

–Т—А–µ–і–љ—Л–є –Ї–Њ—А–Њ–ї—М
–Ц–Є–ї–Є-–±—Л–ї–Є –і–≤–µ –Ї–Њ–Љ–њ–∞–љ–Є–Є. –Ґ. –µ. –Є—Е, –Ї–Њ–љ–Ї—Г—А–µ–љ—В–Њ–≤, –Ї–Њ–љ–µ—З–љ–Њ, –±–Њ–ї—М—И–µ, –љ–Њ –Ј–∞–Ї–ї—П—В—Л–µ вАФ –Є–Љ–µ–љ–љ–Њ Intel –Є AMD. –Я—А–Є—З—С–Љ, —В–∞–Ї —Г–ґ –њ–Њ–ї—Г—З–Є–ї–Њ—Б—М: Intel, –Ї–∞–Ї –њ—А–∞–≤–Є–ї–Њ, —З—В–Њ-—В–Њ –љ–Њ–≤–Њ–µ –њ—А–Є–і—Г–Љ—Л–≤–∞–µ—В –Є –≤–љ–µ–і—А—П–µ—В –њ–µ—А–≤–Њ–є, –∞ AMD –≤–љ–µ–і—А—П–µ—В –≤—В–Њ—А–Њ–є, –љ–Њ –і–µ—И–µ–≤–ї–µ, –Њ—В–±–Є–≤–∞—П –Ї—Г—Б–Њ–Ї —А—Л–љ–Ї–∞. Intel —Н—В–Њ –љ–µ –љ—А–∞–≤–Є—В—Б—П, –Є –Њ–љ–∞ –љ–∞—З–Є–љ–∞–µ—В –і–µ–є—Б—В–≤–Њ–≤–∞—В—М –њ—А–Њ—В–Є–≤ –Ї–Њ–љ–Ї—Г—А–µ–љ—В–∞ –љ–µ —В–Њ–ї—М–Ї–Њ –Њ–±—Л—З–љ—Л–Љ–Є —Б–њ–Њ—Б–Њ–±–∞–Љ–Є (–≤—Л–њ—Г—Б–Ї–∞—П –Њ—З–µ—А–µ–і–љ–Њ–є –љ–Њ–≤—Л–є —З–Є–њ –Є–ї–Є —Б–љ–Є–ґ–∞—П —Ж–µ–љ—Л –≤ —Б–≤–Њ—О –Њ—З–µ—А–µ–і—М), –љ–Њ –Є –і—А—Г–≥–Є–Љ–Є, –Є–Ј-–Ј–∞ –Ї–Њ—В–Њ—А—Л—Е –њ–Њ—В–Њ–Љ AMD –њ–Њ–і–∞—С—В –љ–∞ Intel –≤ —Б—Г–і –њ–Њ –Њ–±–≤–Є–љ–µ–љ–Є—О –≤ –љ–µ—З–µ—Б—В–љ–Њ–є –Ї–Њ–љ–Ї—Г—А–µ–љ—Ж–Є–Є –Є –љ–∞—А—Г—И–µ–љ–Є–Є –∞–љ—В–Є–Љ–Њ–љ–Њ–њ–Њ–ї—М–љ—Л—Е –Ј–∞–Ї–Њ–љ–Њ–≤. –Э–µ—В –љ–µ–Њ–±—Е–Њ–і–Є–Љ–Њ—Б—В–Є –Њ–њ–Є—Б—Л–≤–∞—В—М –≤—Б–µ –њ–µ—А–Є–њ–µ—В–Є–Є —Н—В–Є—Е –і–µ–ї, –і–ї—П—Й–Є—Е—Б—П —Б –њ–µ—А–µ–Љ–µ–љ–љ—Л–Љ —Г—Б–њ–µ—Е–Њ–Љ –і–ї—П –Њ–±–µ–Є—Е —Б—В–Њ—А–Њ–љ —Б —Б–µ—А–µ–і–Є–љ—Л 80-—Е (—Б—З–Є—В–∞—П —В–∞–Ї–ґ–µ –Є –≤—Б—В—А–µ—З–љ—Л–µ –Є—Б–Ї–Є). –Ю–і–љ–∞–Ї–Њ —Б—А–µ–і–Є –∞—А—Б–µ–љ–∞–ї–∞ Intel –µ—Б—В—М –Њ–і–Є–љ –њ—А–Є—С–Љ, –Ї–Њ—В–Њ—А—Л–є –љ–∞–Љ –Њ—Б–Њ–±–µ–љ–љ–Њ –Є–љ—В–µ—А–µ—Б–µ–љ.
–Ь–љ–Њ–≥–Є–µ –њ—А–Њ–≥—А–∞–Љ–Љ–Є—Б—В—Л —Б—З–Є—В–∞—О—В –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А—Л Intel –ї—Г—З—И–Є–Љ–Є –≤ —В. —З. –Ј–∞ –Њ–њ—В–Є–Љ–Є–Ј–∞—Ж–Є—О –Ї–Њ–і–∞, –Є—Б–њ–Њ–ї—М–Ј—Г—П –Є—Е –і–ї—П —В—А–µ–±–Њ–≤–∞—В–µ–ї—М–љ—Л—Е –Ї —Б–Ї–Њ—А–Њ—Б—В–Є –њ—А–Њ–≥—А–∞–Љ–Љ. Intel —В–∞–Ї–ґ–µ –њ–Њ—Б—В–∞–≤–ї—П–µ—В –Љ–љ–Њ–ґ–µ—Б—В–≤–Њ –Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞–љ–љ—Л—Е —Д—Г–љ–Ї—Ж–Є–Њ–љ–∞–ї—М–љ—Л—Е –±–Є–±–ї–Є–Њ—В–µ–Ї –і–ї—П —А–∞–Ј–ї–Є—З–љ—Л—Е –њ—А–Њ—Д–µ—Б—Б–Є–Њ–љ–∞–ї—М–љ—Л—Е –њ—А–Є–Љ–µ–љ–µ–љ–Є–є. –Т–Њ –Љ–љ–Њ–≥–Є—Е —Б–ї—Г—З–∞—П—Е –љ–Є–Ї–∞–Ї–Є—Е —Б—Е–Њ–і–љ—Л—Е –њ–Њ —Б–Ї–Њ—А–Њ—Б—В–Є –∞–ї—М—В–µ—А–љ–∞—В–Є–≤ –Є–Љ –љ–µ—В. –Э–Њ —В–µ –ґ–µ –њ—А–Њ–≥—А–∞–Љ–Љ–Є—Б—В—Л –Ј–∞–Љ–µ—В–Є–ї–Є, —З—В–Њ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А—Л –Є –±–Є–±–ї–Є–Њ—В–µ–Ї–Є Intel —А–∞–±–Њ—В–∞—О—В –Ј–∞—З–∞—Б—В—Г—О –њ–Њ–і–Њ–Ј—А–Є—В–µ–ї—М–љ–Њ –Љ–µ–і–ї–µ–љ–љ–Њ –љ–∞ –¶–Я –њ—А–Њ–Є–Ј–≤–Њ–і—Б—В–≤–∞ –і—А—Г–≥–Є—Е –Ї–Њ–Љ–њ–∞–љ–Є–є. –Т—Б—С –і–µ–ї–Њ –≤ —В–Њ–Љ, —З—В–Њ –≤ –≥–µ–љ–µ—А–Є—А—Г–µ–Љ–Њ–Љ –Ї–Њ–і–µ (–≤ —Б–ї—Г—З–∞–µ –±–Є–±–ї–Є–Њ—В–µ–Ї вАФ –≤ –љ–∞–њ–Є—Б–∞–љ–љ–Њ–Љ –≤—А—Г—З–љ—Г—О) –µ—Б—В—М –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –≤–µ—А—Б–Є–є –љ–∞–Є–±–Њ–ї–µ–µ –Ї—А–Є—В–Є—З–љ—Л—Е —Г—З–∞—Б—В–Ї–Њ–≤, –Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞–љ–љ—Л—Е –і–ї—П –Ї–Њ–љ–Ї—А–µ—В–љ–Њ–є –∞—А—Е–Є—В–µ–Ї—В—Г—А—Л –Є–ї–Є –љ–∞–±–Њ—А–∞ –Ї–Њ–Љ–∞–љ–і (—З–∞—Й–µ –≤—Б–µ–≥–Њ –Є–Ј –ї–Є–љ–µ–є–Ї–Є SSEx). –Ґ–∞–Ї–ґ–µ –≤ –Ї–Њ–і–µ –µ—Б—В—М —Д—Г–љ–Ї—Ж–Є—П –Њ–њ—А–µ–і–µ–ї–µ–љ–Є—П —В–Є–њ–∞ –¶–Я (–љ–∞ –Ї–Њ—В–Њ—А–Њ–Љ –Ј–∞–њ—Г—Й–µ–љ –Ї–Њ–і), —З—В–Њ–±—Л –≤—Л–±—А–∞—В—М –≤–µ—А–љ—Г—О –≤–µ—В–≤—М вАФ –і–Є—Б–њ–µ—В—З–µ—А –¶–Я (–љ–µ –њ—Г—В–∞—В—М —Б –њ–ї–∞–љ–Є—А–Њ–≤—Й–Є–Ї–Њ–Љ вАФ —З–∞—Б—В—М—О –Ї–Њ–љ–≤–µ–є–µ—А–∞, –Ї–Њ—В–Њ—А—Г—О —В–∞–Ї–ґ–µ –Є–љ–Њ–≥–і–∞ –љ–∞–Ј—Л–≤–∞—О—В –і–Є—Б–њ–µ—В—З–µ—А–Њ–Љ). –°—Г—В—М –њ—А–Њ–±–ї–µ–Љ—Л –≤ —В–Њ–Љ, —З—В–Њ –Є–љ—В–µ–ї–Њ–≤—Б–Ї–Є–є –і–Є—Б–њ–µ—В—З–µ—А –њ—А–Њ–≤–µ—А—П–µ—В –љ–µ —В–Њ–ї—М–Ї–Њ –њ–Њ–і–і–µ—А–ґ–Ї—Г –љ–∞–±–Њ—А–Њ–≤ –Ї–Њ–Љ–∞–љ–і, –љ–Њ –Є —Б—В—А–Њ–Ї—Г —Б –љ–∞–Ј–≤–∞–љ–Є–µ–Љ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞. –Ш –≤ —Б–ї—Г—З–∞–µ, –µ—Б–ї–Є –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М —Г–Ї–∞–Ј–∞–љ –љ–µ –Ї–∞–Ї Intel, –і–Є—Б–њ–µ—В—З–µ—А –≤—Л–±–Є—А–∞–µ—В –Ї–Њ–і, –Њ–±–µ—Б–њ–µ—З–Є–≤–∞—О—Й–Є–є –Љ–∞–Ї—Б–Є–Љ–∞–ї—М–љ—Г—О —Б–Њ–≤–Љ–µ—Б—В–Є–Љ–Њ—Б—В—М –≤ —Г—Й–µ—А–± —Б–Ї–Њ—А–Њ—Б—В–Є вАФ –і–∞–ґ–µ –µ—Б–ї–Є –Ї–Њ–љ–Ї—А–µ—В–љ—Л–є –¶–Я –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ—В –≤—Б–µ –љ—Г–ґ–љ—Л–µ –Ї–Њ–Љ–∞–љ–і—Л.
–°–Є—В—Г–∞—Ж–Є—П –љ–µ –љ–Њ–≤–∞ –Є –њ—А–Њ–і–Њ–ї–ґ–∞–µ—В—Б—П –≥–Њ–і–∞–Љ–Є, –љ–Њ Intel –љ–Є—З–µ–≥–Њ –љ–µ –Љ–µ–љ—П–µ—В, —Е–Њ—В—П –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А—Л —Д–Є—А–Љ—Л –љ–µ —А–µ–Ї–ї–∞–Љ–Є—А—Г—О—В—Б—П –Ї–∞–Ї –Њ–њ—В–Є–Љ–∞–ї—М–љ–Њ —А–∞–±–Њ—В–∞—О—Й–Є–µ —В–Њ–ї—М–Ї–Њ –і–ї—П –µ—С —Б–Њ–±—Б—В–≤–µ–љ–љ—Л—Е –¶–Я. –Т —А–µ–Ј—Г–ї—М—В–∞—В–µ –њ—А–Њ–≥—А–∞–Љ–Љ–Є—Б—В –Є –љ–µ –њ–Њ–і–Њ–Ј—А–µ–≤–∞–µ—В, —З—В–Њ –Ј–∞—З–∞—Б—В—Г—О –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—М ¬Ђ–љ–µ–њ—А–∞–≤–Є–ї—М–љ—Л—Е –њ—А–Њ—Ж–µ—Б—Б–Њ—А–Њ–≤¬ї –љ–µ–і–Њ–њ–Њ–ї—Г—З–∞–µ—В –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є, –љ–Њ —Б—В–Њ–Є—В —В–Њ–ї—М–Ї–Њ —В–Њ–Љ—Г –њ–µ—А–µ—Б–µ—Б—В—М –љ–∞ –Њ–і–Њ–±—А–µ–љ–љ—Л–µ —Б–≤—Л—И–µ –¶–Я вАФ –Ї–∞–Ї –≤—Б—С —Б—А–∞–Ј—Г —Г—Б–Ї–Њ—А—П–µ—В—Б—П. –Х—Б–ї–Є –±—Л –Њ–± —Н—В–Њ–Љ –Ј–љ–∞–ї–Є –≤—Б–µ –њ—А–Њ–≥—А–∞–Љ–Љ–Є—Б—В—Л вАФ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ, –љ–µ–Ї–Њ—В–Њ—А—Л–µ –Є–Ј –љ–Є—Е —Б—В–∞–ї–Є –±—Л –Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞—В—М —Б–≤–Њ–Є –њ—А–Њ–≥—А–∞–Љ–Љ—Л –≤—А—Г—З–љ—Г—О –Є–ї–Є –њ–µ—А–µ—И–ї–Є –±—Л –љ–∞ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –і—А—Г–≥–Є—Е –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–Њ–≤ –Є –±–Є–±–ї–Є–Њ—В–µ–Ї. –С–Њ–ї–µ–µ —В–Њ–≥–Њ, Intel –Њ—В–Ї—А—Л—В–Њ –њ–Є—И–µ—В –≤ –і–Њ–Ї—Г–Љ–µ–љ—В–∞—Ж–Є–Є, —З—В–Њ –µ—Б–ї–Є –њ—А–Њ—Ж–µ—Б—Б–Њ—А –≤–Њ–Ј–≤—А–∞—Й–∞–µ—В –љ–∞–Ј–≤–∞–љ–Є–µ, –љ–µ —Б–Њ–≤–њ–∞–і–∞—О—Й–µ–µ —Б ¬ЂIntel¬ї, —В–Њ ¬Ђ–љ–µ —Б—В–Њ–Є—В –њ–Њ–ї–∞–≥–∞—В—М—Б—П –љ–∞ –і–∞–љ–љ—Г—О [–≤ —В–µ–Ї—Б—В–µ] –Є–љ—В–µ—А–њ—А–µ—В–∞—Ж–Є—О –Њ—Б—В–∞–ї—М–љ—Л—Е –њ–Њ–ї–µ–є¬ї, –≤–Ї–ї—О—З–∞—П —Б–њ–Є—Б–Њ–Ї –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ–Љ—Л—Е –љ–∞–±–Њ—А–Њ–≤ –Ї–Њ–Љ–∞–љ–і. –Т –≤—Л–њ—Г—Й–µ–љ–љ–Њ–є –≤ —П–љ–≤–∞—А–µ 2010 –≥. –Њ—Д–Є—Ж–Є–∞–ї—М–љ–Њ–є —Б—В–∞—В—М–µ –Њ–± –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–Є –±–Є–±–ї–Є–Њ—В–µ–Ї–Є Intel Performance Primitives –і–ї—П –¶–Я AMD –Њ—В–Љ–µ—З–µ–љ–Њ, —З—В–Њ –њ–Њ—Б–ї–µ–і–љ—П—П –≤–µ—А—Б–Є—П IPP —З–µ—Б—В–љ–Њ –Њ–њ—В–Є–Љ–Є–Ј–Є—А—Г–µ—В –Ї–Њ–і –Є —В—Г—В вАФ –љ–Њ –љ–µ —Г–Ї–∞–Ј–∞–љ–Њ, —З—В–Њ –≤ –љ–µ—Б–Ї–Њ–ї—М–Ї–Є—Е –і—А—Г–≥–Є—Е –±–Є–±–ї–Є–Њ—В–µ–Ї–∞—Е —Н—В–Њ –љ–µ –њ—А–Њ–Є—Б—Е–Њ–і–Є—В.
Intel —Б–њ–µ—Ж–Є–∞–ї—М–љ–Њ —Б—В–∞–≤–Є—В –љ–Є–Ј–Ї–Є–µ (–Є–љ–Њ–≥–і–∞ –і–∞–ґ–µ –љ—Г–ї–µ–≤—Л–µ) —Ж–µ–љ—Л –љ–∞ —Б–≤–Њ–Є –Є–љ—Б—В—А—Г–Љ–µ–љ—В—Л –і–ї—П –њ—А–Њ–≥—А–∞–Љ–Љ–Є—А–Њ–≤–∞–љ–Є—П, –∞ –њ–Њ–і–і–µ—А–ґ–Ї—Г –Є–Љ –і–∞—С—В –љ–∞ –≤—Л—Б–Њ–Ї–Њ–Љ —Г—А–Њ–≤–љ–µ. –Ґ. –µ. —Б–∞–Љ–∞ –њ–Њ —Б–µ–±–µ –њ—А–Њ–і–∞–ґ–∞ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–Њ–≤, —Б–Ї–Њ—А–µ–µ –≤—Б–µ–≥–Њ, —Г–±—Л—В–Њ—З–љ–∞, –љ–Њ –Њ–љ–∞ —Г–ї—Г—З—И–∞–µ—В –њ—А–Њ–і–∞–ґ–Є –¶–Я. –Ф–Њ–±–∞–≤–ї—П—В—М –љ–Њ–≤—Л–µ –Ї–Њ–Љ–∞–љ–і—Л –≤ –њ—А–Њ—Ж–µ—Б—Б–Њ—А –±–µ–Ј –њ–Њ–і–і–µ—А–ґ–Ї–Є –љ–∞ —Г—А–Њ–≤–љ–µ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–Њ–≤ –њ–Њ—З—В–Є –±–µ—Б—Б–Љ—Л—Б–ї–µ–љ–љ–Њ вАФ –Ї–Њ–і–Є—А—Г—О—В –љ–∞ –∞—Б—Б–µ–Љ–±–ї–µ—А–µ —Б–µ–≥–Њ–і–љ—П –Ї—А–∞–є–љ–µ —А–µ–і–Ї–Њ. –І—В–Њ –Ї–∞—Б–∞–µ—В—Б—П AMD вАФ –Њ–љ–∞ —В–∞–Ї–ґ–µ –і–µ–ї–∞–µ—В —Б–≤–Њ–є –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А Open64, –љ–Њ —В–Њ–ї—М–Ї–Њ –і–ї—П Linux.
–£ –≤—Б–µ—Е –љ–∞ —Б–ї—Г—Е—Г ¬Ђ–њ–Њ–ї—О–±–Њ–≤–љ–Њ–µ¬ї —Б–Њ–≥–ї–∞—И–µ–љ–Є–µ –Љ–µ–ґ–і—Г Intel –Є AMD –≤ –љ–Њ—П–±—А–µ 2009 –≥., —Г–ї–∞–ґ–Є–≤–∞—О—Й–µ–µ –Є—Б–Ї –њ–Њ—Б–ї–µ–і–љ–µ–є, –Ј–∞ —З—В–Њ Intel –≤—Л–њ–ї–∞—В–Є–ї–∞ –Ї—А—Г–≥–ї—Г—О —Б—Г–Љ–Љ—Г. –Ь–µ–љ–µ–µ –Є–Ј–≤–µ—Б—В–љ–Њ, —З—В–Њ AMD —В–∞–Ї–ґ–µ –њ–Њ—В—А–µ–±–Њ–≤–∞–ї–∞ –њ–Њ–і–њ–Є—Б–∞—В—М —Б–Њ–≥–ї–∞—И–µ–љ–Є–µ –Њ–± —Г—А–µ–≥—Г–ї–Є—А–Њ–≤–∞–љ–Є–Є, –≥–і–µ –њ–µ—А–µ—З–Є—Б–ї–µ–љ—Л –Љ–љ–Њ–≥–Є–µ –љ–µ—З–µ—Б—В–љ—Л–µ –њ—А–Є—С–Љ—Л –Ї–Њ–љ–Ї—Г—А–µ–љ—Ж–Є–Є, –Ї–Њ—В–Њ—А—Л–µ Intel –Њ–±–µ—Й–∞–µ—В –±–Њ–ї–µ–µ –љ–µ –њ—А–Є–Љ–µ–љ—П—В—М вАФ —Б—А–µ–і–Є –љ–Є—Е –Є ¬Ђ–њ–Њ–і–Љ–µ–љ–∞ –¶–Я¬ї. –Ф–Њ–Ї—Г–Љ–µ–љ—В –Њ–±—П–Ј—Л–≤–∞–µ—В Intel —Б–Љ–µ–љ–Є—В—М –Ї–Њ–і –і–Є—Б–њ–µ—В—З–µ—А–∞ –љ–∞ –љ–µ–є—В—А–∞–ї—М–љ—Л–є вАФ –љ–∞–і–Њ –њ–Њ–ї–∞–≥–∞—В—М, —Б–Њ —Б–ї–µ–і—Г—О—Й–µ–є –≤–µ—А—Б–Є–Є –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–∞вА¶ –І–µ—А–µ–Ј –Љ–µ—Б—П—Ж –§–µ–і–µ—А–∞–ї—М–љ–∞—П –Ґ–Њ—А–≥–Њ–≤–∞—П –Ъ–Њ–Љ–Є—Б—Б–Є—П –°–®–Р (FTC) –њ–Њ–і–∞–ї–∞ –∞–љ—В–Є–Љ–Њ–љ–Њ–њ–Њ–ї—М–љ—Г—О –ґ–∞–ї–Њ–±—Г –њ—А–Њ—В–Є–≤ Intel —Б —А–µ–Ј–Ї–Є–Љ–Є –Њ–±–≤–Є–љ–µ–љ–Є—П–Љ–Є –љ–∞ —В–Њ–є –ґ–µ –њ–Њ—З–≤–µ –њ–Њ–і–Љ–µ–љ—Л –њ—Г—В–µ–є –Ї–Њ–і–∞, –і–∞–ґ–µ –≤–≤–µ–і—П —Б–Њ–±—Б—В–≤–µ–љ–љ—Л–є —В–µ—А–Љ–Є–љ ¬ЂDefective compiler¬ї –і–ї—П –Њ–њ–Є—Б–∞–љ–Є—П —В–≤–Њ—А–µ–љ–Є—П Intel. FTC —В—А–µ–±—Г–µ—В, —З—В–Њ–±—Л Intel –±–µ—Б–њ–ї–∞—В–љ–Њ –≤—Л–њ—Г—Б—В–Є–ї–∞ –Ј–∞–Љ–µ–љ—Г —В–µ–Ї—Г—Й–µ–Љ—Г –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А—Г –Є–ї–Є –Ј–∞–њ–ї–∞—В–Ї—Г –Ї –µ–≥–Њ ¬Ђ–і–µ—Д–µ–Ї—В–∞–Љ¬ї, —Б–Ї–Њ–Љ–њ–µ–љ—Б–Є—А–Њ–≤–∞–ї–∞ —Б—В–Њ–Є–Љ–Њ—Б—В—М –њ–µ—А–µ–Ї–Њ–Љ–њ–Є–ї—П—Ж–Є–Є –Є —А–∞—Б–њ—А–Њ—Б—В—А–∞–љ–µ–љ–Є—П –Є—Б–њ—А–∞–≤–ї–µ–љ–љ—Л—Е –љ–Њ–≤—Л–Љ –Є–љ—Б—В—А—Г–Љ–µ–љ—В–Њ–Љ –≤–µ—А—Б–Є–є –њ—А–Њ–≥—А–∞–Љ–Љ –Є –Њ–±—К—П–≤–Є–ї–∞ –њ–Њ—В—А–µ–±–Є—В–µ–ї—П–Љ –Њ –Ј–∞–Љ–µ–љ–µ —Б—В–∞—А—Л—Е –≤–µ—А—Б–Є–є –љ–∞ –љ–Њ–≤—Л–µ.
–Я–Њ–Ї–∞ —И–ї–Є –њ—А–µ–љ–Є—П, –њ—А–Њ—И—С–ї –≥–Њ–і, Intel –≤—Л–њ—Г—Б—В–Є–ї–∞ –љ–Њ–≤—Г—О –≤–µ—А—Б–Є—О —Б–≤–Њ–µ–є –њ–Њ–њ—Г–ї—П—А–љ–Њ–є –±–Є–±–ї–Є–Њ—В–µ–Ї–Є MKL (Math Kernel Library) v10.3 вАФ –∞ –і–Є—Б–њ–µ—В—З–µ—А –¶–Я –њ—А–∞–Ї—В–Є—З–µ—Б–Ї–Є –љ–µ –њ–Њ–Љ–µ–љ—П–ї—Б—П. –°–Ї–∞–ї—П—А–љ—Л–µ, –≤–µ–Ї—В–Њ—А–љ—Л–µ –Є 64-–±–Є—В–љ—Л–µ –≤–µ—А—Б–Є–Є —Д—Г–љ–Ї—Ж–Є–є –≤—Б—С –µ—Й—С –Є—Б–њ–Њ–ї—М–Ј—Г—О—В –љ–µ–Њ–њ—В–Є–Љ–Є–Ј–Є—А–Њ–≤–∞–љ–љ—Л–µ –њ—Г—В–Є –љ–∞ ¬Ђ–љ–µ–Ї–Њ—И–µ—А–љ—Л—Е¬ї –¶–Я. –С–Њ–ї–µ–µ —В–Њ–≥–Њ, –Љ–љ–Њ–≥–Є–µ —Д—Г–љ–Ї—Ж–Є–Є —В–µ–њ–µ—А—М –Є–Љ–µ—О—В –љ–Њ–≤—Г—О –≤–µ—В–Ї—Г –і–ї—П –≥—А—П–і—Г—Й–µ–≥–Њ –љ–∞–±–Њ—А–∞ AVX вАФ –Є —В–Њ–ґ–µ —В–Њ–ї—М–Ї–Њ –і–ї—П Intel. –Ґ. –µ. –≤ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞—Е Sandy Bridge —В–∞–Ї–Њ–є –Ї–Њ–і —А–∞–±–Њ—В–∞—В—М –±—Г–і–µ—В, –∞ –≤ AMD Bulldozer, –≤—Л—Е–Њ–і—П—Й–Є—Е –≤ —Н—В–Њ –ґ–µ –≤—А–µ–Љ—П –Є —В–∞–Ї–ґ–µ –≥–Њ—В–Њ–≤—Л—Е –Є—Б–њ–Њ–ї–љ—П—В—М AVX, вАФ –љ–µ—В. –Т–њ—А–Њ—З–µ–Љ, –њ–Њ—П–≤–Є–ї–∞—Б—М –љ–Њ–≤–∞—П –≤–µ—В–≤—М —Б–њ–µ—Ж–Є–∞–ї—М–љ–Њ –і–ї—П –љ–µ-–Є–љ—В–µ–ї–Њ–≤—Б–Ї–Є—Е –¶–Я —Б SSE2 вАФ –Є –і–ї—П –Љ–љ–Њ–≥–Є—Е —Д—Г–љ–Ї—Ж–Є–є –Њ–љ–∞ —А–∞–±–Њ—В–∞–µ—В –Љ–µ–і–ї–µ–љ–љ–µ–µ, —З–µ–Љ SSE2-–Ї–Њ–і –і–ї—П Intel. –Я—А–Є—З—С–Љ —Н—В–∞ –≤–µ—В–≤—М —Б—Г—Й–µ—Б—В–≤—Г–µ—В –ї–Є—И—М –≤ 32-–±–Є—В–љ—Л—Е –≤–µ—А—Б–Є—П—Е MKL.–°–Љ–µ–ї—Л–є —А—Л—Ж–∞—А—М
–І–Є—В–∞—В–µ–ї—М —Б–њ—А–Њ—Б–Є—В вАФ –∞ –Њ—В–Ї—Г–і–∞ –≤—Б—С —Н—В–Њ –Є–Ј–≤–µ—Б—В–љ–Њ? –Ґ—Г—В –љ–∞ —Б—Ж–µ–љ—Г –≤—Л—Е–Њ–і–Є—В –Њ–њ—Л—В–љ—Л–є –њ—А–Њ–≥—А–∞–Љ–Љ–Є—Б—В –Є –Є—Б—Б–ї–µ–і–Њ–≤–∞—В–µ–ї—М –Р–≥–љ–µ—А –§–Њ–≥ (Agner Fog), –Є–Ј–≤–µ—Б—В–љ—Л–є –≤ –°–µ—В–Є —Б–≤–Њ–Є–Љ–Є —Г—З–µ–±–љ–Є–Ї–∞–Љ–Є –њ–Њ –Њ–њ—В–Є–Љ–Є–Ј–∞—Ж–Є–Є –Є –Љ–Є–Ї—А–Њ–∞—А—Е–Є—В–µ–Ї—В—Г—А–∞–Љ, –±–µ—Б–њ–ї–∞—В–љ–Њ –≤—Л–ї–Њ–ґ–µ–љ–љ—Л–Љ–Є –љ–∞ –µ–≥–Њ —Б–∞–є—В–µ. –Т 2007 –≥. –§–Њ–≥ –Њ–Ј–љ–∞–Ї–Њ–Љ–Є–ї Intel —Б —А–µ–Ј—Г–ї—М—В–∞—В–∞–Љ–Є —Б–≤–Њ–Є—Е –Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є–є –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–Њ–≤ —Б –≤—Л—И–µ—Г–Ї–∞–Ј–∞–љ–љ—Л–Љ–Є –≤—Л–≤–Њ–і–∞–Љ–Є. –Я–Њ—Б–ї–µ–і–Њ–≤–∞–ї–∞ –і–Њ–ї–≥–∞—П –њ–µ—А–µ–њ–Є—Б–Ї–∞, –≤ –Ї–Њ—В–Њ—А–Њ–є –Ї–Њ–Љ–њ–∞–љ–Є—П –Њ—В—А–Є—Ж–∞–ї–∞ –љ–∞–ї–Є—З–Є–µ –њ—А–Њ–±–ї–µ–Љ—Л, —Е–Њ—В—П –§–Њ–≥ –њ—А–Њ–і–Њ–ї–ґ–∞–ї –∞—А–≥—Г–Љ–µ–љ—В–Є—А–Њ–≤–∞–љ–љ–Њ –њ–Њ–і—В–≤–µ—А–ґ–і–∞—В—М –µ—С –љ–∞–ї–Є—З–Є–µ. –Ф—А—Г–≥–Є–µ —Б–њ–µ—Ж–Є–∞–ї–Є—Б—В—Л —В–∞–Ї–ґ–µ –ґ–∞–ї–Њ–≤–∞–ї–Є—Б—М –љ–∞ —В–µ –ґ–µ –њ—А–Њ–±–ї–µ–Љ—Л –Є –њ–Њ–ї—Г—З–Є–ї–Є –њ–Њ—Е–Њ–ґ–Є–µ –Њ—В–≤–µ—В—Л. –°–Є—В—Г–∞—Ж–Є—П —Б –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–Њ–Љ –љ–µ –Є–Ј–Љ–µ–љ–Є–ї–∞—Б—М –і–∞–ґ–µ –≤ –≤–µ—А—Б–Є–Є 11.1.054, –≤—Л—И–µ–і—И–µ–є —Б—А–∞–Ј—Г –њ–Њ—Б–ї–µ –њ–Њ–і–њ–Є—Б–∞–љ–Є—П —Б–Њ–≥–ї–∞—И–µ–љ–Є—П —Б AMD.
–Ъ–∞–Ї –љ–Є —Б—В—А–∞–љ–љ–Њ, Intel –Ј–∞—П–≤–Є–ї–∞ –≤ –њ–µ—А–µ–њ–Є—Б–Ї–µ, —З—В–Њ –љ–∞–Љ–µ—А–µ–љ–љ–Њ –Њ–њ—В–Є–Љ–Є–Ј–Є—А—Г–µ—В –љ–µ –њ–Њ–і –љ–∞–±–Њ—А—Л –Ї–Њ–Љ–∞–љ–і, –∞ –њ–Њ–і –Ї–Њ–љ–Ї—А–µ—В–љ—Л–µ –∞—А—Е–Є—В–µ–Ї—В—Г—А—Л –¶–Я, —З—В–Њ–±—Л –Њ–њ—В–Є–Љ–Є–Ј–∞—Ж–Є—П –±—Л–ї–∞ –ї—Г—З—И–µ, —З—В–Њ —П–Ї–Њ–±—Л –Њ—В–Ї–ї–Њ–љ—П–µ—В –Њ–±–≤–Є–љ–µ–љ–Є—П –≤ –љ–µ—З–µ—Б—В–љ–Њ—Б—В–Є (–≥–ї—Г–њ–Њ —В—А–µ–±–Њ–≤–∞—В—М –Њ–њ—В–Є–Љ–Є–Ј–∞—Ж–Є–Є –њ–Њ–і —З—Г–ґ–Є–µ –¶–Я). –Э–Њ —Н—В–Њ —В–∞–Ї–ґ–µ –Њ–Ј–љ–∞—З–∞–µ—В, —З—В–Њ –≤—Л—Е–Њ–і –Њ—З–µ—А–µ–і–љ–Њ–≥–Њ –љ–Њ–≤–Њ–≥–Њ –¶–Я —Б–∞–Љ–Њ́–є Intel, –і–∞–ґ–µ –µ—Б–ї–Є –Њ–љ –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–µ—В —В–µ –ґ–µ –Ї–Њ–Љ–∞–љ–і—Л, —З—В–Њ –Є —Б—В–∞—А—Л–є, –њ–Њ—В—А–µ–±—Г–µ—В –њ–µ—А–µ–Ї–Њ–Љ–њ–Є–ї—П—Ж–Є–Є –њ—А–Њ–≥—А–∞–Љ–Љ –љ–Њ–≤–Њ–є –≤–µ—А—Б–Є–µ–є –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–∞, –Є–љ–∞—З–µ —Б—В–∞—А—Л–є –і–Є—Б–њ–µ—В—З–µ—А, –Ј–∞–њ—Г—Й–µ–љ–љ—Л–є –љ–∞ –љ–Њ–≤–Њ–Љ –¶–Я, –љ–µ —Г–Ј–љ–∞́–µ—В –і–∞–ґ–µ —А–Њ–і–љ–Њ–≥–Њ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—П. –≠—В–Њ –µ—Б–ї–Є Intel –љ–µ –ї—Г–Ї–∞–≤–Є—ВвА¶ –§–Њ–≥ —А–µ—И–Є–ї –њ—А–Њ–≤–µ—А–Є—В—М –Є –Ј–∞–њ—Г—Б—В–Є–ї –њ—А–Њ–≥—А–∞–Љ–Љ—Г, —Б–і–µ–ї–∞–љ–љ—Г—О —Б—В–∞—А–Њ–є –≤–µ—А—Б–Є–µ–є –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–∞ Intel, –љ–∞ –љ–Њ–≤–Њ–Љ, —П–Ї–Њ–±—Л –љ–µ–Є–Ј–≤–µ—Б—В–љ–Њ–Љ —В–Њ–Љ—Г –¶–Я —В–Њ–є –ґ–µ Intel. –Ъ–∞–Ї –Є —Б–ї–µ–і–Њ–≤–∞–ї–Њ –Њ–ґ–Є–і–∞—В—М, –≤—Б—С –Ј–∞—А–∞–±–Њ—В–∞–ї–Њ –Є–і–µ–∞–ї—М–љ–Њ. –Я—А–Є—З–Є–љ–∞ вАФ Intel —Е–Є—В—А–Њ –Љ–∞–љ–Є–њ—Г–ї–Є—А—Г–µ—В —Ж–Є—Д—А–∞–Љ–Є ¬Ђ—Б–µ–Љ–µ–є—Б—В–≤–∞¬ї –љ–∞ –љ–Њ–≤—Л—Е –¶–Я —В–∞–Ї, —З—В–Њ–±—Л –Њ–љ–Є –≤—Л–≥–ї—П–і–µ–ї–Є –Ј–љ–∞–Ї–Њ–Љ–Њ –і–ї—П —Б—В–∞—А—Л—Е –њ—А–Њ–≥—А–∞–Љ–Љ, –≤ —З–∞—Б—В–љ–Њ—Б—В–Є, –і–Њ–±–∞–≤–Є–≤ ¬Ђ—А–∞—Б—И–Є—А–µ–љ–љ–Њ–µ —Б–µ–Љ–µ–є—Б—В–≤–Њ¬ї –Є ¬Ђ—А–∞—Б—И–Є—А–µ–љ–љ—Г—О –Љ–Њ–і–µ–ї—М¬ї.
–Я–Њ—Б–ї–µ —В–Њ–≥–Њ, –Ї–∞–Ї Intel –Њ—В–Ї–∞–Ј–∞–ї–∞—Б—М –Ї–∞–Ї-–ї–Є–±–Њ —А–µ—И–∞—В—М –њ—А–Њ–±–ї–µ–Љ—Г, –§–Њ–≥ —А–µ—И–Є–ї, —З—В–Њ –ї—Г—З—И–∞—П —В–∞–Ї—В–Є–Ї–∞ вАФ –њ—Г–±–ї–Є—З–љ–Њ—Б—В—М. –Э–Њ —Б–≤—П–Ј–∞–≤—И–Є—Б—М —Б –љ–µ—Б–Ї–Њ–ї—М–Ї–Є–Љ–Є IT-–ґ—Г—А–љ–∞–ї–∞–Љ–Є, –Њ–љ –љ–Є–Ї–Њ–≥–Њ –љ–µ –Ј–∞–Є–љ—В–µ—А–µ—Б–Њ–≤–∞–ї. –Ы—О–±–Є—В–µ–ї–Є –Ї–Њ–љ—Б–њ–Є—А–Њ–ї–Њ–≥–Є–Є, –Ї–Њ–љ–µ—З–љ–Њ, –љ–µ–Љ–µ–і–ї–µ–љ–љ–Њ –њ–Њ—Б—В—А–Њ—П—В —Б—В—А–Њ–є–љ—Г—О —В–µ–Њ—А–Є—О –Њ —В–Њ–Љ, –Ї–∞–Ї —Б–∞–Љ–Є –Ј–љ–∞–µ—В–µ –Ї—В–Њ –њ–Њ–і–Ї—Г–њ–Є–ї —Б–∞–Љ–Є –Ј–љ–∞–µ—В–µ –Ї–Њ–≥–Њ вАФ –љ–Њ –Є—Б—В–Є–љ–∞, –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ, –Ї—Г–і–∞ –±–∞–љ–∞–ї—М–љ–µ–µ: —Б–ї–Є—И–Ї–Њ–Љ —Г–ґ —Г–Ј–Ї–Њ—Б–њ–µ—Ж–Є–∞–ї—М–љ–∞—П —В–µ–Љ–∞ –і–ї—П —Б—А–µ–і–љ–µ—Б—В–∞—В–Є—Б—В–Є—З–µ—Б–Ї–Њ–≥–Њ —З–Є—В–∞—В–µ–ї—П. –Э–Њ —В–Њ —З–Є—В–∞—В–µ–ї–Є, –∞ –≤–Њ—В –њ–Њ—З–µ–Љ—Г AMD, –Ї–Њ–Љ–Љ–µ—А—З–µ—Б–Ї–Є —Б—В—А–∞–і–∞—О—Й–∞—П –Њ—В —Н—В–Њ–є —Б–Є—В—Г–∞—Ж–Є–Є –±–Њ–ї—М—И–µ –≤—Б–µ–≥–Њ, –і–Њ —Б–Є—Е –њ–Њ—А –Љ–Њ–ї—З–Є—В –і–∞–ґ–µ —Г —Б–µ–±—П –љ–∞ —Б–∞–є—В–µ? –Ь–Њ–ґ–µ—В –±—Л—В—М, –Њ–љ–∞ —А–µ—И–Є–ї–∞, —З—В–Њ —Н—В–Њ –Ї–∞–Ї-—В–Њ –њ–Њ–≤—А–µ–і–Є—В —Г—В—А—П—Б–Ї–µ –Є—Б–Ї–∞ –њ—А–Њ—В–Є–≤ Intel? –Р VIA/Centaur?..
–Ґ–µ–Љ –≤—А–µ–Љ–µ–љ–µ–Љ, –§–Њ–≥ –њ—А–Њ–і–Њ–ї–ґ–∞–ї –±–Њ–Љ–±–Є—В—М —Д–∞–Ї—В–∞–Љ–Є (—Б—Б—Л–ї–Ї–Є –µ—Б—В—М –≤ –µ–≥–Њ –±–ї–Њ–≥–µ). –Э–∞–њ—А–Є–Љ–µ—А, —Б–Њ–≥–ї–∞—Б–љ–Њ —Б–∞–є—В—Г CNET, Skype –љ–∞ –љ–µ–Ї–Њ—В–Њ—А–Њ–µ –≤—А–µ–Љ—П –і–Њ–≥–Њ–≤–Њ—А–Є–ї—Б—П —Б Intel –Њ–≥—А–∞–љ–Є—З–Є—В—М —Д—Г–љ–Ї—Ж–Є–Њ–љ–∞–ї—М–љ–Њ—Б—В—М —Б–≤–Њ–µ–є –њ—А–Њ–≥—А–∞–Љ–Љ—Л –љ–∞ –Ї–Њ–Љ–њ—М—О—В–µ—А–∞—Е —Б –∞–ї—М—В–µ—А–љ–∞—В–Є–≤–љ—Л–Љ–Є –¶–Я, –љ–Њ –њ–Њ–Ј–ґ–µ –Њ–≥—А–∞–љ–Є—З–µ–љ–Є–µ –±—Л–ї–Њ —Б–љ—П—В–ЊвА¶ –Т –Њ–±—Й–µ–Љ, –Ї—В–Њ –≤–Є–љ–Њ–≤–∞—В вАФ —П—Б–љ–Њ, —В–µ–њ–µ—А—М вАФ —З—В–Њ –і–µ–ї–∞—В—М? –§–Њ–≥ –њ—А–µ–і–ї–∞–≥–∞–µ—В —В—А–Є –≤–∞—А–Є–∞–љ—В–∞:
- –Э–µ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А Intel. –Ъ–Њ–Љ–њ–Є–ї—П—В–Њ—А GNU –њ–Њ–і Linux –Њ–њ—В–Є–Љ–Є–Ј–Є—А—Г–µ—В –љ–µ —Е—Г–ґ–µ, —З–µ–Љ Intel, –љ–Њ —Д—Г–љ–Ї—Ж–Є–Њ–љ–∞–ї—М–љ–∞—П –±–Є–±–ї–Є–Њ—В–µ–Ї–∞ glibc –љ–µ—Б–Ї–Њ–ї—М–Ї–Њ –љ–µ–і–Њ—А–∞–±–Њ—В–∞–љ–∞. –І—В–Њ –Ї–∞—Б–∞–µ—В—Б—П –Є–љ—Б—В—А—Г–Љ–µ–љ—В–Њ–≤ –і–ї—П Windows вАФ —В—Г—В –љ–Є–Ї–∞–Ї–Є—Е –∞–ї—М—В–µ—А–љ–∞—В–Є–≤ –љ–µ—В.
- –Ш—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А Intel, –≤—А—Г—З–љ—Г—О —А–µ–і–∞–Ї—В–Є—А—Г—П –і–Є—Б–њ–µ—В—З–µ—А. –Т —Г—З–µ–±–љ–Є–Ї–µ –њ–Њ C++ –§–Њ–≥ –њ—А–µ–і–Њ—Б—В–∞–≤–Є–ї ¬Ђ—З–µ—Б—В–љ—Л–є¬ї –Ї–Њ–і –Є –Є–љ—Б—В—А—Г–Ї—Ж–Є–Є –њ–Њ –≤—Б—В—А–∞–Є–≤–∞–љ–Є—О –µ–≥–Њ –≤ –њ—А–Њ–≥—А–∞–Љ–Љ—Л вАФ –Њ–і–љ–∞–Ї–Њ –і–∞–љ–љ—Л–є —Б–њ–Њ—Б–Њ–± –Ј–∞–≤—П–Ј–∞–љ –љ–∞ –љ–µ–і–Њ–Ї—Г–Љ–µ–љ—В–Є—А–Њ–≤–∞–љ–љ—Л—Е –Њ—Б–Њ–±–µ–љ–љ–Њ—Б—В—П—Е –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–Њ–≤ Intel, –Ї–Њ—В–Њ—А—Л–µ –Љ–µ–љ—П—О—В—Б—П –Њ—В –≤–µ—А—Б–Є–Є –Ї –≤–µ—А—Б–Є–Є.
- –°–Љ–µ–љ–Є—В—М –≤ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–µ –≤–Њ–Ј–≤—А–∞—Й–∞–µ–Љ—Г—О —Б—В—А–Њ–Ї—Г –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—П —Б –њ–Њ–Љ–Њ—Й—М—О –Ї–Њ–Љ–∞–љ–і –≤–Є—А—В—Г–∞–ї–Є–Ј–∞—Ж–Є–Є. –Ш–Ј–≤–µ—Б—В–љ–Њ, —З—В–Њ –≤–µ—А—Б–Є—П AMD —Н—В–Њ–є —В–µ—Е–љ–Њ–ї–Њ–≥–Є–Є –Є–Љ–µ–µ—В —В–∞–Ї—Г—О –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М, —З—В–Њ –±—Л–ї–Њ –њ—А–Њ–і–µ–Љ–Њ–љ—Б—В—А–Є—А–Њ–≤–∞–љ–Њ –љ–∞ –љ–µ–±–Њ–ї—М—И–Њ–Љ –њ—А–Є–Љ–µ—А–µ вАФ –љ–Њ –і–Њ —Б–Є—Е –њ–Њ—А –љ–Є–Ї—В–Њ –љ–µ –≤–Ј—П–ї—Б—П —Б–і–µ–ї–∞—В—М –њ–Њ–ї–љ–Њ—Ж–µ–љ–љ—Г—О –њ—А–Њ–≥—А–∞–Љ–Љ—Г –і–ї—П –њ–Њ–і–Љ–µ–љ—Л. –≠—В–Њ—В —Б–њ–Њ—Б–Њ–± —Е–Њ—А–Њ—И —В–µ–Љ, —З—В–Њ –µ–≥–Њ –Љ–Њ–≥—Г—В –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –≤ —В. —З. –Є –Ї–Њ–љ–µ—З–љ—Л–µ –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї–Є, –љ–µ –Є–Љ–µ—О—Й–Є–µ –і–Њ—Б—В—Г–њ–∞ –Ї –Є—Б—Е–Њ–і–љ—Л–Љ –Ї–Њ–і–∞–Љ вАФ –∞ —В–∞–Ї–ґ–µ –ґ—Г—А–љ–∞–ї–Є—Б—В—Л, —Б—В—А–∞—Б—В–љ–Њ –ґ–µ–ї–∞—О—Й–Є–µ –љ–∞–њ–Є—Б–∞—В—М —Б–µ–љ—Б–∞—Ж–Є–Њ–љ–љ–Њ-—А–∞–Ј–≥—А–Њ–Љ–љ—Г—О —Б—В–∞—В—М—О. :)
–Ъ–∞–Ї –љ–Є —Б—В—А–∞–љ–љ–Њ, —А–∞–љ—М—И–µ –≤—Б–µ—Е –ї–Њ–њ–љ—Г–ї–Њ —В–µ—А–њ–µ–љ–Є–µ —Г VIA Technologies. –Ф–µ–ї–Њ –≤ —В–Њ–Љ, —З—В–Њ –≤—Б–µ 64-–±–Є—В–љ—Л–µ Windows (–≤–њ–ї–Њ—В—М –і–Њ Win 7 v6.1), –∞ —В–∞–Ї–ґ–µ FreeBSD –Ј–∞–≥—А—Г–ґ–∞—О—В—Б—П —В–Њ–ї—М–Ї–Њ –љ–∞ –¶–Я –Є–Ј–≤–µ—Б—В–љ—Л—Е –Є–Љ –Ї–Њ–Љ–њ–∞–љ–Є–є. –Ф–Њ –њ–Њ—А—Л –і–Њ –≤—А–µ–Љ–µ–љ–Є —Н—В–Њ –±—Л–ї–Є –ї–Є—И—М AMD –Є Intel, –Є —В–Њ–ї—М–Ї–Њ –љ–∞—З–Є–љ–∞—П —Б Vista SP2 –≤ —Б–њ–Є—Б–Њ–Ї –і–Њ–±–∞–≤–Є–ї–Є –Є VIA. –Э–Њ –њ–Њ–Ї–∞ —В–∞–є–≤–∞–љ—М—Б–Ї–∞—П —Д–Є—А–Љ–∞ –љ–µ –±—Л–ї–∞ –і–Њ–њ—Г—Й–µ–љ–∞ –≤ –Ї–∞—Б—В—Г –Є–Ј–±—А–∞–љ–љ—Л—Е (—З—В–Њ, –≤–Њ–Њ–±—Й–µ –≥–Њ–≤–Њ—А—П, –µ—Б—В—М –њ–Њ–≤–Њ–і –і–ї—П –Є—Б–Ї–∞ –≤ —Б—Г–і —Б –Њ–±–≤–Є–љ–µ–љ–Є–µ–Љ –≤ –Ї–∞—А—В–µ–ї—М–љ–Њ–Љ —Б–≥–Њ–≤–Њ—А–µ —Б ¬Ђ–Є–Ј–±—А–∞–љ–љ—Л–Љ–Є¬ї), –≤ VIA –љ–µ —Б–Є–і–µ–ї–Є —Б–ї–Њ–ґ–∞ —А—Г–Ї–Є –Є —А–µ—И–Є–ї–Є, —З—В–Њ –µ—Б–ї–Є –≥–Њ—А–∞ Microsoft –љ–µ –Є–і—С—В –Ї VIA, —В–Њ VIA –њ–Њ–є–і—С—В –Ї –≥–Њ—А–µ: –≤ –љ–Њ–≤—Л–є –¶–Я VIA Nano –і–Њ–±–∞–≤–ї–µ–љ–∞ —Д—Г–љ–Ї—Ж–Є—П —Б–Љ–µ–љ—Л –Є–Љ–µ–љ–Є –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—П, –∞ –Ј–∞–Њ–і–љ–Њ –Є –і—А—Г–≥–Є—Е –Њ–њ–Њ–Ј–љ–∞–≤–∞—В–µ–ї—М–љ—Л—Е —Ж–Є—Д—А (–Ї–∞–Ї —Н—В–Њ –≤—Л–≥–ї—П–і–Є—В вАФ –њ–Њ–Ї–∞–ґ–µ–Љ –љ–Є–ґ–µ). –°—В—А–Њ–≥–Њ –≥–Њ–≤–Њ—А—П, —Н—В–∞ —Д—Г–љ–Ї—Ж–Є—П –±—Л–ї–∞ —В–∞–є–Ї–Њ–Љ –Ј–∞—П–≤–ї–µ–љ–∞ –µ—Й—С –і–ї—П C3 (—П–і—А–Њ Nehemiah, –≤—Л—И–µ–і—И–µ–µ –Ї–∞–Ї —А–∞–Ј –њ—А–Є –њ–Њ—П–≤–ї–µ–љ–Є–Є –њ–µ—А–≤—Л—Е 64-–±–Є—В–љ—Л—Е –Ю–° –і–ї—П –Я–Ъ –≤ 2003 –≥., —З—В–Њ –њ–Њ–Ї–∞–Ј—Л–≤–∞–µ—В –Ј–∞–њ—Г—Й–µ–љ–љ–Њ—Б—В—М –њ—А–Њ–±–ї–µ–Љ—Л), –љ–Њ —В–Њ –ї–Є –љ–Є–Ї—В–Њ –љ–µ —Г–і–Њ—Б—Г–ґ–Є–ї—Б—П –њ—А–Њ–≤–µ—А–Є—В—М, —В–Њ –ї–Є –і–∞–љ–љ—Л–µ –±—Л–ї–Є –љ–µ–≤–µ—А–љ—Л, –љ–Њ —Б–µ–љ—Б–∞—Ж–Є–Є –љ–µ –њ–Њ–ї—Г—З–Є–ї–Њ—Б—М.
–Т–њ—А–Њ—З–µ–Љ, —Г–ґ–µ –і–∞–≤–љ–Њ –≤—Л—Б–Ї–∞–Ј—Л–≤–∞–ї–Є—Б—М –њ–Њ–і–Њ–Ј—А–µ–љ–Є—П, —З—В–Њ —Б—А–µ–і–Є –њ—А–Њ—З–Є—Е –њ—А–Њ–≥—А–∞–Љ–Љ –њ–Њ—Б—В—А–∞–і–∞–ї–Є –Њ—В –і–Є—Б–њ–µ—В—З–µ—А—Б–Ї–Њ–є ¬Ђ–Ј–∞–Ї–ї–∞–і–Ї–Є¬ї –Є –±–µ–љ—З–Љ–∞—А–Ї–Є вАФ –∞ –Є—Е –Ј–∞–Љ–µ—А—Л –њ–Њ—В–Њ–Љ –њ–Њ–њ–∞–і–∞—О—В –≤ –Њ–±–Ј–Њ—А—Л –љ–∞ —Б–∞–є—В–∞—Е, –њ–Њ –Ї–Њ—В–Њ—А—Л–Љ –њ–Њ—В–µ–љ—Ж–Є–∞–ї—М–љ—Л–µ –њ–Њ–Ї—Г–њ–∞—В–µ–ї–Є —А–µ—И–∞—О—В, —З—В–Њ́ –Є–Љ –Ї—Г–њ–Є—В—М. –Ш –≤–Њ—В –Њ–і–Є–љ –Є–Ј –і–Њ–Ї–∞–Ј–∞–љ–љ—Л—Е –њ—А–Є–Љ–µ—А–Њ–≤ –Ї–∞–Ї —А–∞–Ј —Г—Й–µ–Љ–ї—П–µ—В –њ—А–∞–≤–∞ VIA вАФ Futuremark PCMark 2005 (–њ—А–µ–і—И–µ—Б—В–≤–µ–љ–љ–Є–Ї PCMark Vantage) –і–ї—П —В–µ—Б—В–∞ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є –њ–∞–Љ—П—В–Є –Є—Б–њ–Њ–ї—М–Ј—Г–µ—В –Њ–њ—В–Є–Љ–Є–Ј–∞—Ж–Є–Є, –Њ—Б–љ–Њ–≤–∞–љ–љ—Л–µ –љ–∞ –љ–∞–Ј–≤–∞–љ–Є–Є –Ї–Њ–Љ–њ–∞–љ–Є–Є-–њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—П –¶–Я, —Б —А–∞–Ј–љ–Є—Ж–µ–є –≤ —Б–Ї–Њ—А–Њ—Б—В–Є –Њ—В–і–µ–ї—М–љ—Л—Е –≤–µ—В–≤–µ–є –і–Њ –њ–Њ–ї—Г—В–Њ—А–∞ —А–∞–Ј (–њ—А–Є –њ—А–Њ—З–Є—Е —А–∞–≤–љ—Л—Е —Г—Б–ї–Њ–≤–Є—П—Е)!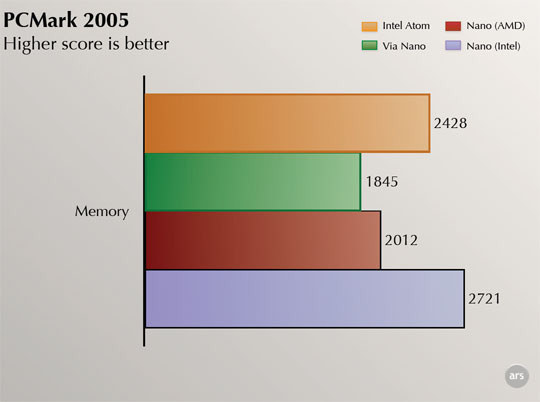
–У—А–∞—Д–Є–Ї —Б —Б–∞–є—В–∞ ArsTechnica.com
–Т–Њ–Ј–Љ–Њ–ґ–љ–Њ, PCMark 2005 –њ—А–µ–і–њ–Њ–ї–∞–≥–∞–µ—В, —З—В–Њ –љ–µ-Intel –¶–Я –љ–µ –Љ–Њ–≥—Г—В –њ–Њ–і–і–µ—А–ґ–Є–≤–∞—В—М SSE2 –Є –µ–≥–Њ –±–Њ–ї–µ–µ —Б–≤–µ–ґ–Є–µ –≤–µ—А—Б–Є–Є? –Ю–і–љ–∞–Ї–Њ, –±—Г–і—Г—З–Є –≤—Л–њ—Г—Й–µ–љ–љ—Л–Љ –≤ 2005 –≥., —В–µ—Б—В, –њ–Њ –Є–і–µ–µ, –і–Њ–ї–ґ–µ–љ –±—Л–ї –±—Л—В—М —А–∞—Б—Б—З–Є—В–∞–љ –≤ —В. —З. –Є –љ–∞ —В–Њ–ї—М–Ї–Њ —З—В–Њ –≤—Л–њ—Г—Й–µ–љ–љ—Л–µ –¶–Я VIA C7 —Б –њ–Њ–і–і–µ—А–ґ–Ї–Њ–є SSE2 –Є SSE3 вАФ –Њ—Б–Њ–±–µ–љ–љ–Њ —Г—З–Є—В—Л–≤–∞—П, —З—В–Њ –≤ –і–∞–љ–љ–Њ–Љ —Б–ї—Г—З–∞–µ –Ј–∞–њ—Г—Б–Ї–∞–ї–∞—Б—М –њ–Њ—Б–ї–µ–і–љ—П—П –≤–µ—А—Б–Є—П —В–µ—Б—В–∞ (1.2.0), –і–∞—В–Є—А–Њ–≤–∞–љ–љ–∞—П 29 –љ–Њ—П–±—А—П 2006 –≥. –Ъ—А–Њ–Љ–µ —В–Њ–≥–Њ, –Ј–љ–∞—З–Є—В–µ–ї—М–љ–∞ —А–∞–Ј–љ–Є—Ж–∞ –Є –Љ–µ–ґ–і—Г –Ј–∞–њ—Г—Б–Ї–∞–Љ–Є ¬Ђ–Ї–∞–Ї AMD¬ї –Є ¬Ђ–Ї–∞–Ї Intel¬ї. Futuremark –Љ–Њ–≥–ї–∞ –±—Л –Њ–њ—А–∞–≤–і–∞—В—М—Б—П —В–µ–Љ, —З—В–Њ –њ—А–Њ—Ж–µ—Б—Б–Њ—А—Л VIA –љ–µ –Њ—З–µ–љ—М –њ–Њ–њ—Г–ї—П—А–љ—Л –Є –љ–µ –њ—А–Њ–і–≤–Є–≥–∞—О—В—Б—П –Ї–∞–Ї –Ї–Њ–љ–Ї—Г—А–µ–љ—В—Л —В–Њ–њ–∞–Љ, –љ–Њ –≤–Њ—В –∞—А—Е–Є—В–µ–Ї—В—Г—А–∞ AMD K8 –љ–∞ —В–Њ—В –Љ–Њ–Љ–µ–љ—В –љ–µ –њ—А–Њ—Б—В–Њ –±—Л–ї–∞, –∞ –Ї–∞–Ї —А–∞–Ј –≤ 2005 –≥. –њ–Њ–ї—Г—З–Є–ї–∞ –њ–Њ–і–і–µ—А–ґ–Ї—Г SSE3.
–Э–Њ –≤—Б—С —Н—В–Њ –њ—А–Є–Љ–µ—А—Л –Є–Ј –њ—А–Њ—И–ї–Њ–≥–Њ. Nano –≤–њ–µ—А–≤—Л–µ –њ–Њ–Ј–≤–Њ–ї–Є–ї –њ—А–Њ–≤–µ—Б—В–Є –љ–µ–Ј–∞–≤–Є—Б–Є–Љ–Њ–µ –Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є–µ —З–µ—Б—В–љ–Њ—Б—В–Є –њ—А–Њ–≥—А–∞–Љ–Љ –Є —В–µ—Б—В–Њ–≤ –±–ї–∞–≥–Њ–і–∞—А—П —В–Њ–Љ—Г, —З—В–Њ –≤—Б—С —В–Њ—В –ґ–µ –Р–≥–љ–µ—А –§–Њ–≥ –њ–Њ–і–Њ–±—А–∞–ї –і–Њ—Б—В—Г–њ –Ї —Б–њ–µ—Ж–Є–∞–ї—М–љ—Л–Љ —А–µ–≥–Є—Б—В—А–∞–Љ –і–ї—П ¬Ђ–њ–µ—А–µ–њ—А–Њ—И–Є–≤–Ї–Є¬ї –љ—Г–ґ–љ—Л—Е –Ј–љ–∞—З–µ–љ–Є–є –Є –≤—Л–њ—Г—Б—В–Є–ї —Б–Њ–Њ—В–≤–µ—В—Б—В–≤—Г—О—Й—Г—О —Г—В–Є–ї–Є—В—Г (–њ–Њ–Ї–∞ —В–Њ–ї—М–Ї–Њ –і–ї—П —Н—В–Њ–≥–Њ –¶–Я). –С–Њ–ї–µ–µ —В–Њ–≥–Њ, –Љ–Є—Б—В–µ—А –§–Њ–≥ –ї—О–±–µ–Ј–љ–Њ –њ–µ—А–µ–і–∞–ї –Є–Ј —Б–≤–Њ–µ–≥–Њ –і–∞–ї—С–Ї–Њ–≥–Њ –Ъ–Њ–њ–µ–љ–≥–∞–≥–µ–љ–∞ –≤ —Б–љ–µ–ґ–љ—Л–є –Я–µ—В–µ—А–±—Г—А–≥ –њ–ї–∞—В—Г —Б Nano, —В. –Ї. –њ–Њ—Б–ї–µ —Г–њ–Њ—А–љ—Л—Е –Є –њ—А–Њ–і–Њ–ї–ґ–Є—В–µ–ї—М–љ—Л—Е –њ–Њ–Є—Б–Ї–Њ–≤ –Њ–Ї–∞–Ј–∞–ї–Њ—Б—М, —З—В–Њ –≤ –†–Њ—Б—Б–Є–Є –њ—А–Њ–і—Г–Ї—Ж–Є–µ–є VIA –њ–Њ—З—В–Є –љ–Є–Ї—В–Њ –љ–µ –Ј–∞–љ–Є–Љ–∞–µ—В—Б—П, –∞ –Њ Nano –і–∞–ґ–µ –Њ—Д–Є—Ж–Є–∞–ї—М–љ—Л–є –і–Є—Б—В—А–Є–±—М—О—В–Њ—А —Б–ї—Л—И–∞—В—М –љ–µ —Е–Њ—З–µ—В. (–Ґ–µ–њ–µ—А—М-—В–Њ, –њ–Њ—Б–ї–µ —В–µ—Б—В–Є—А–Њ–≤–∞–љ–Є—П, –Љ—Л –µ–≥–Њ —Е–Њ—А–Њ—И–Њ –њ–Њ–љ–Є–Љ–∞–µ–ЉвА¶)
–Ш—В–∞–Ї, –Ј–∞–њ—Г—Б—В–Є–≤ –і–ї—П –≤–µ—А–љ–Њ—Б—В–Є –њ—А–Њ–≥—А–∞–Љ–Љ—Г CPU-Z, –Љ—Л —Г–≤–Є–і–Є–Љ VIA Nano –Ї–∞–Ї –Њ–љ –µ—Б—В—М (–љ–∞ –њ–Њ–ї–љ–Њ–є —З–∞—Б—В–Њ—В–µ):
–Р —В–µ–њ–µ—А—М, –ї—С–≥–Ї–Є–Љ –і–≤–Є–ґ–µ–љ–Є–µ–Љ —А–µ–≥–Є—Б—В—А–∞, Nano –њ—А–µ–≤—А–∞—Й–∞–µ—В—Б—ПвА¶ –њ—А–µ–≤—А–∞—Й–∞–µ—В—Б—П NanoвА¶
вА¶–Т —Н–ї–µ–≥–∞–љ—В–љ—Л–є Intel Core 2! –С—Г—А–љ—Л–µ –Є –њ—А–Њ–і–Њ–ї–ґ–Є—В–µ–ї—М–љ—Л–µ –Њ–≤–∞—Ж–Є–Є –њ–Њ–і—З—С—А–Ї–Є–≤–∞—О—В –≤—Б—О –≥–ї—Г–±–Є–љ—Г —В—А–∞–љ—Б—Д–Њ—А–Љ–∞—Ж–Є–Є вАФ —В—Г—В –Є –і–Њ–±–∞–≤–ї–µ–љ–Є–µ –≤–Є—А—В—Г–∞–ї–Є–Ј–∞—Ж–Є–Є, –Є —Г–њ–Њ–ї–Њ–≤–Є–љ–Є–≤–∞–љ–Є–µ –Њ–±–Њ–Є—Е –Ї—Н—И–µ–є L1 (—З—В–Њ–±—Л –љ–Є–Ї—В–Њ –љ–µ –і–Њ–≥–∞–і–∞–ї—Б—П), –Є –і–∞–ґ–µ, –љ–∞ –Ј–∞–≤–Є—Б—В—М –≤—Б–µ–Љ, –Љ–≥–љ–Њ–≤–µ–љ–љ—Л–є –њ–µ—А–µ—Е–Њ–і –љ–∞ —В–µ—Е–љ–Њ–ї–Њ–≥–Є—О 45 –љ–Љ –Є –і—А—Г–≥–Њ–є —А–∞–Ј—К—С–Љ! –Ы–∞–і–љ–Њ, –≥–Њ—Б–њ–Њ–і–∞ –Ї–Њ–њ–њ–µ—А—Д–Є–ї—М–і—Л, —В–∞–Ї –≥–і–µ –ґ –≤—Л –љ–∞—Б –љ–∞–і—Г–ї–Є?–Т–∞—И–Є –і–Њ–Ї—Г–Љ–µ–љ—В—Л?
–Я—А–µ–ґ–і–µ –≤—Б–µ–≥–Њ —А–∞—Б—Б–Ї–∞–ґ–µ–Љ –Њ —В–Њ–Љ, —З—В–Њ —В–∞–Ї–Њ–µ CPUID (CPU identification вАФ (—Б–∞–Љ–Њ)–Њ–њ—А–µ–і–µ–ї–µ–љ–Є–µ –¶–Я). –Ґ–∞–Ї –љ–∞–Ј—Л–≤–∞–µ—В—Б—П –Ї–Њ–Љ–∞–љ–і–∞ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞, –≤–Њ–Ј–≤—А–∞—Й–∞—О—Й–∞—П –µ–≥–Њ ¬Ђ–њ–∞—Б–њ–Њ—А—В¬ї, –≤–њ–µ—А–≤—Л–µ –њ–Њ—П–≤–Є–≤—И–∞—П—Б—П –≤ –Я–µ–љ—В–Є—Г–Љ–∞—Е –Є —Б—В–∞—А—И–Є—Е 486-—Е. –Х—С –љ–∞–ї–Є—З–Є–µ –Њ–±–Њ–Ј–љ–∞—З–∞–µ—В—Б—П –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В—М—О –њ–µ—А–µ–Ј–∞–њ–Є—Б–Є 21-–≥–Њ –±–Є—В–∞ —А–µ–≥–Є—Б—В—А–∞ —Д–ї–∞–≥–Њ–≤. –£ –Ї–Њ–Љ–∞–љ–і—Л –µ—Б—В—М –љ–µ—П–≤–љ—Л–є –∞—А–≥—Г–Љ–µ–љ—В вАФ —Б—В—А–∞–љ–Є—Ж–∞ –њ–∞—Б–њ–Њ—А—В–∞ –≤ —А–µ–≥–Є—Б—В—А–µ EAX, вАФ –∞ –≤–Њ–Ј–≤—А–∞—Й–∞–µ—В –Њ–љ–∞ 16 –±–∞–є—В –≤ —А–µ–≥–Є—Б—В—А–∞—Е EAX, EBX, ECX –Є EDX. –Ш–Љ–µ–љ–љ–Њ —Н—В–∞ –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—П –Є –љ—Г–ґ–љ–∞, —З—В–Њ–±—Л –њ—А–Њ–≥—А–∞–Љ–Љ–∞ –Њ–њ—А–µ–і–µ–ї–Є–ї–∞ –љ–∞–ї–Є—З–Є–µ –Є —З–Є—Б–ї–µ–љ–љ—Л–µ –њ–∞—А–∞–Љ–µ—В—А—Л —А–∞–Ј–љ—Л—Е —Д—Г–љ–Ї—Ж–Є–є –Є –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–µ–є –¶–Я. –Т —А–µ–∞–ї—М–љ–Њ—Б—В–Є –ґ–µ –≤—Б—В—А–µ—З–∞—О—В—Б—П –Є—Б–Ї–ї—О—З–µ–љ–Є—П. –Т–Њ—В —В–∞–±–ї–Є—Ж–∞ –≤–Њ–Ј–≤—А–∞—Й–∞–µ–Љ—Л—Е –Ј–љ–∞—З–µ–љ–Є–є —Б –Є—Е –Њ–њ–Є—Б–∞–љ–Є—П–Љ–Є –љ–∞ –њ—А–Є–Љ–µ—А–µ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞ Nano (–і–ї—П —Г–і–Њ–±—Б—В–≤–∞ –њ—А–Њ—Б–Љ–Њ—В—А–∞ —Н—В–∞ –ґ–µ —В–∞–±–ї–Є—Ж–∞ –≤—Л–љ–µ—Б–µ–љ–∞ –љ–∞ –Њ—В–і–µ–ї—М–љ—Г—О —Б—В—А–∞–љ–Є—Ж—Г):
| –°—В—А–∞–љ–Є—Ж–∞ (EAX) | EAX | EBX | ECX | EDX |
| 1-—П —З–∞—Б—В—М | ||||
| –Ш–Љ—П –¶–Я | –Ь–∞–Ї—Б. –љ–Њ–Љ–µ—А —Б—В—А–∞–љ–Є—Ж—Л –≤ 1-–є —З–∞—Б—В–Є | –Ш–Љ—П –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—П (EBX-EDX-ECX, —Б–Љ. —В–∞–±–ї–Є—Ж—Г –љ–Є–ґ–µ) | ||
|---|---|---|---|---|
| 00 00 00 00 | 00 00 00 0A | 75 6E 65 47 | 6C 65 74 6E | 49 65 6E 69 |
| 10 | вАЩCentвАЩ | вАЩaulsвАЩ | вАЩaurHвАЩ | |
| –Ю—Б–љ–Њ–≤–љ—Л–µ —Д—Г–љ–Ї—Ж–Є–Є –Є –Ї–Њ–Љ–∞–љ–і—Л | –°–µ–Љ–µ–є—Б—В–≤–Њ; –Љ–Њ–і–µ–ї—М; —Б—В–µ–њ–њ–Є–љ–≥ | –С—А—Н–љ–і; —А–∞–Ј–Љ–µ—А —Б–±—А–Њ—Б–∞ —Б—В—А–Њ–Ї–Є –Ї—Н—И–∞; —З–Є—Б–ї–Њ –ї–Њ–≥. —П–і–µ—А; –љ–Њ–Љ–µ—А 1-–≥–Њ –Ї–Њ–љ—В—А–Њ–ї–ї—С—А–∞ APIC | –§–ї–∞–≥–Є —Д—Г–љ–Ї—Ж–Є–є | |
| 00 00 00 01 | 00 00 06 F2 | 00 01 08 00 | 00 00 63 A9 | AF C9 FB FF |
| 6; F; 2 | –Э–µ—В; 64 –±–∞–є—В–∞; 1; 0 | –Я–Њ—З—В–Є –≤—Б—С, —З—В–Њ –µ—Б—В—М —Г —Б–Њ–≤—А–µ–Љ–µ–љ–љ–Њ–≥–Њ –¶–Я | ||
| –Ю–њ–Є—Б–∞—В–µ–ї–Є –Ї—Н—И–µ–є –Є TLB (–њ–Њ –±–∞–є—В—Г) | 15 –Њ–њ–Є—Б–∞—В–µ–ї–µ–є (–Ї—А–Њ–Љ–µ AL, –Њ–Ј–љ–∞—З–∞—О—Й–µ–≥–Њ —З–Є—Б–ї–Њ –Ј–∞–њ—А–Њ—Б–Њ–≤ —Н—В–Њ–є —Б—В—А–∞–љ–Є—Ж—Л –і–ї—П –њ–Њ–ї—Г—З–µ–љ–Є—П –≤—Б–µ—Е –Њ–њ–Є—Б–∞—В–µ–ї–µ–є) | |||
| 00 00 00 02 | 02 B3 B0 01(←AL) | 00 00 00 00 | 00 00 00 00 | 2C 04 30 7D |
| 1 –Ј–∞–њ—А–Њ—Б; TLB-I –і–ї—П —Б—В—А. –њ–Њ 4 –Ь–С: 2 —П—З–µ–є–Ї–Є, 2 –њ—Г—В–Є; TLB-I –Є -D –і–ї—П —Б—В—А. –њ–Њ 4 –Ъ–С: –њ–Њ 128 —П—З–µ–µ–Ї, 4 –њ—Г—В–Є | –Э—Г–ї–µ–≤—Л–µ –Њ–њ–Є—Б–∞—В–µ–ї–Є | L2: 2 –Ь–С, 8 –њ—Г—В–µ–є, 64 –С/—Б—В—А.; TLB-D –і–ї—П —Б—В—А. –њ–Њ 4 –Ь–С: 8 —П—З–µ–µ–Ї, 4 –њ—Г—В–Є; L1D –Є L1I: –њ–Њ 32 –Ъ–С, 8 –њ—Г—В–µ–є, 64 –С/—Б—В—А. | ||
| –°–µ—А–Є–є–љ—Л–є –љ–Њ–Љ–µ—А –¶–Я (–µ—Б–ї–Є –µ—Б—В—М) | ||||
| 00 00 00 03 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| –Я–∞—А–∞–Љ–µ—В—А—Л –Ї—Н—И–µ–є (–Є–Ј-–Ј–∞ –Њ—И–Є–±–Ї–Є –≤ WinNT –і–Њ—Б—В—Г–њ–љ—Л, —В–Њ–ї—М–Ї–Њ –µ—Б–ї–Є —Б–±—А–Њ—И–µ–љ –±–Є—В MISC_ENABLE.LCMV –≤ —А–µ–≥–Є—Б—В—А–µ MSR 1A0) | ||||
| 00 00 00 04 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| –Я–∞—А–∞–Љ–µ—В—А—Л –Њ—В–ї–∞–і–Њ—З–љ—Л—Е –Љ–Њ–љ–Є—В–Њ—А–Њ–≤ | –Ь–Є–љ. —А–∞–Ј–Љ–µ—А —Б—В—А–Њ–Ї–Є –Љ–Њ–љ–Є—В–Њ—А–∞ | –Ь–∞–Ї—Б. —А–∞–Ј–Љ–µ—А —Б—В—А–Њ–Ї–Є –Љ–Њ–љ–Є—В–Њ—А–∞ | –Я—А–µ—А—Л–≤–∞–љ–Є—П —Б—З–Є—В–∞—О—В—Б—П –Њ—Б—В–∞–љ–Њ–≤–∞–Љ–Є; —Г—З—С—В —Б–Њ–±—Л—В–Є–є MWAIT | –І–Є—Б–ї–Њ C-—Б—Г–±—Б–Њ—Б—В–Њ—П–љ–Є–є —Н–љ–µ—А–≥–Њ—Б–±–µ—А–µ–ґ–µ–љ–Є—П –і–ї—П –Ї–Њ–Љ–∞–љ–і—Л MWAIT |
| 00 00 00 05 | 00 00 00 40 | 00 00 00 40 | 00 00 00 03 | 00 02 22 20 |
| 64 –±–∞–є—В–∞ | 64 –±–∞–є—В–∞ | –Ф–∞; –і–∞ | 0 –і–ї—П C0, –њ–Њ 2 –і–ї—П C1вАУC4 | |
| –Я–∞—А–∞–Љ–µ—В—А—Л —Г–њ—А–∞–≤–ї–µ–љ–Є—П –њ–Є—В–∞–љ–Є–µ–Љ (–њ—А–Є MISC_ENABLE.LCMV=0) | ||||
| 00 00 00 06 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| –†–µ–Ј–µ—А–≤ | ||||
| 00 00 00 07 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| 00 00 00 08 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| –Я–∞—А–∞–Љ–µ—В—А—Л DCA (Direct Cache Access, –њ—А—П–Љ–Њ–є –і–Њ—Б—В—Г–њ –Ї –Ї—Н—И—Г) | ||||
| 00 00 00 09 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| –Я–∞—А–∞–Љ–µ—В—А—Л —Б—З—С—В—З–Є–Ї–Њ–≤ –њ—А–Њ–Є–Ј–≤–Њ–і–Є- —В–µ–ї—М–љ–Њ—Б—В–Є | –†–µ–≤–Є–Ј–Є—П; —З–Є—Б–ї–Њ –Є —А–∞–Ј—А—П–і–љ–Њ—Б—В—М —Б—З—С—В—З–Є–Ї–Њ–≤; –і–ї–Є–љ–∞ –≤–µ–Ї—В–Њ—А–∞ –≤ EBX | –Я–∞—А–∞–Љ–µ—В—А—Л –љ–µ–і–Њ—Б—В—Г–њ–љ–Њ—Б—В–Є | –†–µ–Ј–µ—А–≤ | –І–Є—Б–ї–Њ –Є —А–∞–Ј—А—П–і–љ–Њ—Б—В—М —Б—З—С—В—З–Є–Ї–Њ–≤ —Б —Д–Є–Ї—Б. –њ—А–Є–≤—П–Ј–Ї–Њ–є |
| 00 00 00 0A | 06 28 03 02 | 00 00 00 00 | 00 00 00 00 | 00 00 05 03 |
| 2; 3; 40; 6 | –Т—Б–µ —Б–Њ–±—Л—В–Є—П –і–Њ—Б—В—Г–њ–љ—Л | ¬† | 3; 40 | |
| 2-—П —З–∞—Б—В—М | ||||
| –Ф–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ–Њ–µ –Є–Љ—П | –Ь–∞–Ї—Б. –љ–Њ–Љ–µ—А —Б—В—А–∞–љ–Є—Ж—Л –≤–Њ 2-–є —З–∞—Б—В–Є | –Ш–Љ—П –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—П (–і–ї—П AMD –Є Transmeta) | ||
| 80 00 00 00 | 80 00 00 08 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| 8 | –Я—Г—Б—В–Њ | |||
| –Ф–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ—Л–µ –њ–∞—А–∞–Љ–µ—В—А—Л | –°–µ–Љ–µ–є—Б—В–≤–Њ, –Љ–Њ–і–µ–ї—М, —Б—В–µ–њ–њ–Є–љ–≥ | –Ъ–Њ—А–њ—Г—Б –Є –±—А—Н–љ–і (–і–ї—П AMD) | –§–ї–∞–≥–Є —Д—Г–љ–Ї—Ж–Є–є | |
| 80 00 00 01 | 00 00 00 00 | 00 00 00 00 | 00 00 00 01 | 2A 10 08 00 |
| –Э–µ—В –і–Њ–њ–Њ–ї–љ–µ–љ–Є–є | –Я—Г—Б—В–Њ | –Ф–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ—Л–µ —Д–ї–∞–≥–Є | ||
| –Я–Њ–ї–љ–Њ–µ –љ–∞–Ј–≤–∞–љ–Є–µ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞ (–Є–љ–Њ–≥–і–∞ –њ—А–Њ–≥—А–∞–Љ–Є—А—Г–µ—В—Б—П —З–µ—А–µ–Ј MSR) | ||||
| 80 00 00 02 | 20 20 20 20 | 20 20 20 20 | 20 20 20 20 | 56 20 20 20 |
| 4 –њ—А–Њ–±–µ–ї–∞ | 4 –њ—А–Њ–±–µ–ї–∞ | 4 –њ—А–Њ–±–µ–ї–∞ | 3 –њ—А–Њ–±–µ–ї–∞, вАЩVвАЩ | |
| 80 00 00 03 | 4E 20 41 49 | 20 6F 6E 61 | 63 6F 72 70 | 6F 73 73 65 |
| вАЩIA NвАЩ | вАЩano вАЩ | вАЩprocвАЩ | вАЩessoвАЩ | |
| 80 00 00 04 | 32 4C 20 72 | 40 30 30 32 | 30 30 36 31 | 00 7A 48 4D |
| вАЩr L2вАЩ | вАЩ200@вАЩ | вАЩ1600вАЩ | вАЩMHzвАЩ | |
| –Я–∞—А–∞–Љ–µ—В—А—Л L1 –Є –Њ—Б–љ–Њ–≤–љ—Л—Е TLB | TLB –љ–∞ 4 –Ь–С –і–ї—П –і–∞–љ–љ—Л—Е –Є –Ї–Њ–і–∞ (—З–Є—Б–ї–Њ –њ—Г—В–µ–є –Є —А–∞–Ј–Љ–µ—А) | TLB –љ–∞ 4 –Ъ–С –і–ї—П –і–∞–љ–љ—Л—Е –Є –Ї–Њ–і–∞ (—З–Є—Б–ї–Њ –њ—Г—В–µ–є –Є —А–∞–Ј–Љ–µ—А) | L1D: —А–∞–Ј–Љ–µ—А; —З–Є—Б–ї–Њ –њ—Г—В–µ–є –Є —Б—В—А–Њ–Ї –љ–∞ —В–µ–≥; –і–ї–Є–љ–∞ —Б—В—А–Њ–Ї–Є | L1I: —А–∞–Ј–Љ–µ—А; —З–Є—Б–ї–Њ –њ—Г—В–µ–є –Є —Б—В—А–Њ–Ї –љ–∞ —В–µ–≥; –і–ї–Є–љ–∞ —Б—В—А–Њ–Ї–Є |
| 80 00 00 05 | 00 00 00 00 | 08 80 08 80 | 40 10 01 40 | 40 10 01 40 |
| –Э–µ—В —В–∞–Ї–Њ–≥–Њ TLB | –Я–Њ 128 —П—З–µ–µ–Ї –Є 8 –њ—Г—В–µ–є | 64 –Ъ–С; 16; 1; 64 –С | 64 –Ъ–С; 16; 1; 64 –С | |
| –Я–∞—А–∞–Љ–µ—В—А—Л L2, L3 –Є TLB L2 | TLB L2 –љ–∞ 4 –Ь–С –і–ї—П –і–∞–љ–љ—Л—Е –Є –Ї–Њ–і–∞ (—З–Є—Б–ї–Њ –њ—Г—В–µ–є –Є —А–∞–Ј–Љ–µ—А) | TLB L2 –љ–∞ 4 –Ъ–С –і–ї—П –і–∞–љ–љ—Л—Е –Є –Ї–Њ–і–∞ (—З–Є—Б–ї–Њ –њ—Г—В–µ–є –Є —А–∞–Ј–Љ–µ—А) | L2: —А–∞–Ј–Љ–µ—А; —З–Є—Б–ї–Њ –њ—Г—В–µ–є –Є —Б—В—А–Њ–Ї –љ–∞ —В–µ–≥; –і–ї–Є–љ–∞ —Б—В—А–Њ–Ї–Є | L3: —А–∞–Ј–Љ–µ—А; —З–Є—Б–ї–Њ –њ—Г—В–µ–є –Є —Б—В—А–Њ–Ї –љ–∞ —В–µ–≥; –і–ї–Є–љ–∞ —Б—В—А–Њ–Ї–Є |
| 80 00 00 06 | 00 00 00 00 | 00 00 00 00 | 04 00 81 40 | 00 00 00 00 |
| –Э–µ—В —В–∞–Ї–Њ–≥–Њ TLB | –Э–µ—В —В–∞–Ї–Њ–≥–Њ TLB | 1024 –Ъ–С; 16; 1; 64 –С | –Э–µ—В L3 | |
| –Я–∞—А–∞–Љ–µ—В—А—Л —А–∞—Б—И–Є—А–µ–љ–љ–Њ–≥–Њ —Г–њ—А–∞–≤–ї–µ–љ–Є—П –њ–Є—В–∞–љ–Є–µ–Љ | ||||
| 80 00 00 07 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| –Ф—А—Г–≥–Є–µ –њ–∞—А–∞–Љ–µ—В—А—Л | –†–∞–Ј—А—П–і–љ–Њ—Б—В—М –≤–Є—А—В—Г–∞–ї—М–љ–Њ–є –Є —Д–Є–Ј–Є—З–µ—Б–Ї–Њ–є –∞–і—А–µ—Б–∞—Ж–Є–Є | ? | –І–Є—Б–ї–Њ —П–і–µ—А; —А–∞–Ј—А—П–і–љ–Њ—Б—В—М –љ–Њ–Љ–µ—А–∞ —П–і—А–∞ –≤ APIC | ? |
| 80 00 00 08 | 00 00 30 24 | 00 00 00 00 | 00 00 00 00 | 00 00 00 00 |
| 48; 36 | ? | 1; 0 | ? | |
–£ –њ—А–Њ—Ж–µ—Б—Б–Њ—А–Њ–≤ VIA —В–∞–Ї–ґ–µ –і–Њ—Б—В—Г–њ–љ–∞ 3-—П —З–∞—Б—В—М, –љ–∞—З–Є–љ–∞—П —Б–Њ —Б—В—А–∞–љ–Є—Ж—Л C0вАЩ00вАЩ00вАЩ00. –Ґ–∞–Љ –Њ–њ–Є—Б—Л–≤–∞—О—В—Б—П —Б–њ–µ—Ж–Є—Д–Є—З–µ—Б–Ї–Є–µ –і–ї—П —Н—В–Є—Е –¶–Я —Д—Г–љ–Ї—Ж–Є–Є (–љ–∞–±–Њ—А –Ї–Њ–Љ–∞–љ–і PadLock) –Є —Б–Њ–і–µ—А–ґ–Є—В—Б—П –Њ—А–Є–≥–Є–љ–∞–ї —Б—В—А–Њ–Ї–Є ¬Ђ–°–µ–Љ–µ–є—Б—В–≤–Њ, –Љ–Њ–і–µ–ї—М, —Б—В–µ–њ–њ–Є–љ–≥¬ї. –Т –љ–∞—И–Є—Е —В–µ—Б—В–∞—Е –њ—А–Њ—Ж–µ—Б—Б–Њ—А—Г, –њ—А–Є—В–≤–Њ—А—П—О—Й–µ–Љ—Г—Б—П Core 2, —Б–Љ–µ–љ–Є–ї–Є –Є–Љ—П –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—П –љ–∞ ¬ЂGenuineIntel¬ї, –∞ –њ–Њ–ї–Њ–ґ–µ–љ–Є–µ –≤ –Є–µ—А–∞—А—Е–Є–Є вАФ –љ–∞ ¬Ђ6;¬†17;¬†0¬ї (EAX=00вАЩ01вАЩ06вАЩ70, —Е–Њ—В—П –¶–Я —Б–Њ —Б—В–µ–њ–њ–Є–љ–≥–Њ–Љ 0 –Њ–±—Л—З–љ–Њ –±—Л–≤–∞–µ—В –ї–Є—И—М –Є–љ–ґ–µ–љ–µ—А–љ—Л–Љ —Б—Н–Љ–њ–ї–Њ–Љ вАФ –±–µ—В–∞-–≤–µ—А—Б–Є–µ–є —З–Є–њ–∞ –љ–µ –і–ї—П –Љ–∞—Б—Б–Њ–≤–Њ–≥–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є—П, —З—В–Њ –Є —Г–Ї–∞–Ј–∞–љ–Њ –±—Г–Ї–≤–∞–Љ–Є ES –љ–∞ –≤—В–Њ—А–Њ–Љ —Б–Ї—А–Є–љ—И–Њ—В–µ).
–Э–µ—В—А—Г–і–љ–Њ –Ј–∞–Љ–µ—В–Є—В—М, —З—В–Њ –і–∞–ї–µ–Ї–Њ –љ–µ –≤—Б—П –њ–Њ—Б—В–∞–≤–ї—П–µ–Љ–∞—П –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—П –≤–µ—А–љ–∞, –і–∞–ґ–µ –µ—Б–ї–Є –љ–Є–Ї–∞–Ї–Є–µ —Б—В—А–Њ–Ї–Є –љ–µ –Љ–µ–љ—П–ї–Є—Б—М. –Я–∞—А–∞–Љ–µ—В—А—Л –Ї—Н—И–µ–є –Є TLB –Ї–Њ–≥–і–∞-—В–Њ –њ–µ—А–µ–і–∞–≤–∞–ї–Є—Б—М –Њ–њ–Є—Б–∞—В–µ–ї—П–Љ–Є (–і–µ—Б–Ї—А–Є–њ—В–Њ—А–∞–Љ–Є) –љ–∞ —Б—В—А. 2 1-–є —З–∞—Б—В–Є. –Э–Њ –Њ–і–љ–Њ–≥–Њ –±–∞–є—В–∞ —Е–≤–∞—В–∞–µ—В –і–∞–ї–µ–Ї–Њ –љ–µ –љ–∞ –≤—Б–µ –Ї–Њ–Љ–±–Є–љ–∞—Ж–Є–Є —З–Є—Б–µ–ї, –њ–Њ—Н—В–Њ–Љ—Г –≤–Њ 2-–є —З–∞—Б—В–Є –Ї—Н—И–Є –Є TLB –Њ–њ–Є—Б—Л–≤–∞—О—В—Б—П —В–Њ—З–љ–Њ, –Є –Є–Љ–µ–љ–љ–Њ —В—Г–і–∞ –Є –љ–∞–і–Њ —Б–Љ–Њ—В—А–µ—В—М –њ—А–Њ–≥—А–∞–Љ–Љ–∞–Љ-–і–µ—В–µ–Ї—В–Њ—А–∞–Љ. –Э–∞–њ—А–Є–Љ–µ—А, —Б—А–µ–і–Є –Њ–њ–Є—Б–∞—В–µ–ї–µ–є –љ–µ—В –≤–∞—А–Є–∞–љ—В–∞ –і–ї—П ¬ЂL1D –љ–∞ 64 –Ъ–С, 2 –њ—Г—В–Є –Є 64 –С/—Б—В—А.¬ї (–Ї–∞–Ї –≤ —Б–Њ–≤—А–µ–Љ–µ–љ–љ—Л—Е –њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞—Е AMD), –љ–Њ –≤—Б–µ –њ—А–Њ–≥—А–∞–Љ–Љ—Л –≤–µ—А–љ–Њ –њ–Њ–Ї–∞–Ј—Л–≤–∞—О—В –њ–∞—А–∞–Љ–µ—В—А—Л –Ї—Н—И–µ–є –і–ї—П —Н—В–Є—Е –¶–Я. –Ю–і–љ–∞–Ї–Њ –≤—Л—И–µ –љ–∞ –њ—А–Є–Љ–µ—А–µ CPU-Z –Љ—Л –≤–Є–і–Є–Љ, —З—В–Њ –і–ї—П VIA Nano (–Є, —Б–Ї–Њ—А–µ–µ –≤—Б–µ–≥–Њ, –≤–Њ–Њ–±—Й–µ –і–ї—П –≤—Б–µ—Е –¶–Я) –≤—Б—С –љ–µ —В–∞–Ї вАФ —Б—Г–і—П –њ–Њ –≤—Б–µ–Љ—Г, –њ–∞—А–∞–Љ–µ—В—А—Л –Ї—Н—И–µ–є –љ–µ —З–Є—В–∞—О—В—Б—П –Ї–Њ–Љ–∞–љ–і–Њ–є CPUID, –∞ –њ—А–Њ—Б—В–Њ –±–µ—А—Г—В—Б—П –Є–Ј –±–∞–Ј—Л –і–∞–љ–љ—Л—Е –њ—А–Њ–≥—А–∞–Љ–Љ—Л, –Њ—Б–љ–Њ–≤—Л–≤–∞—П—Б—М –љ–∞ –Є–Љ–µ–љ–Є –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—П –Є —Б—В—А–Њ–Ї–µ ¬Ђ–°–µ–Љ–µ–є—Б—В–≤–Њ, –Љ–Њ–і–µ–ї—М, —Б—В–µ–њ–њ–Є–љ–≥¬ї. –Я—А–Њ–Є—Б—Е–Њ–і–Є—В —В–∞ –ґ–µ ¬Ђ–њ–Њ–і–Љ–µ–љ–∞ —А–µ–∞–ї—М–љ–Њ—Б—В–Є¬ї, —З—В–Њ –Є –≤ –і–Є—Б–њ–µ—В—З–µ—А–∞—Е –њ—А–Њ–≥—А–∞–Љ–Љ, —А–Њ–ґ–і—С–љ–љ—Л—Е –њ—А–Њ–і—Г–Ї—В–∞–Љ–Є Intel.
–Ъ–Њ–љ–µ—З–љ–Њ, –Ј–љ–∞—О—Й–Є–µ –њ—А–Њ–≥—А–∞–Љ–Љ–Є—Б—В—Л —Б–Ї–∞–ґ—Г—В ¬Ђ—З—М—П –± –Ї–Њ—А–Њ–≤–∞ –Љ—Л—З–∞–ї–∞¬ї вАФ –љ–µ–Ї–Њ—В–Њ—А—Л–µ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї–Є —Б–∞–Љ–Є –љ–µ –≤—Б–µ–≥–і–∞ —В–Њ—З–љ–Њ —Г–Ї–∞–Ј—Л–≤–∞—О—В –і–∞–љ–љ—Л–µ –≤ –њ–∞—Б–њ–Њ—А—В–µ —Б–≤–Њ–Є—Е –¶–Я –љ–µ —В–Њ–ї—М–Ї–Њ –њ–Њ –њ—А–Є—З–Є–љ–µ –Њ—В—Б—Г—В—Б—В–≤–Є—П –љ—Г–ґ–љ—Л—Е –Ї–Њ–і–Њ–≤, –љ–Њ –Є –Є–Ј-–Ј–∞ —Н–ї–µ–Љ–µ–љ—В–∞—А–љ–Њ–є –љ–µ–±—А–µ–ґ–љ–Њ—Б—В–Є. –Э–∞–њ—А–Є–Љ–µ—А, –њ–µ—А–≤—Л–µ AMD Duron —Б–Њ–Њ–±—Й–∞–ї–Є, —З—В–Њ —Г –љ–Є—Е 1 –Ъ–С L2. –Я–Њ—Н—В–Њ–Љ—Г, —З—В–Њ–±—Л –≤–µ—А–љ–Њ –Њ—В—З–Є—В—Л–≤–∞—В—М—Б—П –і–∞–ґ–µ –Њ –њ–µ—А–≤—Л—Е –≤–∞—А–Є–∞–љ—В–∞—Е –¶–Я, –њ—А–Њ–≥—А–∞–Љ–Љ—Л –њ—А–Њ—Б—В–Њ –Ј–∞–њ–Є—Б—Л–≤–∞—О—В ¬Ђ–≤–µ—А–љ—Л–µ¬ї –њ–Њ–Ї–∞–Ј–∞—В–µ–ї–Є –≤ —Б–Њ–±—Б—В–≤–µ–љ–љ—Л–µ —В–∞–±–ї–Є—Ж—Л –Ї–Њ–љ—Б—В–∞–љ—В. –Ъ–Њ–≥–і–∞ –њ–Њ–њ–∞–і–∞–µ—В—Б—П –і–µ–є—Б—В–≤–Є—В–µ–ї—М–љ–Њ –љ–µ–Є–Ј–≤–µ—Б—В–љ—Л–є –њ—А–Њ—Ж–µ—Б—Б–Њ—А, –Є–Љ–µ–µ—В —Б–Љ—Л—Б–ї —З–Є—В–∞—В—М –±—Г–Ї–≤–∞–ї—М–љ–Њ, —З–µ—А–µ–Ј CPUID, –љ–Њ –µ—Б–ї–Є —Н—В–Њ ¬Ђ–Њ–±–Њ—А–Њ—В–µ–љ—М –≤ —В—А–∞–љ–Ј–Є—Б—В–Њ—А–∞—Е¬ї вАФ –Њ–±–і—Г—А–Є—В—М –Љ–Њ–ґ–љ–Њ –љ–µ —В–Њ–ї—М–Ї–Њ –Є—Б–њ–Њ–ї–љ—П–µ–Љ—Л–µ –њ—А–Њ–≥—А–∞–Љ–Љ—Л, –љ–Њ –Є –њ–Њ–ї—М–Ј–Њ–≤–∞—В–µ–ї—П.–†–∞–Ј–Њ–±–ї–∞—З–∞—О—Й–Є–µ —В–µ—Б—В—Л
–Я–ї–∞—В–∞ VIA VB8001 –љ–∞ —Б—В–∞—А–Њ–Љ —З–Є–њ—Б–µ—В–µ CN896 —Б–Њ –≤–њ–∞—П–љ–љ—Л–Љ Nano –њ—А–Њ–і–µ–ї–∞–ї–∞ –і–Њ–ї–≥–Є–є –і–≤—Г—Е–Љ–µ—Б—П—З–љ—Л–є –њ—Г—В—М –Є–Ј –Ъ–Њ–њ–µ–љ–≥–∞–≥–µ–љ–∞ –≤ –°–∞–љ–Ї—В-–Я–µ—В–µ—А–±—Г—А–≥ (–≥–Њ—А—П—З–Є–є –њ—А–Є–≤–µ—В –Я–Њ—З—В–µ –†–Њ—Б—Б–Є–Є!) –љ–µ —В–Њ–ї—М–Ї–Њ —А–∞–і–Є —Б–љ—П—В–Є—П –њ–∞—А—Л —Б–Ї—А–Є–љ—И–Њ—В–Њ–≤. –Ґ–µ–Љ –±–Њ–ї–µ–µ —З—В–Њ –љ–∞–ї–Є—З–Є–µ —А–∞–Ј—К—С–Љ–∞ PCI-E x16 –њ–Њ–Ј–≤–Њ–ї–Є–ї–Њ —Г—Б—В–∞–љ–Њ–≤–Є—В—М —В—Г–і–∞ —Б—В–∞–љ–і–∞—А—В–љ—Г—О –≤–Є–і–µ–Њ–Ї–∞—А—В—Г —Б –љ–∞—И–µ–≥–Њ —В–µ—Б—В–Њ–≤–Њ–≥–Њ —Б—В–µ–љ–і–∞. –Ґ–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ, –љ–µ —Б—З–Є—В–∞—П –Њ–±—К—С–Љ–∞ –Ю–Ч–£ (–±–Њ–ї—М—И–µ 4 –У–С –≤ 2 —Б–ї–Њ—В–∞ —Г—Б—В–∞–љ–Њ–≤–Є—В—М –љ–µ –њ–Њ–ї—Г—З–Є—В—Б—П), —Б–Њ–±–ї—О–і–µ–љ—Л –≤—Б–µ —Б—В–∞–љ–і–∞—А—В–љ—Л–µ —Г—Б–ї–Њ–≤–Є—П, —З—В–Њ–±—Л –њ—А–Њ—В–µ—Б—В–Є—А–Њ–≤–∞—В—М VIA Nano ¬Ђ–њ–Њ-–≤–Ј—А–Њ—Б–ї–Њ–Љ—Г¬ї, –Ї–∞–Ї –љ–∞—Б—В–Њ—П—Й–Є–є 64-–±–Є—В–љ—Л–є x86-–њ—А–Њ—Ж–µ—Б—Б–Њ—А вАФ –±–ї–∞–≥–Њ, –Є –љ–Њ–≤–∞—П –Љ–µ—В–Њ–і–Є–Ї–∞ –Њ–±—А–∞–Ј—Ж–∞ 2010 –≥–Њ–і–∞ –Ї —В–Њ–Љ—Г –≤—А–µ–Љ–µ–љ–Є –±—Л–ї–∞ –њ–Њ—З—В–Є –≥–Њ—В–Њ–≤–∞. –Я—А–µ–ґ–і–µ –≤—Б–µ–≥–Њ –љ–∞—Б –Є–љ—В–µ—А–µ—Б–Њ–≤–∞–ї–∞ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М —Б ¬Ђ—А–Њ–і–љ—Л–Љ¬ї (Native) –Є ¬Ђ–њ–Њ–і–Љ–µ–љ—С–љ–љ—Л–Љ¬ї (–љ–∞ Core 2) CPUID –Ї–∞–Ї –њ—А–∞–Ї—В–Є—З–µ—Б–Ї–∞—П –њ—А–Њ–≤–µ—А–Ї–∞ –≤—Л–≤–Њ–і–Њ–≤ –Р–≥–љ–µ—А–∞ –§–Њ–≥–∞.
–Э–Њ –њ—А–Њ—Ж–µ—Б—Б —В–µ—Б—В–Є—А–Њ–≤–∞–љ–Є—П –Є–љ–∞—З–µ –Ї–∞–Ї ¬Ђ–Љ—Г—З–Є—В–µ–ї—М–љ—Л–Љ¬ї –љ–∞–Ј–≤–∞—В—М –±—Л–ї–Њ —Б–ї–Њ–ґ–љ–Њ. –Ь—Л –љ–µ –Љ–Њ–ґ–µ–Љ —Б—Г–і–Є—В—М –Њ —В–Њ–Љ, –Ї—В–Њ –≤ —Н—В–Њ–Љ –≤–Є–љ–Њ–≤–∞—В вАФ –љ–µ–і–Њ–±—А–Њ—Б–Њ–≤–µ—Б—В–љ—Л–µ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї–Є –Я–Ю –Є/–Є–ї–Є –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–Њ–≤, –Ї–Њ–љ–Ї—А–µ—В–љ—Л–є —Н–Ї–Ј–µ–Љ–њ–ї—П—А –њ–ї–∞—В—Л –Є/–Є–ї–Є –њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞, вАФ –Њ–і–љ–∞–Ї–Њ ¬Ђ–Љ—С—А—В–≤—Л–µ –≤–Є—Б—Л¬ї (–Ї–Њ–≥–і–∞ –њ–Њ–Љ–Њ–≥–∞–µ—В –ї–Є—И—М –Њ—В–Ї–ї—О—З–µ–љ–Є–µ –њ–Є—В–∞–љ–Є—П –Є–ї–Є –љ–∞–ґ–∞—В–Є–µ Reset) —Б–ї—Г—З–∞–ї–Є—Б—М –љ–∞—Б—В–Њ–ї—М–Ї–Њ —З–∞—Б—В–Њ, —З—В–Њ —В–µ—Б—В–µ—А—Г –і–∞–ґ–µ –њ—А–Є—И–ї–Њ—Б—М –њ—А–Њ—В—П–љ—Г—В—М –Њ—В —Б—В–µ–љ–і–∞ –Ї —Б–≤–Њ–µ–Љ—Г —А–∞–±–Њ—З–µ–Љ—Г —Б—В–Њ–ї—Г –Њ—В–і–µ–ї—М–љ—Л–є –њ—А–Њ–≤–Њ–і–Њ–Ї c –≤–љ–µ—И–љ–µ–є –Ї–љ–Њ–њ–Њ—З–Ї–Њ–є —Б–±—А–Њ—Б–∞ вАФ —Г–ґ –Њ—З–µ–љ—М –љ–∞–њ—А—П–≥–∞–ї–Њ –њ–Њ—Б—В–Њ—П–љ–љ–Њ –≤—Б—В–∞–≤–∞—В—М —Б –Ї—А–µ—Б–ї–∞. :)
–Т–Њ—В –њ–Њ–ї–љ—Л–є —Б–њ–Є—Б–Њ–Ї –±–µ–љ—З–Љ–∞—А–Ї–Њ–≤, –≤ –Ї–Њ—В–Њ—А–Њ–Љ –њ–Њ–Љ–µ—З–µ–љ—Л —В–µ—Б—В—Л, —Г–і–∞—З–љ–Њ –Є–ї–Є –љ–µ—Г–і–∞—З–љ–Њ –њ—А–Њ–є–і–µ–љ–љ—Л–µ VIA Nano –≤ –Њ–±–Њ–Є—Е —А–µ–ґ–Є–Љ–∞—Е. –Ь–Є–љ—Г—Б –Њ–Ј–љ–∞—З–∞–µ—В, —З—В–Њ —В–µ—Б—В –Ј–∞–≤–Є—Б–∞–ї –Є–ї–Є –њ–µ—А–µ–Ј–∞–≥—А—Г–ґ–∞–ї –Ї–Њ–Љ–њ—М—О—В–µ—А —Б—А–∞–Ј—Г –њ–Њ—Б–ї–µ –Ј–∞–њ—Г—Б–Ї–∞ –Є–ї–Є –≤ –њ—А–Њ–Є–Ј–≤–Њ–ї—М–љ–Њ–Љ –Љ–µ—Б—В–µ –≤ –њ—А–Њ—Ж–µ—Б—Б–µ —А–∞–±–Њ—В—Л. –Ч–∞–Љ–µ—В–Є–Љ, —З—В–Њ ¬Ђ–Ј–∞–Љ–Є–љ—Г—Б–Њ–≤–∞–љ—Л¬ї —В–µ—Б—В—Л, –Ї–Њ—В–Њ—А—Л–µ —Б–Њ–≤—Б–µ–Љ –љ–µ —Г–і–∞–ї–Њ—Б—М –≤—Л–њ–Њ–ї–љ–Є—В—М: –Њ —В–∞–Ї–Є—Е —Б—Ж–µ–љ–∞—А–Є—П—Е, –Ї–∞–Ї ¬Ђ–Ј–∞–њ—Г—Б—В–Є–ї–Є вАФ –Ј–∞–≤–Є—Б вАФ –њ–µ—А–µ–Ј–∞–њ—Г—Б—В–Є–ї–Є вАФ –Ј–∞–≤–Є—Б вАФ –њ–µ—А–µ–Ј–∞–њ—Г—Б—В–Є–ї–Є вАФ —Г—А–∞, –њ—А–Њ—И—С–ї!¬ї –Љ—Л –і–∞–ґ–µ –љ–µ —Г–њ–Њ–Љ–Є–љ–∞–µ–Љ.
|
|
*¬†вАФ¬†–°—З–Є—В–∞–µ—В—Б—П ¬Ђ—Г—Б–ї–Њ–≤–љ–Њ –њ—А–Њ–є–і–µ–љ–љ—Л–Љ¬ї: –њ–Њ –љ–∞—И–µ–є —В–µ—Б—В–Њ–≤–Њ–є –Љ–µ—В–Њ–і–Є–Ї–µ –Ї–∞–ґ–і—Л–є –±–µ–љ—З–Љ–∞—А–Ї –Ј–∞–њ—Г—Б–Ї–∞–µ—В—Б—П 4 —А–∞–Ј–∞: –Њ–і–Є–љ ¬Ђ—А–∞–Ј–Њ–≥—А–µ–≤–Њ—З–љ—Л–є¬ї –њ—А–Њ–≥–Њ–љ –Є 3 —А–µ–Ј—Г–ї—М—В–Є—А—Г—О—Й–Є—Е. –Т —А–Њ–і–љ–Њ–Љ —А–µ–ґ–Є–Љ–µ VIA Nano –љ–Є —А–∞–Ј—Г –љ–µ —Г–і–∞–≤–∞–ї–Њ—Б—М –њ—А–Њ–є—В–Є –≤–µ—Б—М —В–µ—Б—В Adobe Photoshop —Ж–µ–ї–Є–Ї–Њ–Љ: –љ–∞–Є–ї—Г—З—И–Є–Љ –і–Њ—Б—В–Є–ґ–µ–љ–Є–µ–Љ –±—Л–ї–Њ 2 –Ј–∞–≤–µ—А—И—С–љ–љ—Л—Е –њ—А–Њ–≥–Њ–љ–∞, –њ–Њ—Б–ї–µ —З–µ–≥–Њ –љ–∞ —В—А–µ—В—М–µ–Љ —Б–Є—Б—В–µ–Љ–∞ –њ–µ—А–µ–Ј–∞–≥—А—Г–ґ–∞–ї–∞—Б—М. ↑
–Ш—В–Њ–≥–Њ, –Є–Ј 54 —В–µ—Б—В–Њ–≤ VIA Nano –љ–µ —Б–Љ–Њ–≥ –њ—А–Њ–є—В–Є 15, —В. –µ. –±–Њ–ї—М—И–µ —З–µ—В–≤–µ—А—В–Є. –С–Њ–ї–µ–µ —З–µ–Љ –Њ—И–µ–ї–Њ–Љ–ї—П—О—Й–∞—П —Ж–Є—Д—А–∞ –і–ї—П –¶–Я, –Ї–Њ—В–Њ—А—Л–є –њ–Њ–Ј–Є—Ж–Є–Њ–љ–Є—А—Г–µ—В—Б—П –Ї–∞–Ї x86-64-—Б–Њ–≤–Љ–µ—Б—В–Є–Љ—Л–є. –Ъ–∞–Ї —Г–ґ–µ –љ–∞–њ–Є—Б–∞–љ–Њ –≤—Л—И–µ, –Љ—Л –љ–µ –Љ–Њ–ґ–µ–Љ –Њ–і–љ–Њ–Ј–љ–∞—З–љ–Њ –Њ–±–≤–Є–љ—П—В—М –≤–Њ –≤—Б—С–Љ –Є–Љ–µ–љ–љ–Њ –њ—А–Њ—Ж–µ—Б—Б–Њ—А, –љ–Њ –µ—Б—В—М –Њ–і–Є–љ –љ–∞–≤–Њ–і—П—Й–Є–є –љ–∞ —А–∞–Ј–Љ—Л—И–ї–µ–љ–Є—П –љ—О–∞–љ—Б: —В–∞ –ґ–µ —Б–∞–Љ–∞—П –њ–ї–∞—В–∞ —Б VIA Nano —Б–µ–є—З–∞—Б —А–∞–±–Њ—В–∞–µ—В –і–Њ–Љ–∞ —Г –Њ–і–љ–Њ–≥–Њ –Є–Ј –∞–≤—В–Њ—А–Њ–≤ –≤ –Ї–∞—З–µ—Б—В–≤–µ –Њ—Б–љ–Њ–≤—Л –і–ї—П –і–Њ–Љ–∞—И–љ–µ–≥–Њ NAS. –Ґ–∞–Ї –≤–Њ—В: —Б –љ–∞–±–Њ—А–Њ–Љ –Я–Ю, —Б–≤–Њ–і—П—Й–Є–Љ—Б—П –Ї 32-–±–Є—В–љ–Њ–є Windows XP Professional, –Љ–µ–і–Є–∞—Б–µ—А–≤–µ—А—Г, ftp- –Є http-—Б–µ—А–≤–µ—А—Г –Є –∞–љ—В–Є–≤–Є—А—Г—Б—Г, –Њ–љ–∞ –љ–Њ—А–Љ–∞–ї—М–љ–Њ —Д—Г–љ–Ї—Ж–Є–Њ–љ–Є—А–Њ–≤–∞–ї–∞ –≤ –Ї—А—Г–≥–ї–Њ—Б—Г—В–Њ—З–љ–Њ–Љ —А–µ–ґ–Є–Љ–µ –љ–∞ –њ—А–Њ—В—П–ґ–µ–љ–Є–Є –њ–Њ–ї—Г—В–Њ—А–∞ –Љ–µ—Б—П—Ж–µ–≤ –±–µ–Ј –µ–і–Є–љ–Њ–≥–Њ –Ј–∞–≤–Є—Б–∞–љ–Є—ПвА¶
–Т—Б–µ –≤–Њ–Ј–Љ–Њ–ґ–љ—Л–µ –Њ—И–Є–±–Ї–Є –њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞ –Љ–Њ–≥—Г—В –±—Л—В—М –Є—Б–њ—А–∞–≤–ї–µ–љ—Л –≤ –Њ–±–љ–Њ–≤–ї—С–љ–љ–Њ–є –ї–Є–љ–µ–є–Ї–µ Nano 3xxx (—А–µ–≤–Є–Ј–Є—П CNB), –љ–Њ —Г—В–Њ—З–љ–Є–Љ: —Г –љ–∞—Б –љ–µ—В –љ–Є–Ї–∞–Ї–Њ–є –Є–љ—Д–Њ—А–Љ–∞—Ж–Є–Є –љ–Є –Њ —Б–і–µ–ї–∞–љ–љ—Л—Е –Є—Б–њ—А–∞–≤–ї–µ–љ–Є—П—Е, –љ–Є –Њ —В–Њ–Љ, –Ї–∞–Ї–Є–µ –Њ—И–Є–±–Ї–Є –Є–Ј–≤–µ—Б—В–љ—Л –љ–∞ –і–∞–љ–љ—Л–є –Љ–Њ–Љ–µ–љ—В —Б–∞–Љ–Њ–є VIA. –Т–њ—А–Њ—З–µ–Љ, –≥–ї—О–Ї–Є –≤–њ–Њ–ї–љ–µ –Љ–Њ–≥—Г—В –Њ–Ї–∞–Ј–∞—В—М—Б—П –≤–Њ–≤—Б–µ –љ–µ –≤–љ—Г—В—А–Є –њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞: –Є–Ј 15 –њ—А–Њ–±–ї–µ–Љ–љ—Л—Е –њ—А–Њ–≥—А–∞–Љ–Љ 11 –Њ—З–µ–љ—М –∞–Ї—В–Є–≤–љ–Њ —А–∞–±–Њ—В–∞—О—В —Б –≤–Є–і–µ–Њ–њ–Њ–і—Б–Є—Б—В–µ–Љ–Њ–є, –њ—А–Є—З—С–Љ —Б –Ј–∞–і–µ–є—Б—В–≤–Њ–≤–∞–љ–Є–µ–Љ –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–µ–є –∞–њ–њ–∞—А–∞—В–љ–Њ–≥–Њ —Г—Б–Ї–Њ—А–µ–љ–Є—П –≤–Є–і–µ–Њ–Ї–∞—А—В—Л. –Ш –Ј–і–µ—Б—М –њ–Њ—З–≤–∞ –і–ї—П —Д–∞–љ—В–∞–Ј–Є–Є –≤–µ—Б—М–Љ–∞ —И–Є—А–Њ–Ї–∞: –Њ—В –і—А–∞–є–≤–µ—А–Њ–≤ –≤–Є–і–µ–Њ–Ї–∞—А—В—Л –і–Њ –≤–љ—Г—В—А–Є—Б–Є—Б—В–µ–Љ–љ—Л—Е –і—А–∞–є–≤–µ—А–Њ–≤ –Ї–Њ–љ—В—А–Њ–ї–ї–µ—А–∞ PCI-E –Є–ї–Є –µ–≥–Њ —Б–∞–Љ–Њ–≥–Њ. –Ю–і–љ–∞–Ї–Њ –≤–Є–љ–Њ–≤–∞—В–∞ —Б–Ї–Њ—А–µ–µ –≤—Б–µ–≥–Њ –≤—Б—С —А–∞–≤–љ–Њ VIA. :)
–†–µ–Ј—Г–ї—М—В–∞—В—Л —Б—А–∞–≤–љ–µ–љ–Є—П —А–Њ–і–љ–Њ–≥–Њ —А–µ–ґ–Є–Љ–∞ —Б ¬Ђ—Н–Љ—Г–ї—П—Ж–Є–µ–є¬ї Intel Core 2
–Я–Њ—Б–Љ–Њ—В—А–Є–Љ, –љ–∞—Б–Ї–Њ–ї—М–Ї–Њ –ґ–µ —Г—Б–Ї–Њ—А—П—О—В—Б—П (–≤ –њ—А–Њ—Ж–µ–љ—В–∞—Е) –≤ ¬Ђ—А–µ–ґ–Є–Љ–µ Core 2¬ї –њ—А–Њ–≥—А–∞–Љ–Љ—Л –Є–Ј —В–µ—Е, –Ї–Њ—В–Њ—А—Л–Љ –њ–Њ—Б—З–∞—Б—В–ї–Є–≤–Є–ї–Њ—Б—М –і–Њ—А–∞–±–Њ—В–∞—В—М –і–Њ –Ї–Њ–љ—Ж–∞:
| –Ґ–µ—Б—В | Native | Core 2 | Δ% |
| Java | 10,55 | 10,67 | 1% |
| –Р—А—Е–Є–≤–∞—Ж–Є—П: 7-Zip | 0:18:25 | 0:18:20 | 0% |
| –Р—А—Е–Є–≤–∞—Ж–Є—П: WinRAR | 0:08:09 | 0:08:01 | 2% |
| –Р—А—Е–Є–≤–∞—Ж–Є—П: —А–∞—Б–њ–∞–Ї–Њ–≤–Ї–∞ | 0:02:23 | 0:02:23 | 0% |
| –Р—Г–і–Є–Њ: Apple Lossless | 20 | 21 | 5% |
| –Р—Г–і–Є–Њ: FLAC | 25 | 25 | 0% |
| –Р—Г–і–Є–Њ: Monkey's Audio | 19 | 19 | 0% |
| –Р—Г–і–Є–Њ: MP3 (LAME) | 9 | 10 | 11% |
| –Р—Г–і–Є–Њ: Nero AAC | 10 | 10 | 0% |
| –Р—Г–і–Є–Њ: OGG Vorbis | 7 | 7 | 0% |
| –С—А–∞—Г–Ј–µ—А: SunSpider/Chrome | 1357 | 1322 | 3% |
| –С—А–∞—Г–Ј–µ—А: SunSpider/Firefox | 2259 | 2237 | 1% |
| –С—А–∞—Г–Ј–µ—А: SunSpider/IE | 14875 | 15121 | −2% |
| –С—А–∞—Г–Ј–µ—А: SunSpider/Opera | 863 | 859 | 0% |
| –С—А–∞—Г–Ј–µ—А: SunSpider/Safari | 1245 | 1231 | 1% |
| –Т–Є–і–µ–Њ: DivX | 0:18:51 | 0:18:42 | 1% |
| –Т–Є–і–µ–Њ: Mainconcept | 0:56:32 | 0:56:31 | 0% |
| –Т–Є–і–µ–Њ: Premiere | 1:04:31 | 1:04:33 | 0% |
| –Т–Є–і–µ–Њ: x264 | 1:58:46 | 1:52:01 | 6% |
| –Т–Є–і–µ–Њ: XviD | 0:17:43 | 0:17:17 | 3% |
| –Т–Є–Ј—Г–∞–ї–Є–Ј–∞—Ж–Є—П: Lightwave | 75,56 | 78,31 | −4% |
| –Т–Є–Ј—Г–∞–ї–Є–Ј–∞—Ж–Є—П: UGS NX 6 | 0,74 | 0,73 | −1% |
| –У—А–∞—Д–Є–Ї–∞: ACDSee | 0:21:59 | 0:21:43 | 1% |
| –У—А–∞—Д–Є–Ї–∞: PaintShop | 0:38:01 | 0:37:58 | 0% |
| –У—А–∞—Д–Є–Ї–∞: PhotoImpact | 0:33:10 | 0:32:53 | 1% |
| –У—А–∞—Д–Є–Ї–∞: Photoshop | 0:31:47 | 0:31:27 | 1% |
| –Ш–≥—А—Л: Borderlands | 11 | 11 | 0% |
| –Ш–≥—А—Л: Far Cry 2 | 5,6 | 5,6 | 0% |
| –Ш–≥—А—Л: Fritz Chess | 740 | 748 | 1% |
| –Ш–≥—А—Л: Resident Evil 5 | 18,2 | 18,5 | 2% |
| –Ъ–Њ–Љ–њ–Є–ї—П—Ж–Є—П | 0:52:52 | 0:52:01 | 2% |
| –†–∞—Б—З—С—В—Л: MAPLE | 0,1211 | 0,1216 | 0% |
| –†–∞—Б—З—С—В—Л: Mathematica (int) | 0,804 | 0,891 | 11% |
| –†–∞—Б—З—С—В—Л: Mathematica (MMA) | 0,5269 | 0,4849 | −8% |
| –†–∞—Б—З—С—В—Л: MATLAB | 0,3421 | 0,2677 | 28% |
| –†–∞—Б—З—С—В—Л: UGS NX 6 | 1,47 | 1,47 | 0% |
| –†–µ–љ–і–µ—А–Є–љ–≥: 3ds max | 4:17:04 | 4:16:31 | 0% |
| –†–µ–љ–і–µ—А–Є–љ–≥: Lightwave | 1370,05 | 1428,26 | −4% |
–Ф–∞–≤–∞–є—В–µ —А–∞–Ј–±–Є—А–∞—В—М—Б—П. –°–љ–∞—З–∞–ї–∞ –Њ—В—Б–µ—З—С–Љ –Њ—З–µ–≤–Є–і–љ–Њ–µ –Є –њ—А–Є–≤—Л—З–љ–Њ–µ: –Ї–∞–Ї –Љ—Л —Г–ґ–µ –љ–µ–Њ–і–љ–Њ–Ї—А–∞—В–љ–Њ –њ–Є—Б–∞–ї–Є, —А–∞—Б—Е–Њ–ґ–і–µ–љ–Є–µ —А–µ–Ј—Г–ї—М—В–∞—В–Њ–≤ –љ–∞ 1вАУ2%, –µ—Б–ї–Є –Њ–љ–Њ –љ–µ —Б–Є—Б—В–µ–Љ–∞—В–Є—З–µ—Б–Ї–Њ–µ, –љ–µ —Б–≤–Є–і–µ—В–µ–ї—М—Б—В–≤—Г–µ—В –љ–Є –Њ —З—С–Љ, —В. –Ї. –≤–њ–Њ–ї–љ–µ —Г–Ї–ї–∞–і—Л–≤–∞–µ—В—Б—П –≤ —А–∞–Љ–Ї–Є –њ–Њ–≥—А–µ—И–љ–Њ—Б—В–Є –Є–Ј–Љ–µ—А–µ–љ–Є–є. –Э–Њ –≤ –љ–∞—И–µ–Љ —Б–ї—Г—З–∞–µ –Њ–љ–Њ –Ї–∞–Ї —А–∞–Ј —Б–Є—Б—В–µ–Љ–∞—В–Є—З–µ—Б–Ї–Њ–µ: +1/+2% –≤—Б—В—А–µ—З–∞–µ—В—Б—П 11 —А–∞–Ј, –∞ −1/−2% вАФ –≤—Б–µ–≥–Њ 2 —А–∞–Ј–∞. –Ґ–∞–Ї–Є–Љ –Њ–±—А–∞–Ј–Њ–Љ, —Б–Є—Б—В–µ–Љ–∞—В–Є—З–љ–Њ—Б—В—М –љ–µ–±–Њ–ї—М—И–Є—Е –≤—Л–Є–≥—А—Л—И–µ–є —А–µ–ґ–Є–Љ–∞ ¬Ђ–њ—А–Є—В–≤–Њ—А—Б—В–≤–∞¬ї –њ—А–Њ—Ж–µ—Б—Б–Њ—А–Њ–Љ Intel Core 2, —Б –Њ–і–љ–Њ–є —Б—В–Њ—А–Њ–љ—Л, –њ–Њ–і—В–≤–µ—А–ґ–і–∞–µ—В –≥–Є–њ–Њ—В–µ–Ј—Г –Њ ¬Ђ–љ–µ—З–µ—Б—В–љ–Њ—Б—В–Є¬ї –Њ–њ—А–µ–і–µ–ї–µ–љ–Є—П –њ–Њ–і–і–µ—А–ґ–Ї–Є –і–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ—Л—Е –љ–∞–±–Њ—А–Њ–≤ –Є–љ—Б—В—А—Г–Ї—Ж–Є–є, —Б –і—А—Г–≥–Њ–є –ґ–µ вАФ –љ–Є–≤–µ–ї–Є—А—Г–µ—В –ї—О–±–Њ–є –≤—А–µ–і –і–Њ —Г—А–Њ–≤–љ—П –љ–µ—Б—Г—Й–µ—Б—В–≤–µ–љ–љ–Њ–≥–Њ.
–І—В–Њ —Б –њ—А–Њ—З–Є–Љ–Є —В–µ—Б—В–∞–Љ–Є? –° —В–Њ—З–Ї–Є –Ј—А–µ–љ–Є—П –њ—А–Њ–≤–µ—А–Ї–Є –≥–Є–њ–Њ—В–µ–Ј—Л –Р–≥–љ–µ—А–∞ –§–Њ–≥–∞, –љ–∞–Є–±–Њ–ї—М—И–µ–≥–Њ –≤–љ–Є–Љ–∞–љ–Є—П –Ј–∞—Б–ї—Г–ґ–Є–≤–∞—О—В —В–µ—Б—В—Л –≤ Lightwave, Apple Lossless, MP3 (LAME), SunSpider/Chrome, Mathematica, MATLAB, x264 –Є XviD. –°–Њ–±–ї—О–і—С–Љ –њ—А–µ–Ј—Г–Љ–њ—Ж–Є—О –љ–µ–≤–Є–љ–Њ–≤–љ–Њ—Б—В–Є ;) –Є –≤—Л–±—А–Њ—Б–Є–Љ –Є–Ј —Н—В–Њ–≥–Њ —Б–њ–Є—Б–Ї–∞ SunSpider/Chrome –Є XviD вАФ –≥–і–µ –µ—Б—В—М 1вАУ2 –њ—А–Њ—Ж–µ–љ—В–∞, —В–∞–Љ –Є–Ј—А–µ–і–Ї–∞ –Є 3 –Љ–Њ–ґ–µ—В –≤—Б—В—А–µ—В–Є—В—М—Б—П, –Љ–∞–ї–Њ –ї–Є –Ї–∞–Ї –±—Л–≤–∞–µ—ВвА¶ –°–ї–Њ–ґ–љ–µ–µ –Њ–±—К—П—Б–љ–Є—В—М, –њ–Њ—З–µ–Љ—Г –њ—А–Є–і—С—В—Б—П –≤—Л–Ї–Є–љ—Г—В—М –Є Apple Lossless —Б MP3 (LAME).
–Ф–µ–ї–Њ –≤ —В–Њ–Љ, —З—В–Њ –љ–∞—И–∞ –Љ–µ—В–Њ–і–Є–Ї–∞, –Ї–∞–Ї –Є –ї—О–±–Њ–є –њ—А–Њ–і—Г–Ї—В, —А–∞–Ј—А–∞–±–∞—В—Л–≤–∞–≤—И–Є–є—Б—П –і–ї—П –Њ–њ—А–µ–і–µ–ї—С–љ–љ—Л—Е —Ж–µ–ї–µ–є, –љ–µ –Љ–Њ–ґ–µ—В –±—Л—В—М –њ–Њ–ї–љ–Њ—Б—В—М—О —Г–љ–Є–≤–µ—А—Б–∞–ї—М–љ–Њ–є. –Т —З–∞—Б—В–љ–Њ—Б—В–Є, –Њ–љ–∞ –љ–µ–≤–∞–ґ–љ–Њ –њ–Њ–і—Е–Њ–і–Є—В –і–ї—П —В–µ—Б—В–Є—А–Њ–≤–∞–љ–Є—П –њ—А–Њ—Ж–µ—Б—Б–Њ—А–Њ–≤ —Б –Њ—З–µ–љ—М –Љ–∞–ї–µ–љ—М–Ї–Њ–є –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М—О. –Ю–і–љ–Њ–є –Є–Ј –њ—А–Є—З–Є–љ —Н—В–Њ–≥–Њ —П–≤–ї—П–µ—В—Б—П –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞–љ–Є–µ –±–µ–љ—З–Љ–∞—А–Ї–∞ dBpoweramp, –≤—Л–і–∞—О—Й–µ–≥–Њ —Ж–µ–ї–Њ—З–Є—Б–ї–µ–љ–љ—Л–µ —А–µ–Ј—Г–ї—М—В–∞—В—Л: –Ї–Њ–≥–і–∞ —А–µ–Ј—Г–ї—М—В–∞—В –Њ—З–µ–љ—М –Љ–∞–ї, —А–∞–Ј–љ–Є—Ж–∞ –Љ–µ–ґ–і—Г –њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞–Љ–Є –≤ –Њ–і–љ—Г –Є–Ј–Љ–µ—А—П–µ–Љ—Г—О –µ–і–Є–љ–Є—Ж—Г –Љ–Њ–ґ–µ—В —Б–Њ—Б—В–∞–≤–ї—П—В—М ¬Ђ–Ј–∞–Љ–µ—В–љ—Л–µ¬ї 5вАУ10% –≤ –Њ—В–љ–Њ—Б–Є—В–µ–ї—М–љ–Њ–Љ –Є—Б—З–Є—Б–ї–µ–љ–Є–Є. –Р –љ–∞ —Б–∞–Љ–Њ–Љ –і–µ–ї–µ, –±—Л—В—М –Љ–Њ–ґ–µ—В, —Н—В–Њ –±—Л–ї–Є –љ–µ 9 –Є 10 –±–∞–ї–ї–Њ–≤, –∞ 9,4 –Є 9,6 вАФ –љ–Њ —Н—В–Њ–≥–Њ –Љ—Л –љ–Є–Ї–Њ–≥–і–∞ –љ–µ —Г–Ј–љ–∞–µ–Љ, –њ–Њ—В–Њ–Љ—Г —З—В–Њ –Њ–Ї—А—Г–≥–ї–µ–љ–Є–µ –њ—А–Њ–Є–Ј–≤–µ–і–µ–љ–Њ –≤–љ—Г—В—А–Є –±–µ–љ—З–Љ–∞—А–Ї–∞.
–Ю—Б—В–∞—О—В—Б—П Lightwave, Mathematica, MATLAB –Є x264. –Ъ–∞–Ј–∞–ї–Њ—Б—М –±—Л, –љ–µ —В–∞–Ї —Г–ґ –Љ–љ–Њ–≥–Њ вАФ –љ–Њ —Б –љ–∞—И–µ–є —В–Њ—З–Ї–Є –Ј—А–µ–љ–Є—П, —Ж–µ–ї—М –≤—Б—С-—В–∞–Ї–Є –і–Њ—Б—В–Є–≥–љ—Г—В–∞: –≤ —Н—В–Є—Е —Б–ї—Г—З–∞—П—Е —А–∞–Ј–љ–Є—Ж—Г –≤ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є –љ–µ –њ—А–µ–і—Б—В–∞–≤–ї—П–µ—В—Б—П –≤–Њ–Ј–Љ–Њ–ґ–љ—Л–Љ –Њ–±—К—П—Б–љ–Є—В—М –±–µ–Ј –њ—А–Є–≤–ї–µ—З–µ–љ–Є—П –≥–Є–њ–Њ—В–µ–Ј—Л –Р–≥–љ–µ—А–∞ –§–Њ–≥–∞. –Я—А–∞–≤–і–∞, –Њ—А–Є–µ–љ—В–∞—Ж–Є—О –љ–∞ —Б–Є–≥–љ–∞—В—Г—А—Л –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—П —А–∞–Ј—А–∞–±–Њ—В—З–Є–Ї–Є MATLAB –Њ—Б–Њ–±–µ–љ–љ–Њ –Є –љ–µ —Б–Ї—А—Л–≤–∞—О—В, –љ–∞ —В–µ–Љ—Г —З–µ–≥–Њ –Љ—Л –і–∞–ґ–µ —Б–і–µ–ї–∞–ї–Є 2 –≥–Њ–і–∞ –љ–∞–Ј–∞–і —Б–њ–µ—Ж–Є–∞–ї—М–љ–Њ–µ –Є—Б—Б–ї–µ–і–Њ–≤–∞–љ–Є–µ, вАФ –љ–Њ –Ї–∞—Б–∞–µ–Љ–Њ –і—А—Г–≥–Є—Е –њ—А–Њ–≥—А–∞–Љ–Љ —В–∞–Ї–∞—П –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—П –љ–∞–Љ –љ–µ –Є–Ј–≤–µ—Б—В–љ–∞. –Ф–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ–Њ –Њ—В–Љ–µ—В–Є–Љ, —З—В–Њ –Ї—А–∞–є–љ–µ –љ–µ—Б—В–∞–±–Є–ї—М–љ–∞—П —А–∞–±–Њ—В–∞ Adobe Photoshop –≤ —А–Њ–і–љ–Њ–Љ —А–µ–ґ–Є–Љ–µ –Є—Б–њ—А–∞–≤–ї–µ–љ–∞ –њ–µ—А–µ—Е–Њ–і–Њ–Љ –≤ ¬Ђ–њ–Њ–і–і–µ–ї—М–љ—Л–є¬ї, —З—В–Њ –≤—Л–≥–ї—П–і–Є—В –Ї—Г–і–∞ –љ–∞–≥–ї—П–і–љ–µ–є –ґ–∞–ї–Ї–Њ–≥–Њ –њ—А–Њ—Ж–µ–љ—В–∞ –њ—А–Є–±–∞–≤–Ї–Є –Ї —Б–Ї–Њ—А–Њ—Б—В–Є. –Р –≤–Њ—В Sony Vegas, –љ–∞–Њ–±–Њ—А–Њ—В, –њ—А–Є–љ—Ж–Є–њ–Є–∞–ї—М–љ–Њ –Њ—В–Ї–∞–Ј–∞–ї—Б—П —А–∞–±–Њ—В–∞—В—М –љ–∞ —Д–∞–ї—М—И–Є–≤–Њ–Љ Core 2.
–Т —Б—Г—Е–Њ–Љ –Њ—Б—В–∞—В–Ї–µ (–Є–Ј 38 —В–µ—Б—В–Њ–≤) –Љ—Л –Є–Љ–µ–µ–Љ 6 —Б–ї—Г—З–∞–µ–≤ —Б—Г—Й–µ—Б—В–≤–µ–љ–љ–Њ–є —А–∞–Ј–љ–Є—Ж—Л –≤ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є –Љ–µ–ґ–і—Г —А–Њ–і–љ—Л–Љ –Є ¬Ђ–Њ–±–Љ–∞–љ–љ—Л–Љ¬ї —А–µ–ґ–Є–Љ–∞–Љ–Є, –њ—А–Є—З—С–Љ –≤ —В—А—С—Е –Є–Ј —И–µ—Б—В–Є ¬Ђ–њ—А–Є—В–≤–Њ—А—Б—В–≤–Њ¬ї –њ—А–Њ—Ж–µ—Б—Б–Њ—А–Њ–Љ Intel –њ—А–Є–≤–µ–ї–Њ –Ї —Г—Б–Ї–Њ—А–µ–љ–Є—О –≤ —Б—А–µ–і–љ–µ–Љ –љ–∞ 15%, –∞ –≤ –і—А—Г–≥–Є—Е —В—А—С—Е вАФ –Ї –Ј–∞–Љ–µ–і–ї–µ–љ–Є—О –≤ —Б—А–µ–і–љ–µ–Љ –љ–∞ 5%. –Т—Л–≤–Њ–і—Л –Є–Ј —Н—В–Њ–≥–Њ –Љ–Њ–ґ–љ–Њ —Б–і–µ–ї–∞—В—М —В–∞–Ї–Є–µ:
- –°–∞–Љ–Њ –љ–∞–ї–Є—З–Є–µ —А–∞–Ј–љ–Є—Ж—Л –≤ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є –Я–Ю –љ–∞ –Њ–і–љ–Њ–Љ –Є —В–Њ–Љ –ґ–µ –¶–Я –њ–Њ—Б–ї–µ –Ј–∞–Љ–µ–љ—Л –µ–≥–Њ CPUID —Б–≤–Є–і–µ—В–µ–ї—М—Б—В–≤—Г–µ—В –Њ —В–Њ–Љ, —З—В–Њ –Ј–∞—П–≤–ї–µ–љ–љ–∞—П –њ—А–Њ–±–ї–µ–Љ–∞ –≤–ї–Є—П–љ–Є—П —Б—В—А–Њ–Ї–Є —Б –Є–Љ–µ–љ–µ–Љ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—П –¶–Я –љ–∞ —Б–Ї–Њ—А–Њ—Б—В—М —Б—Г—Й–µ—Б—В–≤—Г–µ—В. –≠—В–Њ—В —Д–∞–Ї—В –Љ–Њ–ґ–љ–Њ —Б—З–Є—В–∞—В—М –і–Њ–Ї–∞–Ј–∞–љ–љ—Л–Љ.
- –Ю–і–љ–Њ–Ј–љ–∞—З–љ–Њ –Њ—Ж–µ–љ–Є—В—М –і–∞–љ–љ—Г—О –њ—А–Њ–±–ї–µ–Љ—Г –Ї–∞–Ї –њ—А–Є–љ–Њ—Б—П—Й—Г—О –њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞–Љ –љ–µ-Intel –Є—Б–Ї–ї—О—З–Є—В–µ–ї—М–љ–Њ –≤—А–µ–і вАФ –љ–µ –њ–Њ–ї—Г—З–∞–µ—В—Б—П. –Э—Г –∞ –њ–Њ–і–∞–≤–ї—П—О—Й–µ–µ –±–Њ–ї—М—И–Є–љ—Б—В–≤–Њ —В–µ—Б—В–Њ–≤ –љ–∞ —Б–Љ–µ–љ—Г CPUID –ї–Є–±–Њ –≤–Њ–Њ–±—Й–µ –љ–µ –њ—А–Њ—А–µ–∞–≥–Є—А–Њ–≤–∞–ї–Њ, –ї–Є–±–Њ –њ—А–Њ—А–µ–∞–≥–Є—А–Њ–≤–∞–ї–Њ –±–Њ–ї–µ–µ —З–µ–Љ –≤—П–ї–Њ.
- –Ь—Л –љ–µ —Г—В–≤–µ—А–ґ–і–∞–µ–Љ, —З—В–Њ –≤—Б–µ –њ–Њ–і–Њ–Ј—А–Є—В–µ–ї—М–љ—Л–µ –њ—А–Њ–≥—А–∞–Љ–Љ—Л –±—Л–ї–Є —Б–Њ–±—А–∞–љ—Л –Є–Љ–µ–љ–љ–Њ –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–Њ–Љ Intel (—Е–Њ—В—П –Є–Љ–µ–љ–љ–Њ –Њ—В –љ–µ–≥–Њ –Њ–ґ–Є–і–∞—О—В—Б—П –љ–∞–±–ї—О–і–∞–µ–Љ—Л–µ —Н—Д—Д–µ–Ї—В—Л), –∞ –њ—А–Њ—З–Є–µ вАФ –Ї–∞–Ї–Є–Љ–Є-—В–Њ –і—А—Г–≥–Є–Љ–Є. –Э–µ –Є—Б–Ї–ї—О—З–∞–µ–Љ –Љ—Л –Є –≤–Њ–Ј–Љ–Њ–ґ–љ–Њ—Б—В–Є, —З—В–Њ –Є–љ—Б—В—А—Г–Љ–µ–љ—В—Л –і—А—Г–≥–Є—Е —Д–Є—А–Љ –Є–Љ–µ—О—В –њ–Њ—Е–Њ–ґ–Є–µ –љ–µ–і–Њ—Б—В–∞—В–Ї–Є, —В–Њ–ґ–µ –≤–ї–Є—П—О—Й–Є–µ –љ–∞ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М –≥–µ–љ–µ—А–Є—А—Г–µ–Љ—Л—Е –њ—А–Њ–≥—А–∞–Љ–Љ.
–Ю –њ–Њ—Б–ї–µ–і–љ–µ–Љ –Ї–Њ—Б–≤–µ–љ–љ–Њ —Б–≤–Є–і–µ—В–µ–ї—М—Б—В–≤—Г–µ—В –њ—А–Є—Б—Г—В—Б—В–≤–Є–µ –≤ —Б–њ–Є—Б–Ї–µ –Ї–Њ–і–µ–Ї–∞ x264, –Ї–Њ—В–Њ—А—Л–є –Њ—В–љ–Њ—Б–Є—В—Б—П –Ї –Ї–∞—В–µ–≥–Њ—А–Є–Є OSS (open source software), –њ—А–Є—З–µ–Љ —Б–Ї–Њ–Љ–њ–Є–ї–Є—А–Њ–≤–∞–љ –њ—А–Є –њ–Њ–Љ–Њ—Й–Є OSS-–Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–∞ –Є —В–∞–Ї–Є—Е –ґ–µ –±–Є–±–ї–Є–Њ—В–µ–Ї вАФ —В. –µ. –љ–Є–Ї–∞–Ї–Њ–≥–Њ –Є–љ—Б—В—А—Г–Љ–µ–љ—В–∞—А–Є—П Intel –≤ –і–∞–љ–љ–Њ–Љ —Б–ї—Г—З–∞–µ, –њ–Њ –Є–і–µ–µ, –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М—Б—П –љ–µ –Љ–Њ–≥–ї–Њ, –∞ –≤–Њ—В –≤—Л–Є–≥—А—Л—И –Њ—В –њ–Њ–і–Љ–µ–љ—Л CPUID –љ–∞ –Є–љ—В–µ–ї–Њ–≤—Б–Ї–Є–є –і–Њ–≤–Њ–ї—М–љ–Њ —Б—Г—Й–µ—Б—В–≤–µ–љ–љ—Л–є.
–Х—Б–ї–Є –Є–Ј–ї–Њ–ґ–Є—В—М –≤—Л—И–µ—Б–Ї–∞–Ј–∞–љ–љ–Њ–µ –≤ –і–≤—Г—Е —Б–ї–Њ–≤–∞—Е, —В–Њ, –і–∞ –њ—А–Њ—Б—В–Є—В –љ–∞—Б –°–Љ–µ–ї—Л–є –†—Л—Ж–∞—А—М, –љ–∞—И –≤–µ—А–і–Є–Ї—В –±—Г–і–µ—В —В–∞–Ї–Њ–≤: –њ—А–Њ–±–ї–µ–Љ–∞ —Б—Г—Й–µ—Б—В–≤—Г–µ—В, –љ–Њ –њ–µ—А–µ–Њ—Ж–µ–љ–Є–≤–∞—В—М –µ—С –≤–ї–Є—П–љ–Є–µ –љ–∞ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М —А–µ–∞–ї—М–љ–Њ–≥–Њ –Я–Ю –љ–µ —Б—В–Њ–Є—В.–Э–Њ —А–∞–Ј —Г –љ–∞—Б –µ—Б—В—М —А–µ–Ј—Г–ї—М—В–∞—В—Л VIA NanoвА¶
вА¶–Ґ–Њ –њ–Њ—З–µ–Љ—Г –±—Л –љ–µ –њ–Њ–њ—Л—В–∞—В—М—Б—П —Б–Њ—Б—В–∞–≤–Є—В—М –Њ–±—Й–µ–µ –≤–њ–µ—З–∞—В–ї–µ–љ–Є–µ –Њ –µ–≥–Њ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є? –†–∞–Ј—Г–Љ–µ–µ—В—Б—П, —Б—А–∞–≤–љ–Є–≤–∞—В—М —Н—В–Њ—В –њ—А–Њ—Ж–µ—Б—Б–Њ—А –љ—Г–ґ–љ–Њ –≤ –њ–µ—А–≤—Г—О –Њ—З–µ—А–µ–і—М —Б Intel Atom, –љ–Њ —А–µ–Ј—Г–ї—М—В–∞—В–Њ–≤ –µ–≥–Њ —В–µ—Б—В–Є—А–Њ–≤–∞–љ–Є—П —Г –љ–∞—Б –µ—Й—С –љ–µ—В. –Р –µ—Б—В—М, –љ–∞–њ—А–Є–Љ–µ—А, —А–µ–Ј—Г–ї—М—В–∞—В—Л AMD Sempron 140. –Р —З—В–Њ? –Ъ–∞–Ї –Є Nano, –Њ–љ –Њ–і–љ–Њ—П–і–µ—А–љ—Л–є, —Б –∞–љ–∞–ї–Њ–≥–Є—З–љ—Л–Љ —Г—Б—В—А–Њ–є—Б—В–≤–Њ–Љ –Є –Њ–±—К—С–Љ–∞–Љ–Є –Ї—Н—И–µ–є, –Њ—Б–љ–Њ–≤–∞–љ –љ–∞ —Б–Њ–≤—А–µ–Љ–µ–љ–љ–Њ–Љ OoO-—П–і—А–µ K10 —Б 3-–њ—Г—В–љ—Л–Љ —Б—Г–њ–µ—А—Б–Ї–∞–ї—П—А–Њ–Љ –Є –њ–Њ–ї–љ–Њ–Ї–Њ–љ–≤–µ–є–µ—А–љ—Л–Љ–Є –§–£. –Я–Њ—З–µ–Љ—Г –±—Л –љ–µ —Б—А–∞–≤–љ–Є—В—М? –Я—А–∞–≤–і–∞, —Г Sempron 140 —Б—Г—Й–µ—Б—В–≤–µ–љ–љ–Њ –±–Њ́–ї—М—И–∞—П —И—В–∞—В–љ–∞—П —З–∞—Б—В–Њ—В–∞ (2,7 –У–У—Ж), –љ–Њ –Љ—Л –≤–µ–і—М —Б—А–∞–≤–љ–Є–≤–∞–µ–Љ ¬Ђ–њ—А–Є–Ї–Є–і–Њ—З–љ–Њ¬ї. –Т–њ–Њ–ї–љ–µ –њ–Њ–і–Њ–є–і—С—В –њ—А–Њ—Б—В–∞—П —Н–Ї—Б—В—А–∞–њ–Њ–ї—П—Ж–Є—П, –њ—А–µ–і–њ–Њ–ї–∞–≥–∞—О—Й–∞—П, —З—В–Њ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В—М Sempron –ї–Є–љ–µ–є–љ–Њ —Г–Љ–µ–љ—М—И–∞–µ—В—Б—П –њ—А–Њ–њ–Њ—А—Ж–Є–Њ–љ–∞–ї—М–љ–Њ —З–∞—Б—В–Њ—В–µ. –£—З–Є—В—Л–≤–∞—П, —З—В–Њ –µ–≥–Њ —И—В–∞—В–љ–∞—П —З–∞—Б—В–Њ—В–∞ –Є —В–∞–Ї –љ–µ –Њ—З–µ–љ—М –≤–µ–ї–Є–Ї–∞ (–њ—А–Є–Љ–µ–љ–Є—В–µ–ї—М–љ–Њ –Ї –≥—А–∞–љ–Є—Ж–∞–Љ, —Г–ґ–µ –і–Њ—Б—В–Є–≥–љ—Г—В—Л–Љ —П–і—А–Њ–Љ K10), –∞ —В–∞–Ї–ґ–µ —В–Њ, —З—В–Њ —Н–Ї—Б—В—А–∞–њ–Њ–ї—П—Ж–Є—П –Є–і—С—В –≤ —Б—В–Њ—А–Њ–љ—Г —Г–Љ–µ–љ—М—И–µ–љ–Є—П (–њ–Њ—Н—В–Њ–Љ—Г, –љ–∞–њ—А–Є–Љ–µ—А, 2-–Ї–∞–љ–∞–ї—М–љ—Л–є –Ш–Ъ–Я –≤–Ј–∞–Љ–µ–љ —З–Є–њ—Б–µ—В–љ–Њ–≥–Њ –≤—А–Њ–і–µ –±—Л –љ–Є—З–µ–≥–Њ –љ–µ –і–∞—Б—В) вАФ –њ—А–µ–і–њ–Њ–ї–∞–≥–∞–µ–Љ—Л–µ –Ј–љ–∞—З–µ–љ–Є—П, —В–µ–Њ—А–µ—В–Є—З–µ—Б–Ї–Є, –і–Њ–ї–ґ–љ—Л –±—Л—В—М –≤–µ—Б—М–Љ–∞ –±–ї–Є–Ј–Ї–Є –Ї –Є—Б—В–Є–љ–µ.
–Ш —З—В–Њ —Г –љ–∞—Б –њ–Њ–ї—Г—З–Є–ї–Њ—Б—М?
| –Ґ–µ—Б—В | VIA Nano 1,6 –У–У—Ж (Native) | AMD Sempron 140 (–њ–µ—А–µ—Б—З—С—В –љ–∞ 1,6 –У–У—Ж) | Δ% |
| Java | 10,55 | 15,9 | 51% |
| –Р—А—Е–Є–≤–∞—Ж–Є—П: 7-Zip | 0:18:25 | 0:11:40 | 58% |
| –Р—А—Е–Є–≤–∞—Ж–Є—П: WinRAR | 0:08:09 | 0:05:20 | 53% |
| –Р—А—Е–Є–≤–∞—Ж–Є—П: —А–∞—Б–њ–∞–Ї–Њ–≤–Ї–∞ | 0:02:23 | 0:01:51 | 29% |
| –Р—Г–і–Є–Њ: Apple Lossless | 20 | 26 | 30% |
| –Р—Г–і–Є–Њ: FLAC | 25 | 31 | 24% |
| –Р—Г–і–Є–Њ: Monkey's Audio | 19 | 23 | 21% |
| –Р—Г–і–Є–Њ: MP3 (LAME) | 9 | 14 | 56% |
| –Р—Г–і–Є–Њ: Nero AAC | 10 | 13 | 30% |
| –Р—Г–і–Є–Њ: OGG Vorbis | 7 | 9 | 29% |
| –С—А–∞—Г–Ј–µ—А: SunSpider/Chrome | 1357 | 959 | 42% |
| –С—А–∞—Г–Ј–µ—А: SunSpider/Firefox | 2259 | 1612 | 40% |
| –С—А–∞—Г–Ј–µ—А: SunSpider/IE | 14875 | 8884 | 67% |
| –С—А–∞—Г–Ј–µ—А: SunSpider/Opera | 863 | 962 | −10% |
| –С—А–∞—Г–Ј–µ—А: SunSpider/Safari | 1245 | 1498 | −17% |
| –Т–Є–і–µ–Њ: DivX | 0:18:51 | 0:12:52 | 47% |
| –Т–Є–і–µ–Њ: Mainconcept | 0:56:32 | 0:36:40 | 54% |
| –Т–Є–і–µ–Њ: Premiere | 1:04:31 | 0:33:32 | 92% |
| –Т–Є–і–µ–Њ: x264 | 1:58:46 | 1:00:42 | 96% |
| –Т–Є–і–µ–Њ: XviD | 0:17:43 | 0:11:27 | 55% |
| –Т–Є–Ј—Г–∞–ї–Є–Ј–∞—Ж–Є—П: Lightwave | 75,56 | 40,46 | 87% |
| –Т–Є–Ј—Г–∞–ї–Є–Ј–∞—Ж–Є—П: UGS NX 6 | 0,74 | 1,27 | 72% |
| –У—А–∞—Д–Є–Ї–∞: ACDSee | 0:21:59 | 0:14:08 | 55% |
| –У—А–∞—Д–Є–Ї–∞: PaintShop | 0:38:01 | 0:23:16 | 63% |
| –У—А–∞—Д–Є–Ї–∞: PhotoImpact | 0:33:10 | 0:16:20 | 103% |
| –У—А–∞—Д–Є–Ї–∞: Photoshop | 0:31:47 | 0:17:30 | 82% |
| –Ш–≥—А—Л: Borderlands | 11 | 19,6 | 78% |
| –Ш–≥—А—Л: Far Cry 2 | 5,6 | 9,2 | 64% |
| –Ш–≥—А—Л: Fritz Chess | 740 | 950 | 28% |
| –Ш–≥—А—Л: Resident Evil 5 | 18,2 | 31,4 | 73% |
| –Ъ–Њ–Љ–њ–Є–ї—П—Ж–Є—П | 0:52:52 | 0:33:01 | 60% |
| –†–∞—Б—З—С—В—Л: MAPLE | 0,1211 | 0,1741 | 44% |
| –†–∞—Б—З—С—В—Л: Mathematica (int) | 0,804 | 1,695 | 111% |
| –†–∞—Б—З—С—В—Л: Mathematica (MMA) | 0,5269 | 0,7766 | 47% |
| –†–∞—Б—З—С—В—Л: MATLAB | 0,3421 | 0,1664 | 106% |
| –†–∞—Б—З—С—В—Л: UGS NX 6 | 1,47 | 2,63 | 79% |
| –†–µ–љ–і–µ—А–Є–љ–≥: 3ds max | 4:17:04 | 0:47:53 | 437% |
| –†–µ–љ–і–µ—А–Є–љ–≥: Lightwave | 1370,05 | 878,93 | 56% |
–Ф–∞–ґ–µ –µ—Б–ї–Є —Г–±—А–∞—В—М –Њ—В–Ї—А–Њ–≤–µ–љ–љ–Њ –њ—А–Њ–≤–∞–ї—М–љ—Л–є —А–µ–Ј—Г–ї—М—В–∞—В Nano –і–ї—П —А–µ–љ–і–µ—А–Є–љ–≥–∞ –≤ 3ds max + V-Ray, —В–Њ –≤ —Б—А–µ–і–љ–µ–Љ –≤–Є—А—В—Г–∞–ї—М–љ—Л–є –Њ–і–љ–Њ—З–∞—Б—В–Њ—В–љ—Л–є Sempron –±—Л—Б—В—А–µ–µ –љ–∞ 55%. –≠—Д—Д–µ–Ї—В–Є–≤–љ–Њ—Б—В—М –љ–∞ –≤–∞—В—В –њ–Њ–Ї–∞ –Љ—Л —Б—А–∞–≤–љ–Є—В—М –љ–µ –Љ–Њ–ґ–µ–Љ, –љ–Њ –љ–∞ –Ї–∞–ґ–і—Л–є –њ–Њ—В—А–∞—З–µ–љ–љ—Л–є —В—А–∞–љ–Ј–Є—Б—В–Њ—А вАФ –≤–њ–Њ–ї–љ–µ. –Т Nano –Є—Е 94 –Љ–ї–љ., –∞ –≤ Sempron (–љ–∞ —П–і—А–µ K10) вАФ 234 –Љ–ї–љ., –љ–Њ –µ—Б–ї–Є –≤—Б–њ–Њ–Љ–љ–Є—В—М, —З—В–Њ –њ–Њ—Б–ї–µ–і–љ–Є–є —Б—Г—В—М 2-—П–і–µ—А–љ—Л–є Athlon II X2 —Б –Њ–і–љ–Є–Љ –Њ—В–Ї–ї—О—З–µ–љ–љ—Л–Љ —П–і—А–Њ–Љ (–Ї–Њ—В–Њ—А–Њ–µ –Є–љ–Њ–≥–і–∞ –Љ–Њ–ґ–љ–Њ –Є —А–∞–Ј–±–ї–Њ–Ї–Є—А–Њ–≤–∞—В—М), —В–Њ –њ–Њ –њ—А–Є–±–ї–Є–Ј–Є—В–µ–ї—М–љ–Њ–Љ—Г –њ–Њ–і—Б—З—С—В—Г —З–Є—Б–ї–∞ —В—А–∞–љ–Ј–Є—Б—В–Њ—А–Њ–≤ –≤ –Ї—Н—И–∞—Е –Є —П–і—А–µ K10 –њ–Њ–ї—Г—З–∞–µ—В—Б—П, —З—В–Њ –µ—Б–ї–Є –±—Л –љ–∞ —З–Є–њ–µ —Д–Є–Ј–Є—З–µ—Б–Ї–Є –±—Л–ї–Њ —В–Њ–ї—М–Ї–Њ –Њ–і–љ–Њ —П–і—А–Њ, —В–Њ –Њ—Б—В–∞–ї–Њ—Б—М –±—Л 130 –Љ–ї–љ. —В—А–∞–љ–Ј–Є—Б—В–Њ—А–Њ–≤ (–≤–Ї–ї—О—З–∞—П –Њ—В—Б—Г—В—Б—В–≤—Г—О—Й–Є–є —Г Nano 2-–Ї–∞–љ–∞–ї—М–љ—Л–є –Ш–Ъ–Я, —Б–ї–Њ–ґ–љ–Њ—Б—В—М –Ї–Њ—В–Њ—А–Њ–≥–Њ –Љ—Л –Њ—Ж–µ–љ–Є–Љ –Ї–∞–Ї –љ–µ–Ј–љ–∞—З–Є—В–µ–ї—М–љ—Г—О). –Ґ. –µ. –±–Њ–ї—М—И–µ–µ –љ–∞ 38% —З–Є—Б–ї–Њ —В—А–∞–љ–Ј–Є—Б—В–Њ—А–Њ–≤ –і–∞–ї–Њ Sempron –њ—А–µ–≤–Њ—Б—Е–Њ–і—Б—В–≤–Њ –≤ —Б–Ї–Њ—А–Њ—Б—В–Є –≤ 55%.
–Х—Б–ї–Є —А–µ–Ј—Г–ї—М—В–∞—В—Л –≥—А—Г–±–Њ–є –њ—А–Є–Ї–Є–і–Ї–Є –љ–µ –Њ—З–µ–љ—М –і–∞–ї–µ–Ї–Є –Њ—В —А–µ–∞–ї—М–љ–Њ—Б—В–Є, —В–Њ –Ъ–Я–Ф —А–∞—Б—Е–Њ–і–∞ —В—А–∞–љ–Ј–Є—Б—В–Њ—А–љ–Њ–≥–Њ –±—О–і–ґ–µ—В–∞ –ї–Є—И—М –њ–Њ–і—З—С—А–Ї–Є–≤–∞–µ—В –љ–∞—И–Є —А–µ–Ї–Њ–Љ–µ–љ–і–∞—Ж–Є–Є, –і–∞–љ–љ—Л–µ –≤ —В–µ–Њ—А–µ—В–Є—З–µ—Б–Ї–Њ–Љ –Њ–±–Ј–Њ—А–µ –Љ–Є–Ї—А–Њ–∞—А—Е–Є—В–µ–Ї—В—Г—А—Л VIA Isaah. –Э–Њ —В. –Ї. –љ–Є—З–µ–≥–Њ –Є–і–µ–∞–ї—М–љ–Њ–≥–Њ –≤ –Љ–Є—А–µ –љ–µ—В, —В–Њ –Ї–∞–Ї —В–Њ–ї—М–Ї–Њ –љ–∞–Љ —Г–і–∞—Б—В—Б—П –≤ –∞–љ–∞–ї–Њ–≥–Є—З–љ—Л—Е —Г—Б–ї–Њ–≤–Є—П—Е –њ—А–Њ—В–µ—Б—В–Є—А–Њ–≤–∞—В—М Intel Atom (—Б–Њ —Б–≤–Њ–Є–Љ–Є –Њ—Б–Њ–±–µ–љ–љ–Њ—Б—В—П–Љ–Є), –Љ—Л –Њ–±—П–Ј–∞—В–µ–ї—М–љ–Њ –≤–µ—А–љ—С–Љ—Б—П –Ї —В–µ–Љ–µ –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—М–љ–Њ—Б—В–Є VIA Nano.
–Э–∞ –њ—А–Њ—И–ї–Њ–є –љ–µ–і–µ–ї–µ –њ—А–Є—И–ї–∞ –љ–Њ–≤–Њ—Б—В—М –Њ —В–Њ–Љ, —З—В–Њ FTC –Є Intel –Ј–∞–Ї–ї—О—З–Є–ї–Є —Б–Њ–≥–ї–∞—И–µ–љ–Є–µ: FTC, –і–∞–ґ–µ –Є–Љ–µ—П –і–Њ–Ї–∞–Ј–∞—В–µ–ї—М—Б—В–≤–∞ –≤ –≤–Є–і–µ ¬Ђ–љ–µ—В–Њ—З–љ—Л—Е¬ї —А–µ–Ј—Г–ї—М—В–∞—В–Њ–≤ —В–µ—Б—В–Њ–≤ —В–Є–њ–∞ PCMark 2005, –љ–µ –±—Г–і–µ—В –љ–∞–Ї–ї–∞–і—Л–≤–∞—В—М —И—В—А–∞—Д–љ—Л–µ —Б–∞–љ–Ї—Ж–Є–Є, –∞ –Ј–∞ —Н—В–Њ Intel –Њ–±–µ—Й–∞–µ—В (–Њ–њ—П—В—МвА¶):
- —Б–Њ–Њ–±—Й–Є—В—М –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—П–Љ –Я–Ю, —З—В–Њ –µ—С –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А—Л —А–∞–Ј–ї–Є—З–∞—О—В –¶–Я Intel –Є –љ–µ-Intel –Є –љ–µ –≤—Б–µ–≥–і–∞ –≤—Л–і–∞—О—В –і–ї—П –њ–Њ—Б–ї–µ–і–љ–Є—Е –Њ–њ—В–Є–Љ–∞–ї—М–љ—Л–є –Ї–Њ–і, вАФ –Є –≤–Њ–Ј–Љ–µ—Б—В–Є—В—М –і–Њ–њ–Њ–ї–љ–Є—В–µ–ї—М–љ—Л–є —А–∞—Б—Е–Њ–і –ї—О–±–Њ–Љ—Г –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—О –Я–Ю, –Ї–Њ—В–Њ—А—Л–є –њ–Њ —Н—В–Њ–є –њ—А–Є—З–Є–љ–µ –Ј–∞—Е–Њ—З–µ—В –њ–µ—А–µ–і–µ–ї–∞—В—М —Б–≤–Њ—О –њ—А–Њ–≥—А–∞–Љ–Љ—Г –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–Њ–Љ –љ–µ –Њ—В Intel (–њ—А–Є —В–Њ–Љ, —З—В–Њ –±–Є–±–ї–Є–Њ—В–µ–Ї–Є Intel, –Є—Б–њ—А–∞–≤–ї—П—В—М –Ї–Њ—В–Њ—А—Л–µ —Б–Њ–≥–ї–∞—И–µ–љ–Є–µ –љ–µ —В—А–µ–±—Г–µ—В, –Љ–Њ–ґ–љ–Њ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –Є —Б –љ–µ-–Є–љ—В–µ–ї–Њ–≤—Б–Ї–Є–Љ–Є –Ї–Њ–Љ–њ–Є–ї—П—В–Њ—А–∞–Љ–Є);
- –љ–µ –Є—Б–њ–Њ–ї—М–Ј–Њ–≤–∞—В—М –њ–Њ–і–Ї—Г–њ—Л, —Г–≥—А–Њ–Ј—Л –Є —В. –њ. —Б—В–Є–Љ—Г–ї—Л –і–ї—П –Ј–∞–Ї–ї—О—З–µ–љ–Є—П —Н–Ї—Б–Ї–ї—О–Ј–Є–≤–љ—Л—Е –і–Њ–≥–Њ–≤–Њ—А–Њ–≤ —Б –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї—П–Љ–Є –Я–Ъ –≤ –Њ–±–Љ–µ–љ –љ–∞ –Є—Е —Б–Њ–≥–ї–∞—Б–Є–µ –љ–µ –њ–Њ–Ї—Г–њ–∞—В—М –¶–Я –Ї–Њ–љ–Ї—Г—А–µ–љ—В–Њ–≤;
- –Ї–∞–Ї –Љ–Є–љ–Є–Љ—Г–Љ 6 –ї–µ—В –њ–Њ–і–і–µ—А–ґ–Є–≤–∞—В—М —И–Є–љ—Г PCI Express –і–∞–ґ–µ —З–Є–њ—Б–µ—В–∞–Љ–Є –Є–ї–Є –њ—А–Њ—Ж–µ—Б—Б–Њ—А–∞–Љ–Є —Б–Њ –≤—Б—В—А–Њ–µ–љ–љ–Њ–є –≥—А–∞—Д–Є–Ї–Њ–є, —З—В–Њ–±—Л –Љ–Њ–ґ–љ–Њ –±—Л–ї–Њ –њ–Њ–і–Ї–ї—О—З–Є—В—М GPU —Б—В–Њ—А–Њ–љ–љ–Є—Е –њ—А–Њ–Є–Ј–≤–Њ–і–Є—В–µ–ї–µ–є;
- –Є–Ј–Љ–µ–љ–Є—В—М —Г—Б–ї–Њ–≤–Є—П –ї–Є—Ж–µ–љ–Ј–Є–є —В–∞–Ї, —З—В–Њ–±—Л –њ—А–µ–і–Њ—Б—В–∞–≤–Є—В—М –±ó–ї—М—И—Г—О —Б–≤–Њ–±–Њ–і—Г –Ї–Њ–љ–Ї—Г—А–µ–љ—В–∞–Љ –і–ї—П —Б–Њ—В—А—Г–і–љ–Є—З–µ—Б—В–≤–∞ –Є —Б–Њ–≤–Љ–µ—Б—В–љ–Њ–≥–Њ —А–∞–Ј–≤–Є—В–Є—П —В–µ—Е–љ–Њ–ї–Њ–≥–Є–є;
- –њ—А–Њ–і–ї–Є—В—М –ї–Є—Ж–µ–љ–Ј–Є–Њ–љ–љ–Њ–µ —Б–Њ–≥–ї–∞—И–µ–љ–Є–µ —Б VIA Technologies –і–ї—П –≤—Л–њ—Г—Б–Ї–∞ –¶–Я –∞—А—Е–Є—В–µ–Ї—В—Г—А—Л x86 –µ—Й—С –љ–∞ 5 –ї–µ—В вАФ –і–Њ 2018 –≥.
–Я–Њ–±–µ–і–∞?вА¶
–Ј–∞ –њ—А–µ–і–Њ—Б—В–∞–≤–ї–µ–љ–љ—Г—О –Є–љ—Д–Њ—А–Љ–∞—Ж–Є—О, –њ–ї–∞—В—Г –Є –њ—А–Њ–≥—А–∞–Љ–Љ—Г,
–∞ —В–∞–Ї–ґ–µ –Р–ї–µ–Ї—Б–µ—П –Р–Ъ–Р MoroseTroll,
–Ї–Њ—В–Њ—А—Л–є –њ–Њ–і–љ—П–ї —В–µ–Љ—Г, –њ–Њ–і–і–µ—А–ґ–Є–≤–∞–ї –µ—С —А–∞–Ј–≤–Є—В–Є–µ
–Є –Њ–Ї–∞–Ј—Л–≤–∞–ї —В–µ—Е–љ–Є—З–µ—Б–Ї–Є–µ –Ї–Њ–љ—Б—Г–ї—М—В–∞—Ж–Є–Є.
