеспечив тем самым беспрецедентную пропускную способность в 4.2 ГБ/сек.
В противном случае нечего было бы и огород городить — читатели лучше нас знают, как сильно медленная память может "задушить" видеосистему. Старый стереотип о том, что SMA решения не могут обеспечить приемлемой производительности в 3D ввиду медленной памяти, и собралась опровергнуть NVIDIA своим инновационным чипсетом.
Посмотрим поближе, как функционирует TwinBank Memory Architecture. В основе архитектуры лежат два независимых 64-разрядных контроллера DDR памяти, обозначенных на схеме (см. рисунок выше по тексту) как MC0 и MC1, и поддерживающих как PC2100, так и PC1600 DDR SDRAM.
Достоинство перекрестного контроллера состоит в том, что он позволяет процессору и GPU осуществлять одновременный доступ к банкам памяти. Данные в памяти хранятся по принципу чересстрочной организации (interleave) — такая схема позволяет начинать чтение блока данных из первого контроллера до того, как прочитана вторая половина предыдущего блока из второго контроллера.
За каждый такт каждый контроллер в состоянии выдать 128 бит данных (DDR). Так как практически все типы данных, которыми оперируют процессор и GPU, оптимизированы для 64-разрядного доступа, то практически во всех случаях доступ к памяти для процессора и GPU является одновременным и независимым.
В результате увеличивается эффективность доступа к памяти, как для процессора, так и для встроенного GPU, которые не простаивают в ожидании того, когда контроллер памяти закончит работу с другим устройством.
Ознакомившись с основными принципами работы контроллера памяти, самое время перейти к конкретным цифрам, характеризующим его более детально.
Контроллер памяти может функционировать как в 128-разрядном, так и в 64-разрядном режимах. При этом 64-разрядный режим поддерживается как первым контроллером — MC0, так и вторым — MC1, т.е. система будет работать независимо от того, в какой слот вы вставите свой DDR модуль. В случае, если пользователь желает получить от подсистемы памяти максимальную производительность, используя два контроллера, нелишне отметить, что за разъем DIMM0 отвечает MC0, а за два других — DIMM1/DIMM2 — MC1.
Оба контроллера обладают одинаковой функциональностью, но при этом параметры и тайминги каждого являются независимо программируемыми. В результате, даже в случае двух модулей памяти разной емкости или, например, PC2100 и PC1600 модулей, система все равно обеспечивает полноценный 128-разрядный доступ к памяти, но с определенными оговорками.
В результате чересстрочной организации работы контроллеров памяти удвоенная эффективность работы с памятью будет доступна только в той зоне, где объемы модулей совпадают. Т.е., если мы устанавливаем 128 и 256 Мб модули, то первые 128*2 (256) Мб будут доступны со скоростью 4,2 Гб/сек, а остаток большего модуля (128 Мб) со скоростью 2,1 Гб. Разумеется, для достижения оптимальной производительности системы понадобится два одинаковых по объему модуля.
Наряду с DDR памятью, поддерживается и обычная SDRAM, причем общий объем поддерживаемой памяти составляет 1.5 ГБ (при задействовании всех трех слотов), к сожалению, без поддержки ECC.
В теории получается весьма обнадеживающая картина — революционный двухканальный контроллер памяти в состоянии обеспечить как определенный прирост производительности системы в целом, в сравнении с обычными решениями, так и стать прекрасным компаньоном высокопроизводительному GPU, встроенному в чипсет. Совсем немного времени осталось до момента, когда данные факты получат практическое подтверждение.
Что касается встроенного графического ядра — тут можно ожидать как меньшую, так и превышающую GeForce2 MX производительность. В плюсе более широкая шина памяти (правда, только в том случае, когда остальные устройства и в первую очередь процессор эксплуатируют доступную полосу пропускания не в полную нагрузку). Кроме того, может помочь более широкая внутренняя шина процессор <-> встроенное графическое ядро с пропускной способностью, эквивалентной AGP 8x. На другой чаше весов остаются общая память (необходимость ожидать обращений к ней других устройств) и ее более низкая тактовая частота (133 МГц максимум вместо 166 или 200). Кроме того, интегрированные решения, как правило, имеют более низкое качество 2D графики (в силу целого набора причин, связанных с разводкой материнских плат и помехами). Только практические тесты во второй части нашего обзора смогут показать, насколько удалось это интегрированное решение.
В презентации NVIDIA приведены результаты nForce в тесте Quake3 (разрешение 1024х68х32). В этом частном случае производительность nForce с 64 битным доступом к памяти практически эквивалентна (чуть быстрее) картам на базе GeForce2 MX200, а nForce со 128 битным доступом примерно на 25% быстрее, чем GeForce2 MX200. Но эти цифры позволяют нам лишь сориентироваться в порядке результатов, их нельзя считать окончательными. Сейчас мы лишь хотим отметить, что встроенный в чипсет ускоритель класса GeForce2 MX, снабженный к тому же полноценным блоком HW T&L, это очень серьезная заявка на успех!
Венчает возможности северного моста высокоскоростной интерфейс HyperTransport, разработанный компанией AMD и обладающий пропускной способностью 800 Мб/сек. Именно он обеспечивает взаимодействие со вторым процессором чипсета — Media and Communications Processor (MCP).
nForce MCP
Южный мост также радует нас степенью интеграции и набором функциональных возможностей:
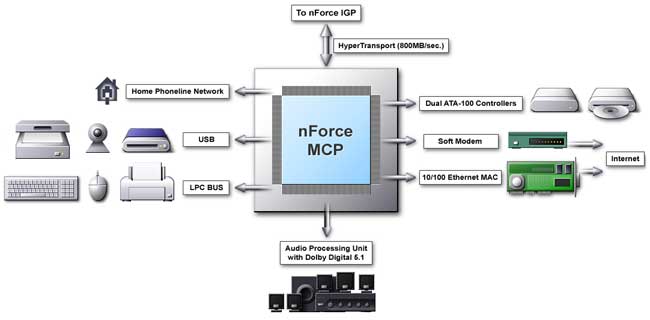
Называется он MCP (Media and Communications Processor) и обеспечивает следующую функциональность:

- Два канала IDE ATA-100
- Полный аппаратный DirectX 8 ускоритель звука (APU — Audio Processing Unit), включает аппаратный кодировщик Dolby Digital 5.1
- Шесть каналов USB
- LPC (Low Pin Count) шина для подключения контроллера PS/2 клавиатуры, мыши, портов COM и LPT, дисковода
- Сетевой интерфейс для 10/100 Mбит Ethernet (MAC уровень реализован в самом MCP) и сетей по телефонной проводке с обеспечением непрерывного синхронного потока данных (HomePNA 1.0/2.0)
- Интегрированный soft-modem и 2/4/6 канальный аудио кодек
- Контроллер PCI шины (на схеме не указан)
Планируется производить две версии MCP — с аппаратным Dolby Digital 5.1 кодировщиком и без оного. Соответственно, чипы будут называться MCP и MCP-D. Кстати, в XBox установлен совершенно такой же MCP-D чип, да и северный мост отличается только отсутствием внешнего AGP интерфейса, наличием Socket 370 коннектора и шиной, а также более мощным графическим ядром на базе GeForce3. Кроме того, память XBox (по-прежнему два независимых 64 бит DDR канала) будет тактоваться более высокой (200 МГц — 400 эффективная) частотой.
Интересно, что MCP поддерживает специальную патентованную технологию NVIDIA для обеспечения непрерывного изохронного (с постоянным тактовым интервалом) потока данных для сетевого интерфейса. Изохронность применительно к сетям передачи данных — передача пакетов данных через равные промежутки времени. На этом основываются высокоскоростные сетевые протоколы, причем в случае, если пакет не принят, его приходится посылать заново. Технология StreamThru призвана обеспечить встроенному сетевому контроллеру гарантированную пропускную способность, доведя количество пакетов, требующих повторной пересылки, до минимума.
Заявляется, что полноценный сетевой контроллер, встроенный в MCP, обеспечивает в реальных сетевых применениях производительность, на 15% превышающую аналоги, рассчитанные на шину PCI.
Самый интересный элемент MCP — APU (Audio Processing Unit).
APU
Многие компьютерные старожилы помнят о первом чипсете NVIDIA под названием NV1 (самая известная карта на этом чипе была Diamond EDGE 3D). В том самом чипе была одна примечательная особенность, а именно, довольно мощная по тем временам интегрированная звуковая подсистема производительностью 350 MIPS, аппаратная поддержка 32 звуковых каналов с частотой дискретизации 44,1 кГц и разрядностью 16 бит, семплы в новаторском формате DLS1 загружались в оперативную память компьютера. Но NVIDIA тогда опередила своё время, и, как это часто бывает в таких случаях, гениальность NV1 не была должным образом оценена индустрией. Однако теперь история делает очередной виток спирали. NVIDIA снова предлагает нам интегрированное решение — nForce. И на этот раз также не обошлось без набора новаций в его аудио части — APU.
Что такое APU?

nForce APU — модуль для обработки аудио данных (Audio Processing Unit), один из компонентов Media and Communications Processor (MCP). Призван разгрузить центральный процессор от специфических вычислений, связанных с обработкой звука.
По сравнению с обычной звуковой картой, nForce APU имеет следующие основные преимущества:
- аппаратная акселерация 256 2D голосов и 64 3D голосов, с поддержкой 3D позиционирования;
- полная поддержка всех возможностей DirectX 8.0, в том числе до 32 промежуточных буфера микширования с возможностью раздельного наложения эффектов;
- поддержка воспроизведения Dolby Digital 5.1 и возможность аппаратного кодирования в Dolby Digital на лету для обеспечения возможности передачи многоканального цифрового потока по цифре и последующего раскодирования и воспроизведения на внешнем качественном 5.1 аудио комплексе
Архитектура APU
По сути своей, Audio Processing Unit представляет собой мультипроцессорный движок рендеринга звуковых данных (audio rendering engine). Взглянем на схему:
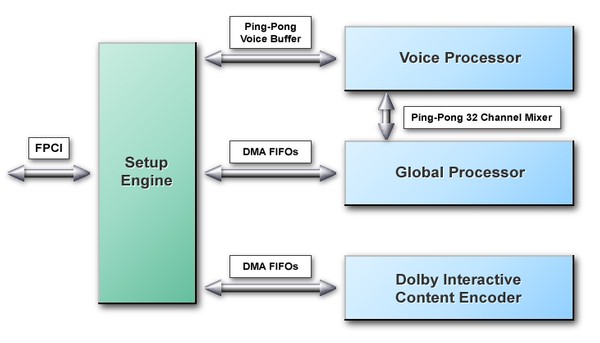
Общая структурная схема APU
APU делится на 4 основных функциональных блока:
- Setup Engine — этот модуль отвечает за установку параметров и подготовку данных для остальных процессоров в APU. Управление данными и DMA ресурсами лежит полностью на этом узле.
- Voice Processor — этот модуль содержит несколько заданных функций по цифровой обработке данных, применяемых над голосами, и микширования результатов таких операций в 32 микшерных буферах (mixer buffers).
- Global Processor — этот модуль предназначен для реализации программируемой цифровой обработки данных. Это позволяет применять к данным в микшерных буферах различные эффекты и получать конечный результат в виде выходного звукового потока для операционной системы.
- И, наконец, самый интересный, четвёртый модуль — Dolby Interactive Content Encoder. Представляет собой программируемый DSP, предназначенный для кодирования аудио данных в Dolby Digital (AC-3) поток, который может быть выведен на внешний бытовой декодер или ресивер (consumer decoder) по S/PDIF кабелю. Это позволяет передавать раздельную информацию для всех 5.1 каналов не по 6 отдельным аналоговым проводам, как обычно, а по всего одному проводу через цифровой интерфейс.
APU аппаратно ускоряет аудио потоки, как при записи, так и при воспроизведении. Все операции над аудио данными происходят полностью в системной памяти. Это позволяет направлять результирующий поток на любое цифровое устройство аудиоподсистемы, например на AC'97 кодек или USB колонки, или повторно использовать как один из источников для последующего микширования.
А теперь более подробно о каждом из четырёх модулей.
Setup Engine
Этот блок выполняет следующие функции:
- управление и установка приоритетов DMA каналам;
- управление и обновление голосовых структур (voice structures) в системной памяти;
- обсчёт списка исполнения голосов (voice execution lists) как 2D, так и 3D;
- установка параметров для голосового процессора (voice processor);
- устранение рассинхронизации (data de-interleaving) для более чем 2-канальных голосов;
- преобразование формата данных Data formatting — все данные переводятся в форму "24-битовое знаковое", прежде чем попасть в голосовой процессор;
- накопление данных — голосовой процессор представляет семплы данных (sample data) которые ему нужны в семпловых буферах (sample buffers);
- сохраняет выравнивание данных и условия для аудио петель (loops), если нужно;
- обеспечивает усреднение при даунсемплинге, если нужно;
- накапливает выходные данные, преобразуя в корректный формат, а затем пересылает в системную память, используя механизм DMA.
Voice Processor
Voice Processor (VP) осуществляет рендеринг всех 2D и 3D голосов. Расчёт фильтров HRTF выполняется в параллели с остальными 2D вычислениями. Все семплы микшируются в одном из 32 микшерных бункеров (mixer bins). Входные данные и параметры претерпевают двухсторонний обмен (ping-ponged), основываясь при этом на базовом понятии "голос" (voice).
Global Processor
Global Processor является программируемым DSP. Он выполняется следующие функции над каждым блоком данных:
- музыкальные эффекты: reverb, chorus, flanger, и т.п.;
- обработка эквалайзером;
- коррекция HRTF для колонок, заумно называемая сross-talk cancellation;
- I3DL2 реверберация, просчёт окклюзий и обструкций;
- пост-микширование для Setup Engine.
Dolby Interactive Content Encoder
Итак, nForce APU содержит интегрированный Dolby Interactive Content Encoder на базе программируемого DSP с преобразователем формата данных из фиксированного вида в представление с плавающей точкой (fix-to-float format engine). Данные берутся с выхода Global Processor и кодируются в Dolby Digital (AC-3) цифровой поток. Таким образом пользователь получает возможность насладиться многоканальным окружающим звуком кинотеатрального качества бла-бла-бла... отрендеренным в реальном времени посредством nForce APU и декодированным впоследствии на полноценном наборе домашнего кинотеатра или качественном мультимедийном комплекте 5.1 акустики с DD5.1 декодером.
Иллюстрация возможностей nForce APU для получения полноценного многоканального окружающего звука истинного кинотеатрального качества
Использование особенностей и преимуществ DirectX 8.0
Как многие помнят, в DirectX 7.0 под словом DirectMusic подразумевалась только несколько спорное на сегодня применение MIDI синтезатора Microsoft Sinthesizer, с возможностью загрузки своих семплов в DLS, для музыкального оформления программ. Легко назвать причины, по которым разработчики не любили DirectMusic до выхода DirectX 8.0:
- Мода на MIDI и трекерное музыкальное сопровождение ушла много лет назад, так как проблема ограничения на дисковое пространство более или менее разрешилась.
- Музыканты, которые пишут звуковые треки к программам и играм, используют проверенную временем студийную аппаратуру и профессиональные программы. Результат выходит в виде WAV-файла, а совсем не в MIDI.
- Композиторам очень неудобно писать саунд треки под убогий по сегодняшним временам стандартный 3 Мб DLS-банк от Roland (при всём уважении к этой фирме). Конечно, всё познаётся в сравнении. Но если есть возможность сделать хорошо и не напрягаясь в WAV, или же сделать сложно и непривычно, с невпечатляющим результатом, но в MIDI (DirectMusic), выбор сделать нетрудно. Стандартные эффекты реверберации и хоруса также не идут ни в какое сравнение с профессиональными DirectX плагинами.
- Купленные за приличные деньги или с большим трудом записанные свои банки семплов охраняются копирайтом или являются ноу-хау композитора. Переводить все существующие банки в DLS1/2 для свободного обмена никто, в общем-то, не торопится.
- Первоначально WAV-файлы всё-таки имели один существенный недостаток — большой объём. Но с распространением различных алгоритмов сжатия с потерями (mp3, wma файлы) и эта проблема на сегодня благополучно решилась.
Однако опыта по использованию MIDI технологий накопилось довольно много. Это работа без временных задержек (единицы миллисекунд) с семплами (samples) и отрывками (loops), поканальное наложение эффектов, панорамирование и т.п. Таким образом, с выходом DirectX 8.0 Microsoft решила сблизить DirectSound и DirectMusic, позволив программистам достичь гибкости и повысить качество музыкального оформления программ.
DirectX 8.0 вносит несколько качественно новых особенностей в своей аудио части — DirectSound и DirectMusic, например:
- DirectMusic теперь оперирует не только с MIDI, но и с любыми аудио семплами — эффектами, звуками и т.п. При этом обеспечивается вся мощь, точность и качество обработок и эффектов над звуком.
- Улучшенная поддержка железом. Переработаны системы микширования и механизм DLS2.
- I3DL2 выбран стандартом для обеспечения 3D звука, включая поддержку моделирования реверберации помещений, окклюзий и обструкций. Как над DirectSound, так и над DirectMusic голосами.
- Стратегический вопрос: почему бы не применить эффекты над семплами на этапе их создания в музыкальной студии? Ответ: дело в том, что некоторые звуки удобнее хранить в запакованном виде, или же в уменьшенной битности и разрядности — речь, низкочастотные эффекты и пр. Применение и сохранение эффектов заранее сильно ухудшает качество и по сравнению с рил-тайм применением становится просто не выгодно.
- Поддержка объектов DirectX Media (DMO). Теперь к DirectSound и DirectMusic можно применять различные эффекты, пользуясь при этом плагинами от третьих фирм или разработав свои собственные.
- Система аудио-скриптов — большая гибкость и меньше работы программистам.
APU был разработан именно как DX8 аудио процессор и имеет возможность просчитывать аппаратно:
- Downloadable Sounds версии 2 (DLS2). APU может выполнять работу со слоями и фильтрацию, используя стерео wave источники;
- Наложение эффектов на DirectSound буферы. Более сложные звуковые эффекты и интерактивный контроль над ними;
- Interactive 3D Audio Level 2 (I3DL2) — поддержка расчёта реверберации и окклюзий/обструкций. Сложная аббревиатура представляет собой всего лишь немного переработанную ассоциацией IA-SIG технологию EAX2 от великого и ужасного Creative. Дело в том, что I3DL2 — это не принадлежащий никому открытый стандарт, а EAX — всё же торговая марка Creative Labs;
- Промежуточно смикшированные аудио потоки — сложные, богатые звуки могут быть получены промежуточным микшированием двух или более аудио потоков.
3D sound API
Помимо этого, наконец-то выплывают плоды лицензионного соглашения между NVIDIA и Sensaura от 13.11.2000. Дополнительные возможности APU по использованию DS3D расширений Sensaura (см. статью Технологии Sensaura):
- Head Reference Transfer Functions (HRTF) фильтры с расчетом cross talk cancellation (см. статью Технология создания позиционируемого 3D звука);
- Эффекты ближнего поля (MacroFX);
- Макро эффекты (ZoomFX);
- 7-полосный графический эквалайзер (не имеет отношения к Sensaura :)).
Пока не ясно, будет ли присутствовать технология Digital Ear для подстройки HRTF фильтров под каждого пользователя.
Итак, заявлениям поклонников технологии A3D о фирме NVIDIA, как приемнике Aureal, скорее всего не суждено сбыться. Да, технологии Sensaura, как и многие другие 3D API, позволяют транслировать некоторые вызовы A3D 1.0 в DS3D. Однако это можно считать только лишь программной эмуляцией, но никак не полноценной поддержкой A3D (сама Aureal неоднократно заявляла о невозможности полноценной реализации A3D нигде, кроме чипов Vortex). Главная ошибка всех native API, приведшая их к забвению, их закрытость и вычурность. Вспомним Glide в графике, вспомним A3D в звуке. Аминь!
Другое дело EAX или I3DL2. Открытая реализация API в виде DS3D расширений делает возможным полноценную поддержку среди широкого круга производителей карт и 3D технологий — Sensaura, Creative Labs, CLR, QSound Labs. Однако и здесь среди пользователей PC царит очень много заблуждений. Одно из них в том, что есть всего 2 формата 3D звука: EAX и A3D. Ну, ещё и DS3D, который представляет собой какой-то программный отстой. А алгоритмы Sensaura — это что-то такое интересное, но так как в игре нет опции "Sensaura", то, видимо, её пока никто и не поддерживает.
К счастью, всё это не так. На самом деле, если не принимать во внимание умерший A3D, сейчас есть лишь один 3D API — DirectSound3D. В случае отсутствия современной звуковой карты при включении DS3D в работу (или при явном выборе) включается программный вариант DS3D — Hardware Emulation Layer, который по умолчанию представляет собой 8 бит 22 кГц звук условного качества с ужасным программным микшированием потоков. При наличии аппаратной поддержки DS3D программа передаёт вызовы API звуковому движку (в сущности, драйверам звуковой карты). А вот дальше в дело вступают алгоритмы, которые поддерживает карта (не обязательно полностью на аппаратном уровне). Часто эти алгоритмы носят названия торговых марок или фирм создателей: Sensaura, QSound. Только от конкретной программно-аппаратной реализации зависит, насколько качественно будет происходить позиционирование (панорамирование, эффект Доплера) звука в пространстве. При включении в игре опции EAX в работу включаются расширения того же DS3D по установке пресетов окружения звука — реверберации. EAX2 приводит в действия расширения DS3D по учёту окклюзий и обструкций. Опять же, качество реализации целиком и полностью зависит от драйверов и железа звуковой карты. Таким образом, алгоритмы Sensaura работают на полную катушку при выборе в игре аппаратного DirectSound3D, EAX1, EAX2 и I3DL2.
Кстати, посмотрим — сможет ли NVIDIA обеспечить звук в играх на 6 колонках с использованием фирменной технологии многоканального 3D звука MultiDrive от Sensaura. Единственное пока 6-канальное решение CS4630 использует с текущими драйверами для этого лишь 4 колонки.
Предварительное сравнение APU с другими 6-канальными звуковыми чипами
| Feature Comparison | NVIDIA nForce APU | Creative EMU10K1 | Philips Thunderbird | ForteMedia FM801 | Crystal Sem. CS4630 |
|---|---|---|---|---|---|
| Card Price | - | $85 Retail | $79 Retail | $25 Retail | $99 Retail |
| DSP or HW-accelerated 2D (Stereo) Voices | 256 | 64 | 256 | - | 64 |
| DSP or HW-accelerated 3D Voices | 64 | 32 | 64 | - | 32 |
| DX8 HW-Submixer | 32 | - | - | - | - |
| DLS2 Acceleration | + | - | - | - | - |
| Per Voice Parametric EQ | + | - | - | - | - |
| 3D Sound API | Sensaura | EAX | QSound | QSound | Sensaura |
| Occlusion and Obstruction | + | + | + | + | + |
| Near Field Effects | + | - | - | - | + |
| EAX2 or I3DL2 Reverb | + | + | + | + | + |
| Global Effects (Reverb, Chrous etc) | + | + | + | + | - |
| Speakers | 2, 4, 6, headphones | 2, 4, 6, headphones | 2, 4, 6, headphones | 2, 4, 6 | 2, 4, headphones |
| S/PDIF Interface | + | + | + | + | + |
| DD5.1 Encode | + | -* | - | - | - |
| DD 5.1 Decode | ? | +*** | +** | +** | +** |
* наличие кодирования в Dolby Pro Logic
** наличие декодирования DD 5.1 программным DVD-плеером
*** наличие декодирования DD 5.1 драйверами и программным DVD-плеером
Итак, APU поддерживает абсолютно все последние особенности звуковой части DirectX 8, обеспечивает большое количество аппаратно обсчитываемых голосов (DirectSound вплоть до 256, а также 64 DirectSound 3D), поддержку многоколоночных конфигураций вплоть до шести колонок (в играх вопрос остаётся за Sensaura). Более того, APU в состоянии запаковывать и переправлять данные в Dolby Digital потоке через S/PDIF подключение прямо на домашний кинотеатр.
NVIDIA старается, чтобы функциональность и качество аудио подсистемы компьютера вышло на один уровень с последними достижениями в 3D графике. Пожелаем ей в этом успеха! Тем более, что никто не мешает NVIDIA в будущем выпустить и отдельную звуковую карту на собственном APU...
Заключение
Чипсет NVIDIA nForce будет поставляться в четырех вариантах комплектации (128/64 битная шина памяти nForce IGP и наличие/отсутствие аппаратного кодирования Dolby Digital 5.1 в nForce MCP):
| nForce IGP 64 | nForce IGP 128 | |
|---|---|---|
| nForce MCP | nForce 220 | nForce 420 |
| nForce MCP-D (Dolby Digital 5.1) | nForce 220-D | nForce 420-D |
Большинство первых плат будут построены на основе 420 (420-D) комплекта.
В следующей части нашего обзора, которая выйдет сразу после возращения сотрудников нашей редакции с выставки Computex (Taiwan), мы подробно исследуем производительность и функциональные возможности плат на основе nForce. Пока же отметим, что основными партнерами NVIDIA на первых порах будут четыре хорошо известных производителя материнских плат и видео карт: ABIT, ASUS, Gigabyte и MSI.

Причем, плата от ASUS (A7N266-V) была первой подготовлена к производству (сейчас ASUS является основным партнером NVIDIA) и именно эта плата, скорее всего, будет использоваться при представлении nForce. На внешний вид платы A7N266-V можно посмотреть справа.
Отметим одну деталь: если пользователь установит в плату на базе чипсета nForce внешний графический ускоритель, имеющий на борту процессор от NVIDIA, то не нужно будет устанавливать новые драйверы. Все заработает буквально сразу. Это возможно благодаря уникальной архитектуре драйверов от NVIDIA, когда в каждой поставке драйверов встроено все, что требуется для работы любого графического процессора от NVIDIA. Представьте, что в компании стоит 1000 компьютеров и принято решение о модернизации видеоподсистемы. В случае с решением от NVIDIA модернизация пройдет в разы быстрее и дешевле в смысле трудозатрат, что немаловажно, особенно для корпоративного рынка.
Кстати, NVIDIA разработала специальные наклейки, которые могут размещаться на корпусах
компьютеров, внутри которых используются системные платы на базе nForce. Можно с уверенностью
 утверждать, что на компьютерах от Fujitsu-Siemens эти наклейки появятся в первую очередь, ведь именно
Fujitsu-Siemens является партнером NVIDIA по продвижению на корпоративный рынок nForce.
Впрочем, запас наклеек довольно внушителен и наверняка NVIDIA снабдит ими всех желающих OEM производителей компьютеров, которые будут создавать системы с использованием материнских плат на базе nForce.
утверждать, что на компьютерах от Fujitsu-Siemens эти наклейки появятся в первую очередь, ведь именно
Fujitsu-Siemens является партнером NVIDIA по продвижению на корпоративный рынок nForce.
Впрочем, запас наклеек довольно внушителен и наверняка NVIDIA снабдит ими всех желающих OEM производителей компьютеров, которые будут создавать системы с использованием материнских плат на базе nForce.
Вновь вспомним о XBox, тем более, что разрабатывая nForce, NVIDIA решала параллельно и проблему с чипсетом для приставки от Microsoft. В XBox будет использоваться чип под названием MCP-X — это полный аналог MCP-D, единственное отличие — отсутствие поддержки PCI шины. Кроме того, северный мост XBox представляет собой ничто иное, как IGP-128, в котором ядро GeForce2 заменено GeForce3, со специальным доработанным T&L блоком. Второе кардинальное отличие — процессор Intel Pentium III (специальный вариант) и, соответственно, AGTL системная шина. Два канала DDR памяти будут работать на частоте 200 МГц, обеспечивая, соответственно, пропускную способность более 6 Гб/сек. На долю встроенного ядра GeForce3 приходится более низкая, чем у его полноценного собрата, пропускная полоса памяти (да и процессор заберет свой 1 Гб/сек). Однако причин для беспокойства нет — приставке высокие разрешения и, как следствие, большие значения filrate не нужны. Для неё главное — эффекты и плавность исполнения — и то и это будет, высокая частота и модифицированный T&L позаботятся о геометрии и шейдерах. Да и внутренняя (в северном мосте) шина процессор <-> графическое ядро не только более широка, нежели стандартная ныне AGP 4x, но и свободна от многих ее задержек и недостатков. Однако, оставим XBox — ждать уже недолго.
Раз уж мы помянули корпорацию Intel, то не лишним будет обратить внимание всех заинтересованных сторон на следующее. Напомним, что чипсет nForce со 128 битной шиной FSB обеспечивает пропускную полосу для данных в 4.2 ГБ/сек, чего с лихвой хватит для процессора Intel Pentium 4 (если не использовать интегрированный в IGP графический акселератор). Перед Intel стоит дилемма, которую она никак не может решить: продавать процессоры или чипсеты. Плюс Intel пока смотрит на использование HyperTransport от AMD в системных платах под процессоры самой Intel, как на поддержку "одной, недружественной компании". Если Intel все-таки решит, что продавать собственные процессоры выгоднее, и что HyperTransport — просто хорошая и удобная технология, то, во-первых, на рынке появится отличный High-end чипсет под Pentium 4; во-вторых, появится и хороший чипсет под Pentium 4 для корпоративного сектора (куда Intel так хочет продвинуть Pentium 4); в-третьих, отпадет необходимость в продвижении чисто маркетинговых чипсетов типа i845 под Pentium 4 (ну, право, смешно предлагать под такой процессор решения с системной шиной, которая может прокачивать менее 3.2 ГБ/сек); в-четвертых, выиграют все пользователи и сама Intel, в частности, так как на рынке будут предлагаться правильные решения под хорошие процессоры и никто не будет критиковать Intel за политику в области рекламы и продаж. Посмотрим, какое решение примет эта компания, тем более что технически неразрешимых проблем при адаптации NVIDIA nForce под Pentium 4, по сути, нет.
Во второй части данной статьи (практической) мы детально остановимся на особенностях системных плат на чипсете nForce и уделим особое внимание стабильности и производительности. Мы также тщательно проверим возможности APU, входящего в состав nForce MCP.
Сейчас же подведем итоги по новому решению от NVIDIA — чипсету nForce:
Плюсы:
- Встроенное графическое ядро небывалой производительности (по сравнению с другими встроенными графическими решениями);
- Фантастическая пропускная полоса и эффективность работы с памятью, сбалансированная архитектура без узких мест;
- Предвыборка за счет использования DASP увеличивает эффективность работы CPU с памятью;
- Ускоритель звука нового поколения;
- Аппаратное кодирование Dolby Digital 5.1;
- Производительная сетевая архитектура + широкий набор интегрированных сетевых решений;
- Бескомпромиссные возможности и передовая производительность без дополнительных затрат, экономически оправданное решение;
- Широкие возможность последующего расширения (AGP 4х/USB/PCI), причем установка более производительной видеокарты от NVIDIA даже не потребует установки нового драйвера — т.к. используется единый унифицированный драйвер для всех функциональных блоков чипсета;
- Отличный чипсет для систем на базе AMD Athlon/Duron, ориентированных на корпоративный сектор;
- Отличный High-End чипсет для систем на базе AMD Athlon/Duron (только за счет чипсета можно добиться прироста в производительности примерно на 20%!);
Минусы:
- Пока нет в продаже :-)
| 4 июня 2001 г. |

|
| Дополнительно |
|

:no_upscale()/https://cdn.ixbt.site/ixbt-data/jp8xQvedXd/covers/IsI4GojhLyJbCJajXlgRnYy7GztO2iXhIvVlRRMc.jpg)
:no_upscale()/https://cdn.ixbt.site/ixbt-data/U80AxQ2TZv/covers/Qw35uV0mpLx0euXvtoR19bPN90CTVZJeCnlxVmax.jpg)
:no_upscale()/https://cdn.ixbt.site/ixbt-data/Tiky4gksYV/covers/7RINz0bJ5dhMAw8HGjBSZtIid2K44nRSBJIWm3Xx.jpg)





